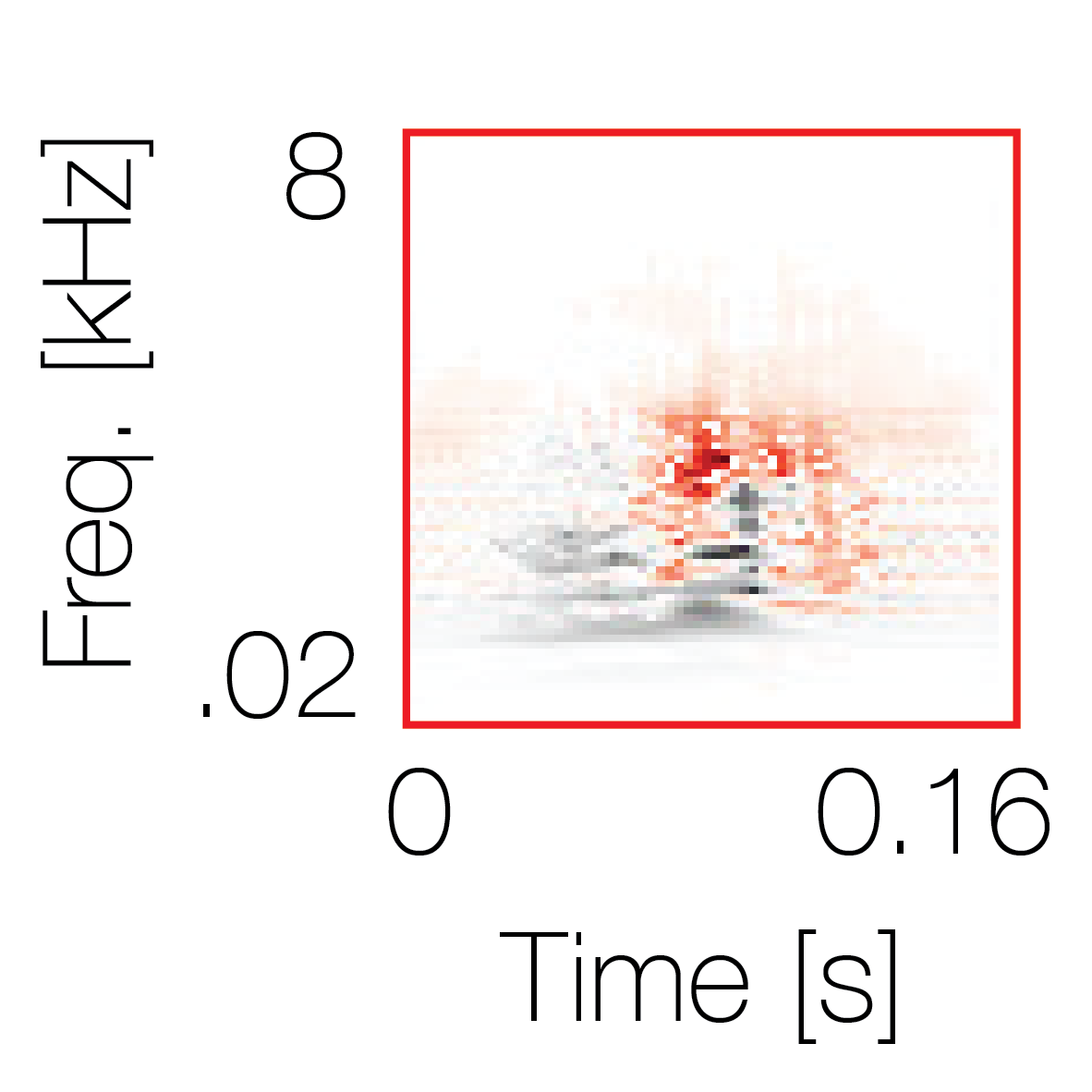
 Spectrotemporal cue 1
Spectrotemporal cue 1 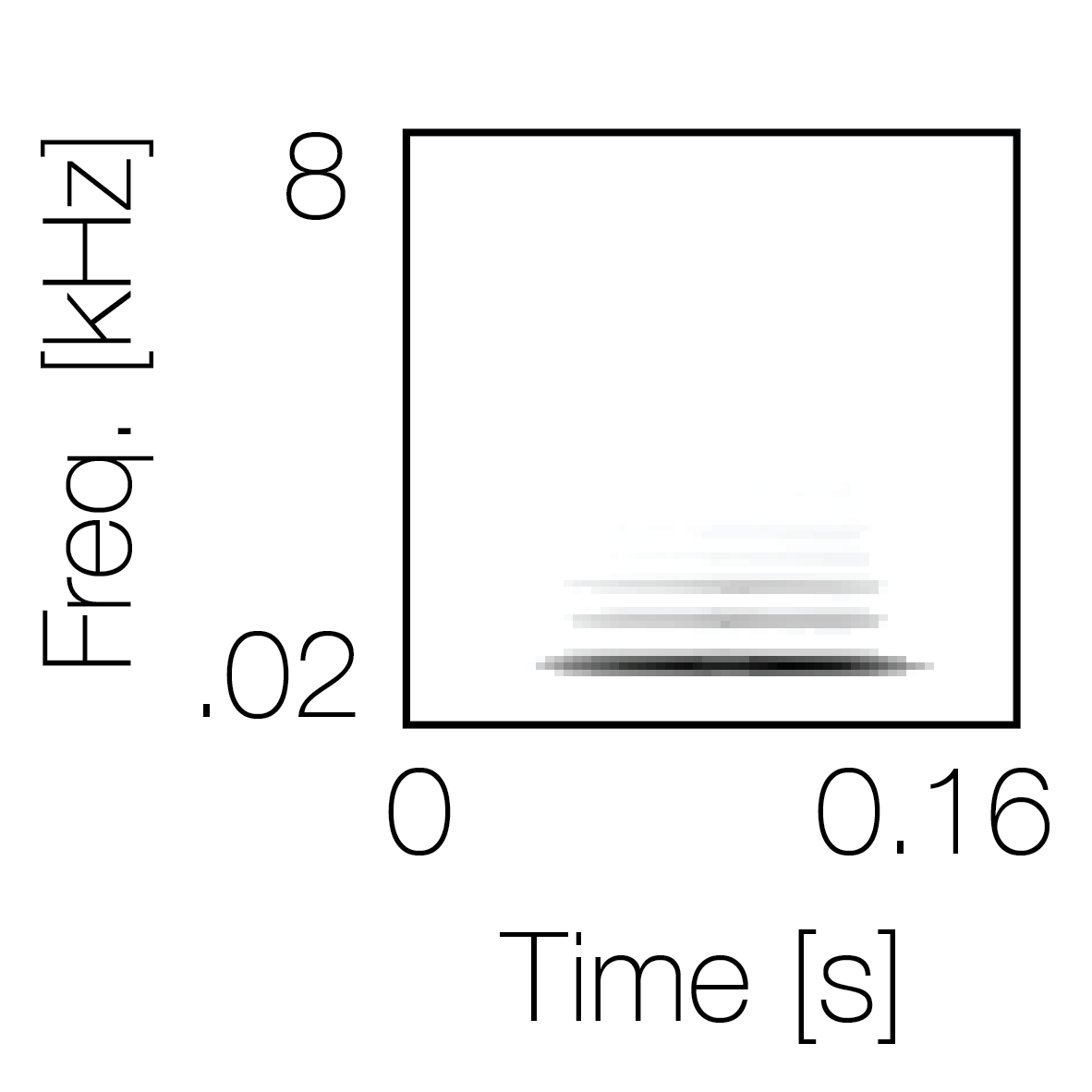
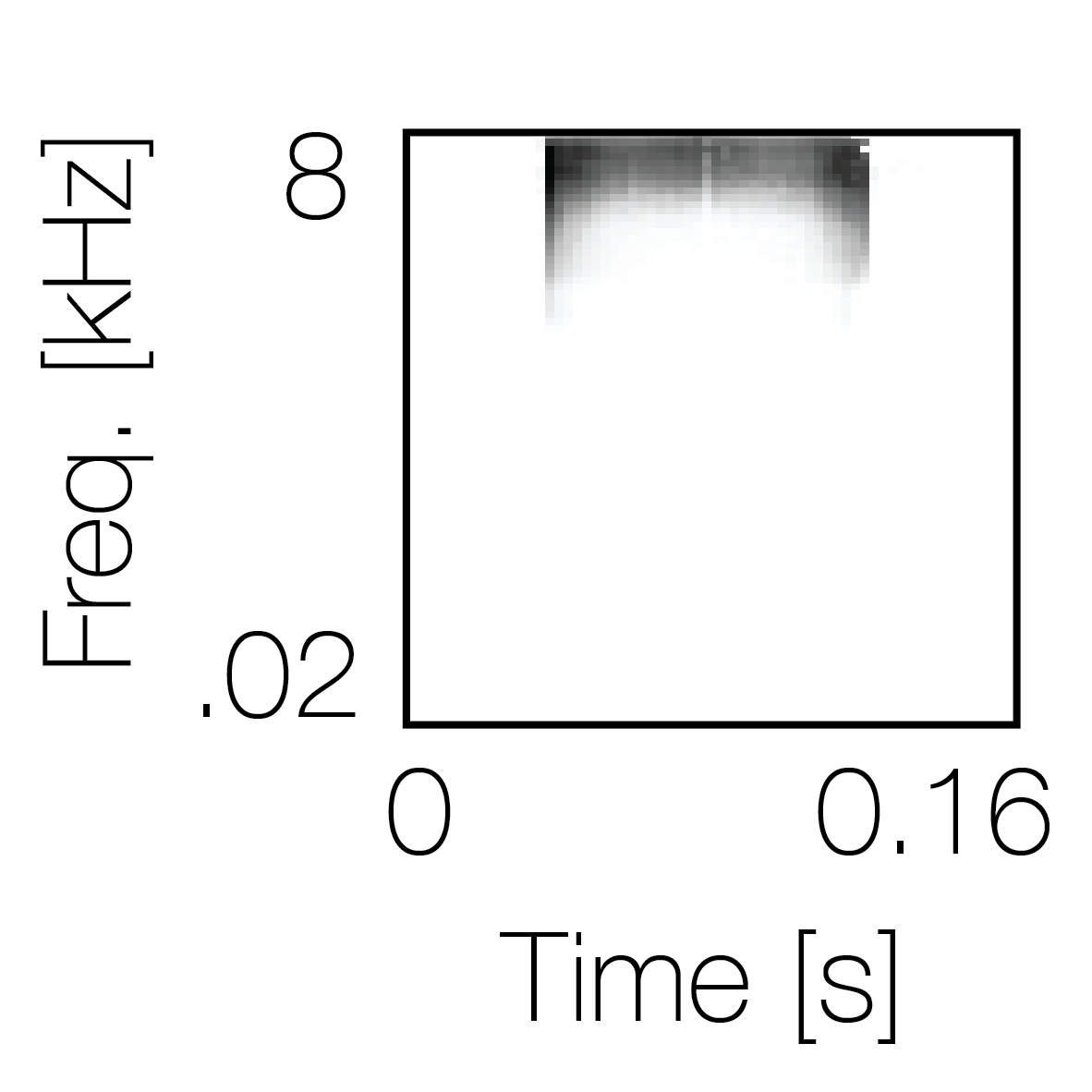

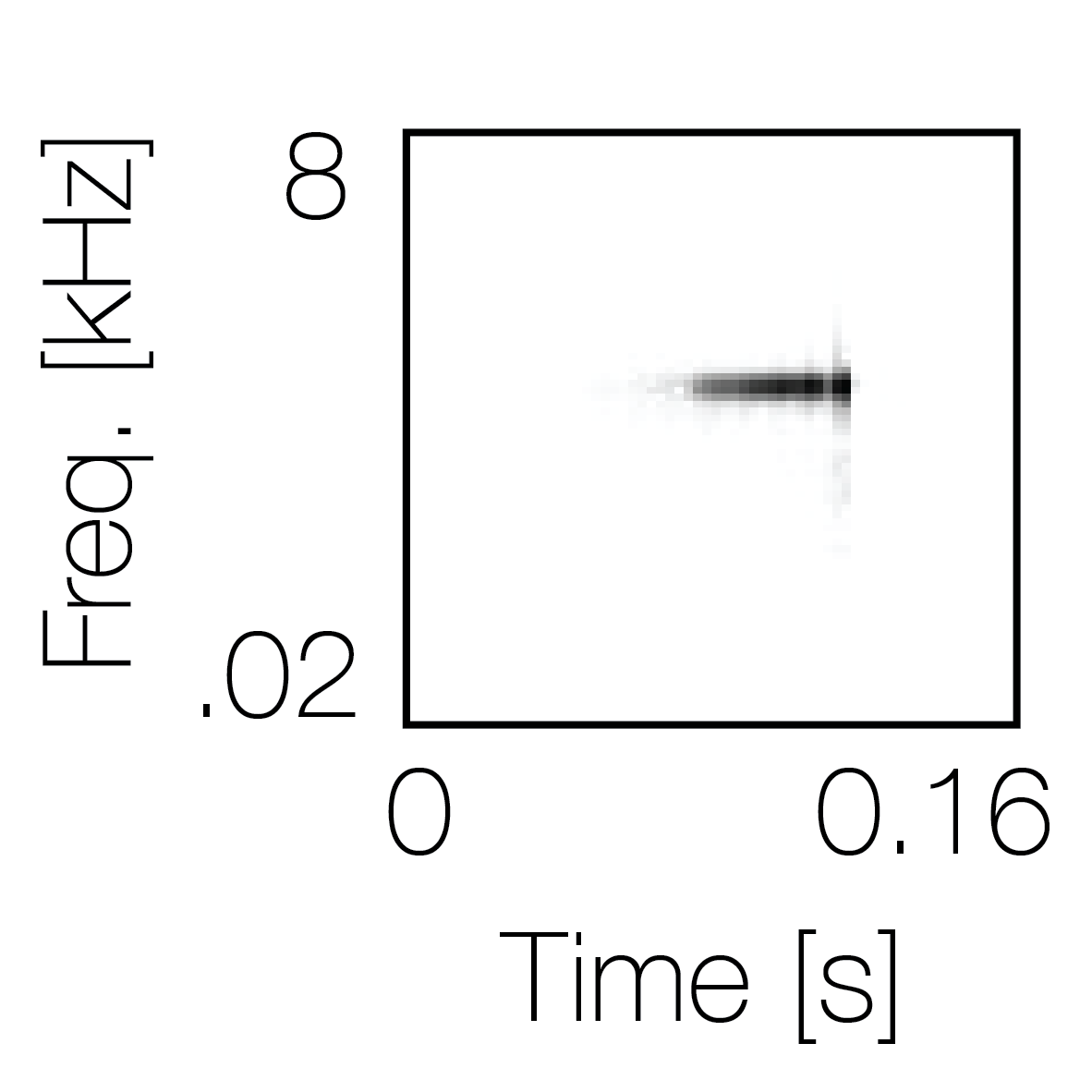
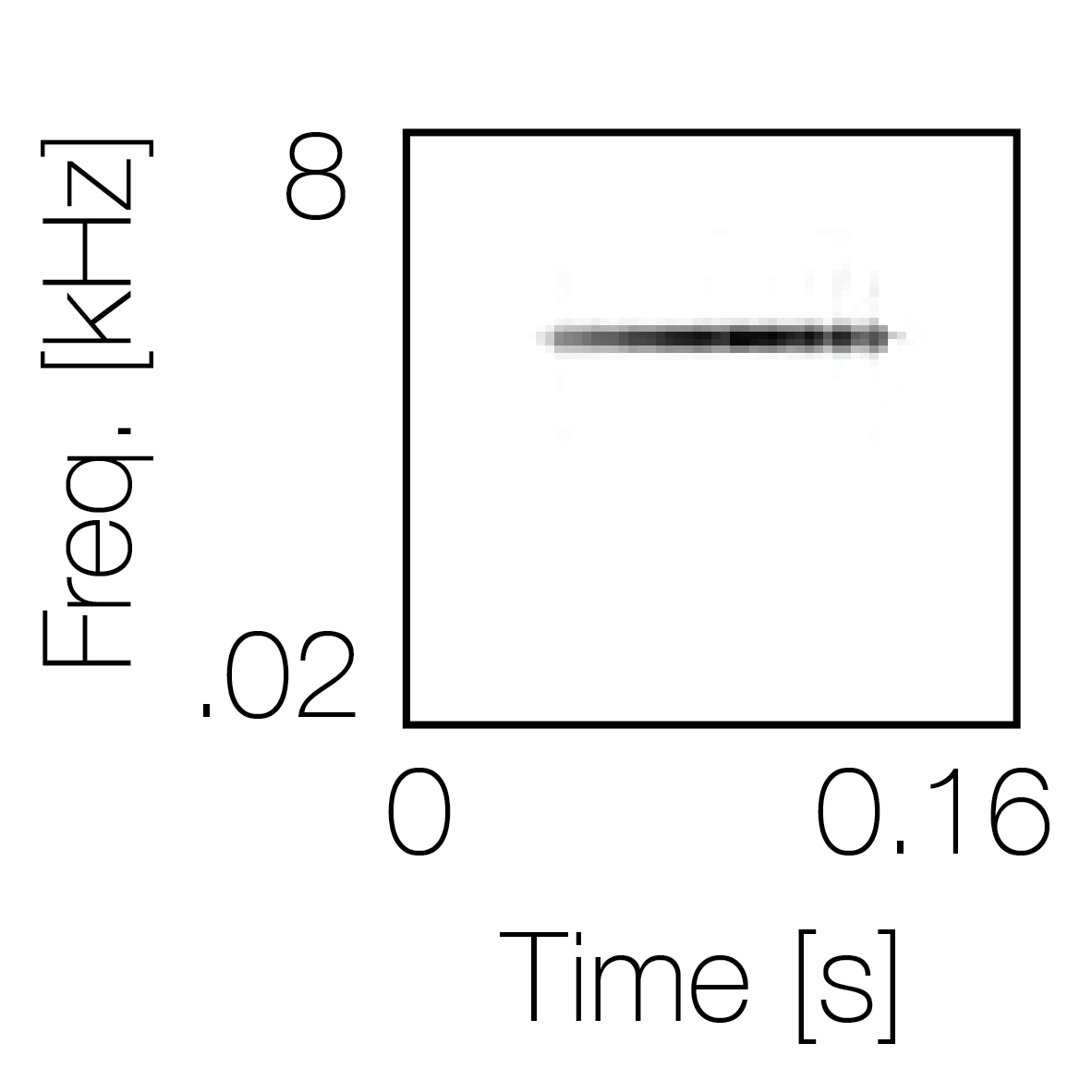
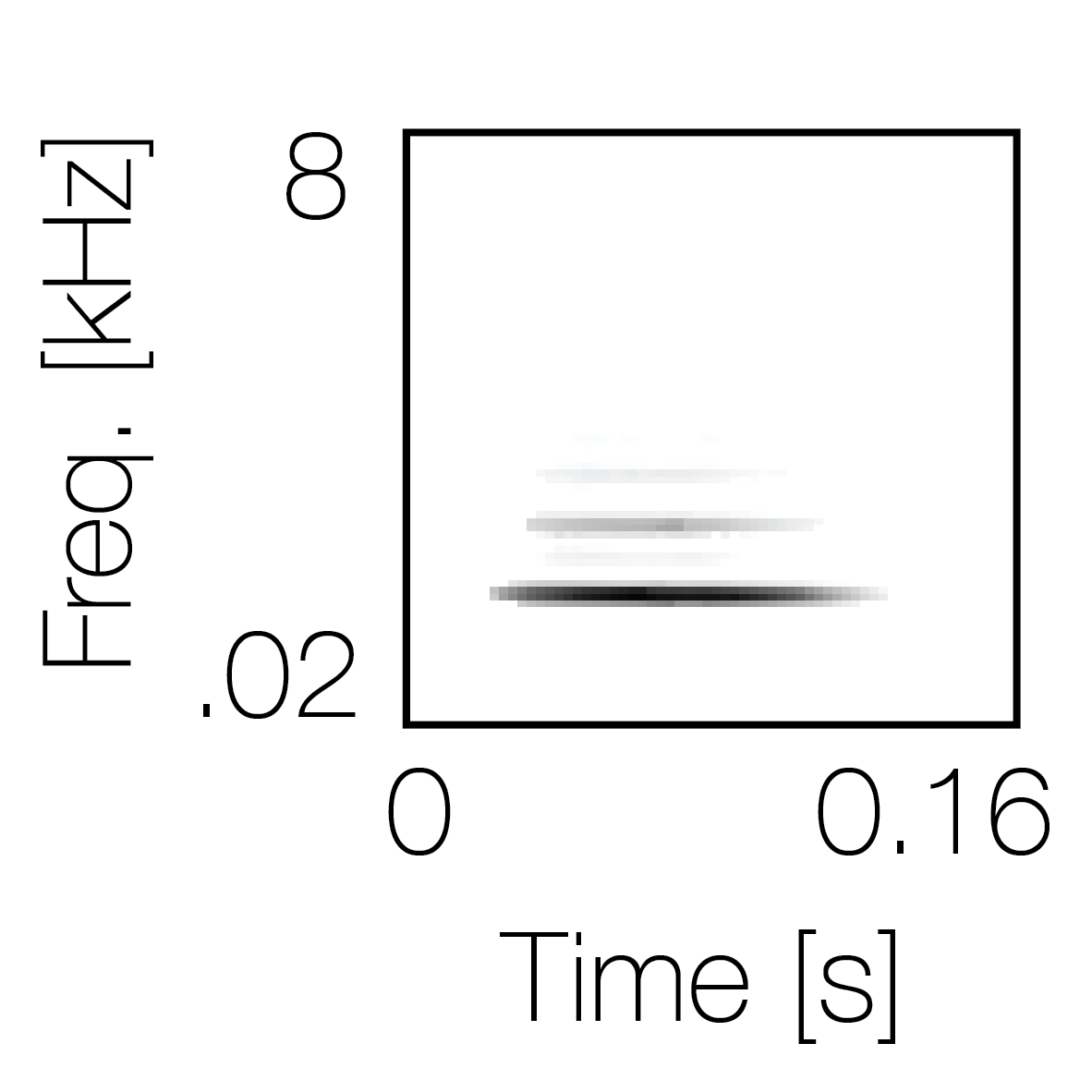
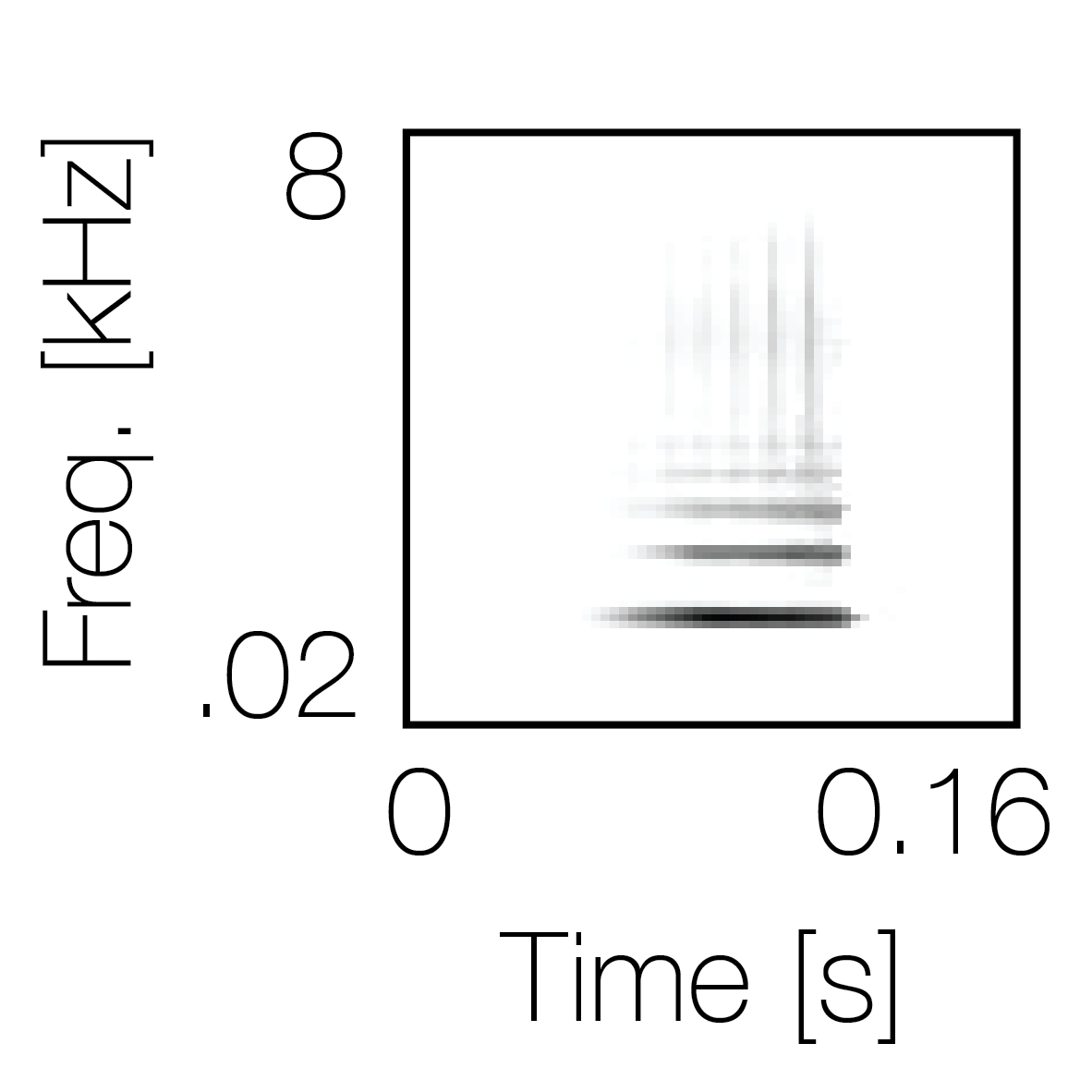
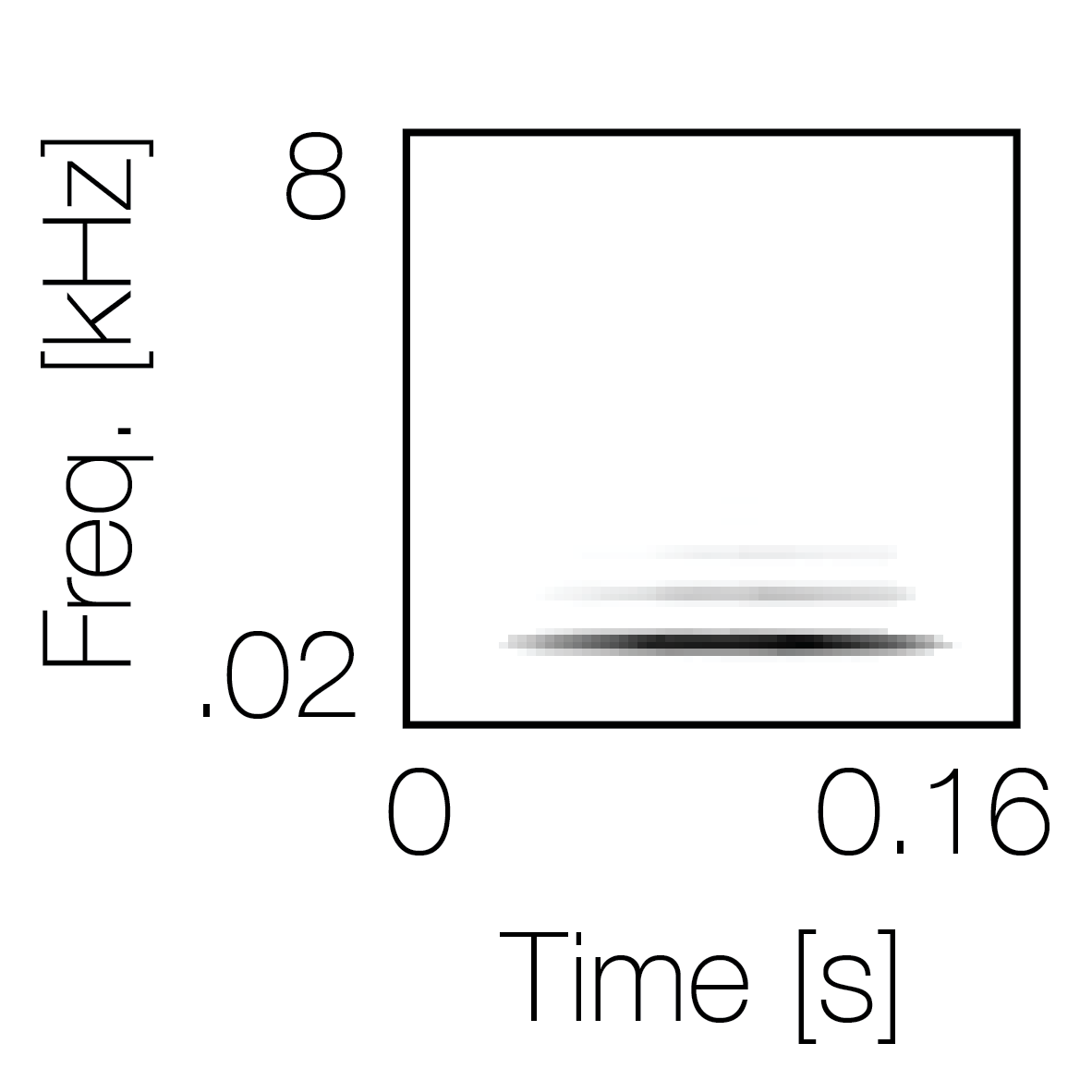
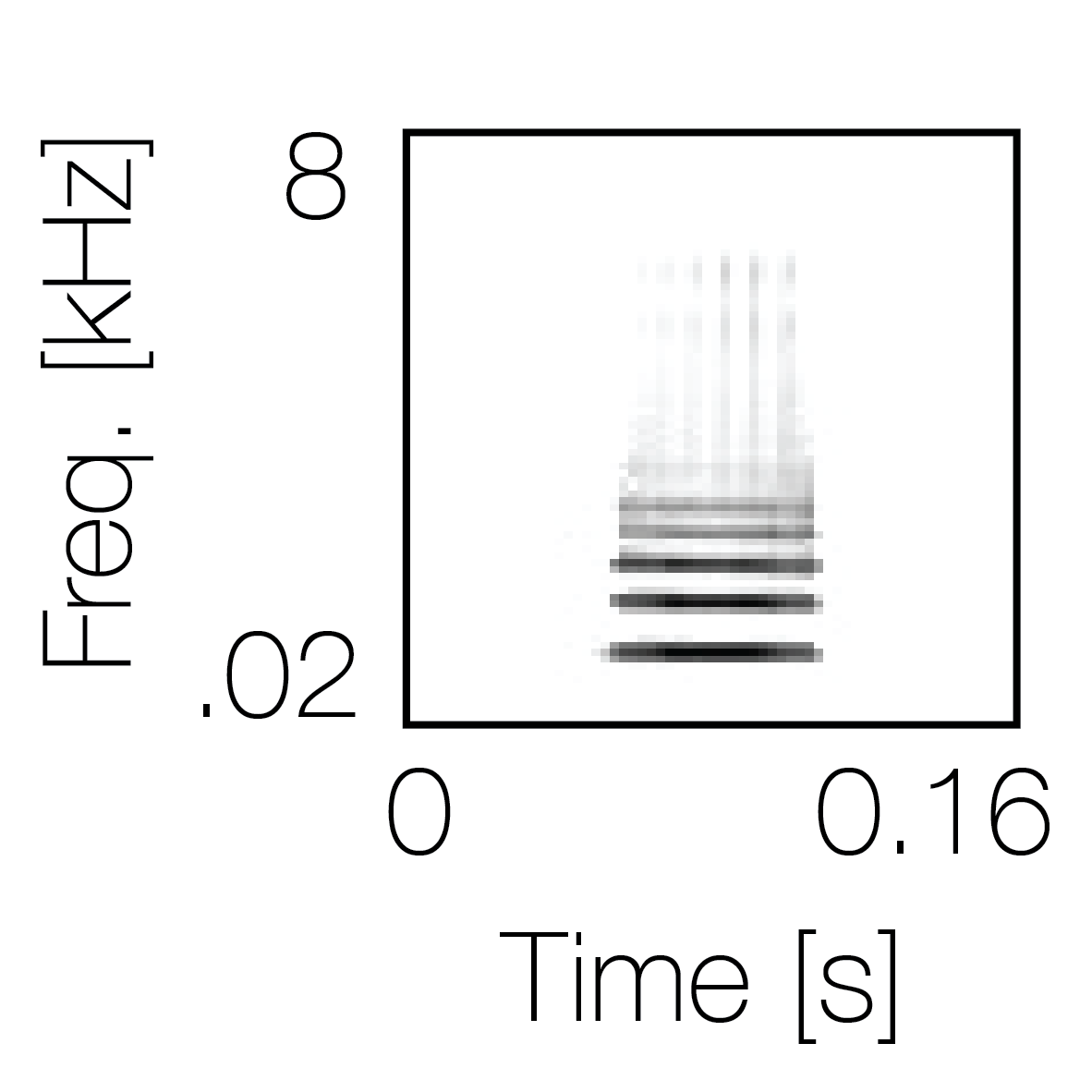
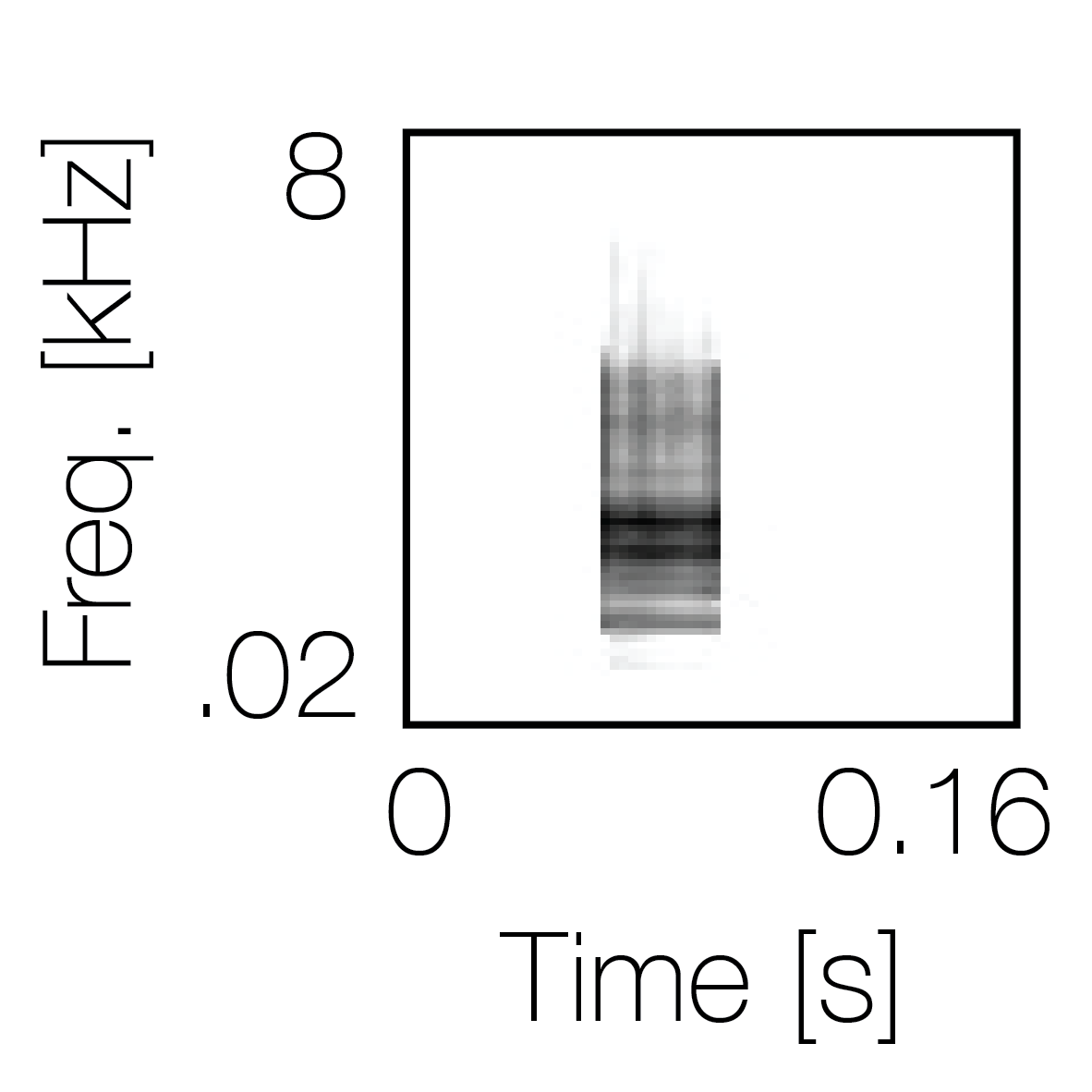
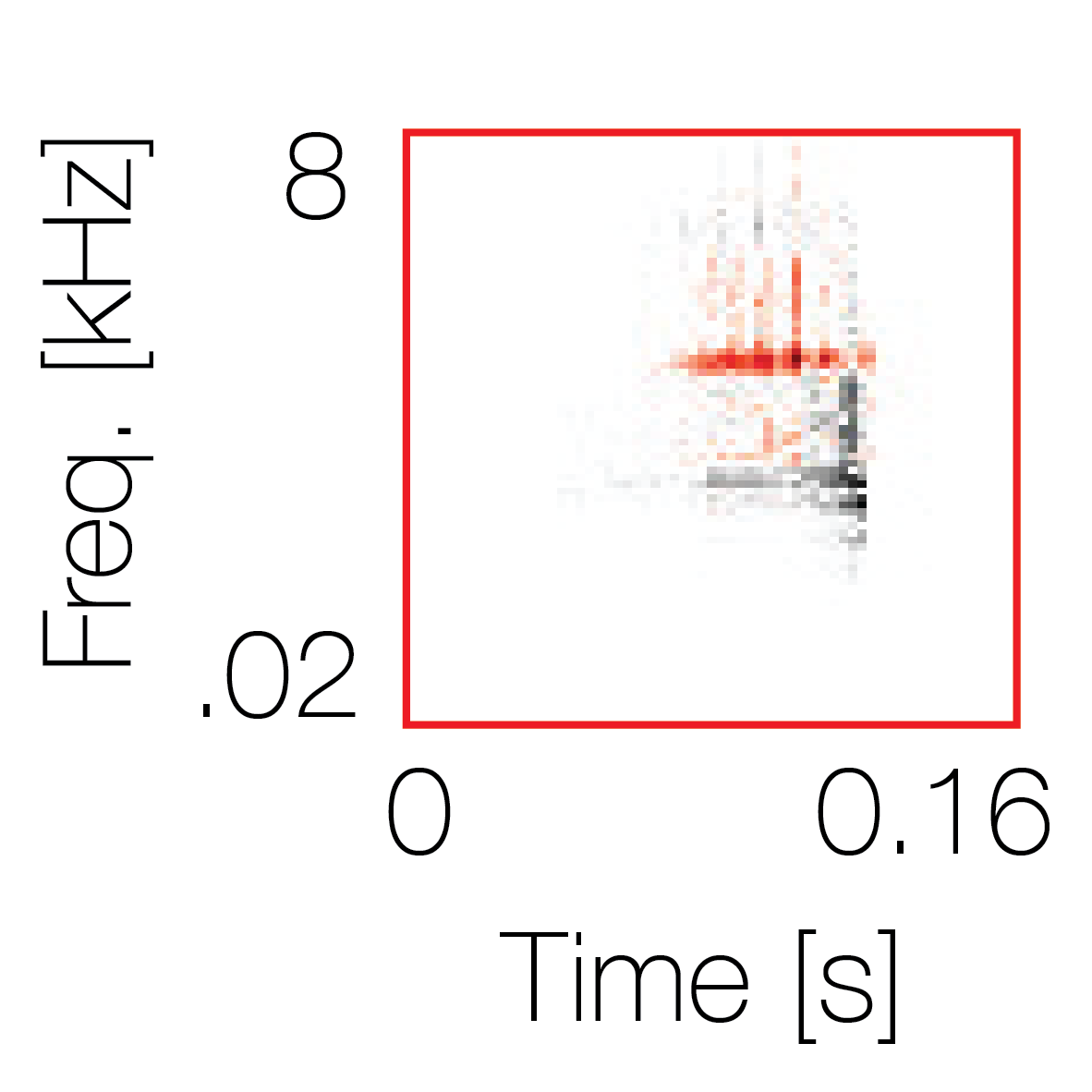
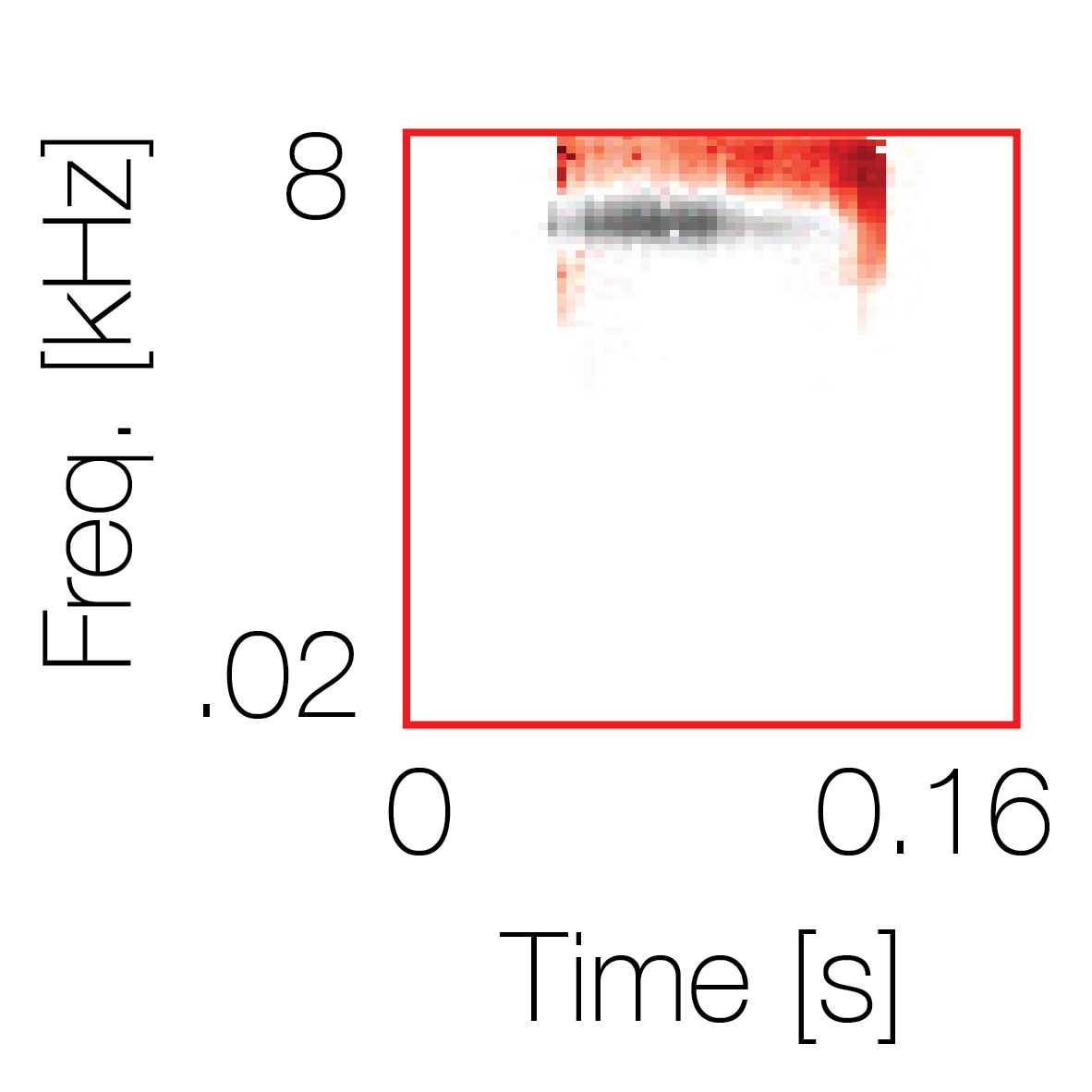
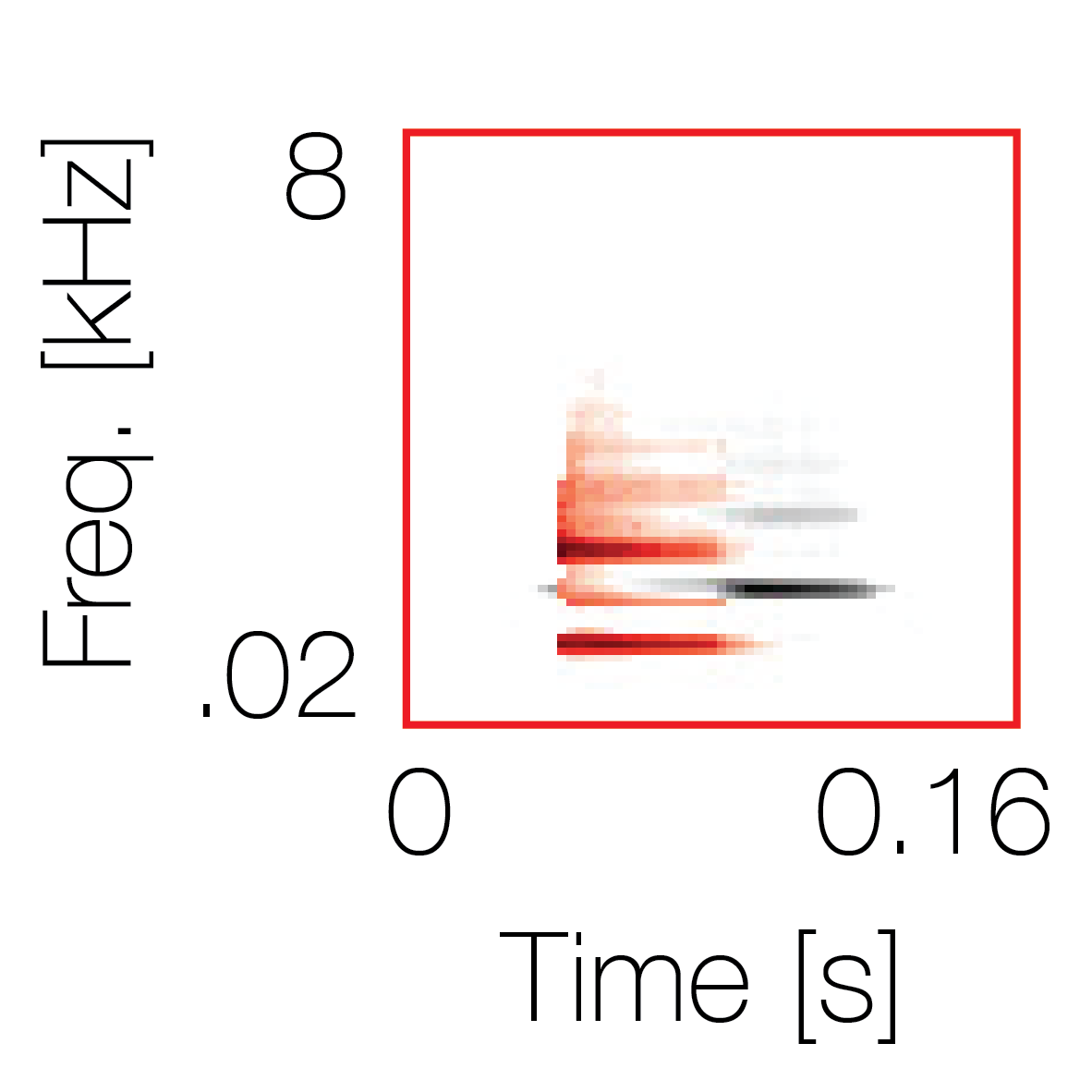
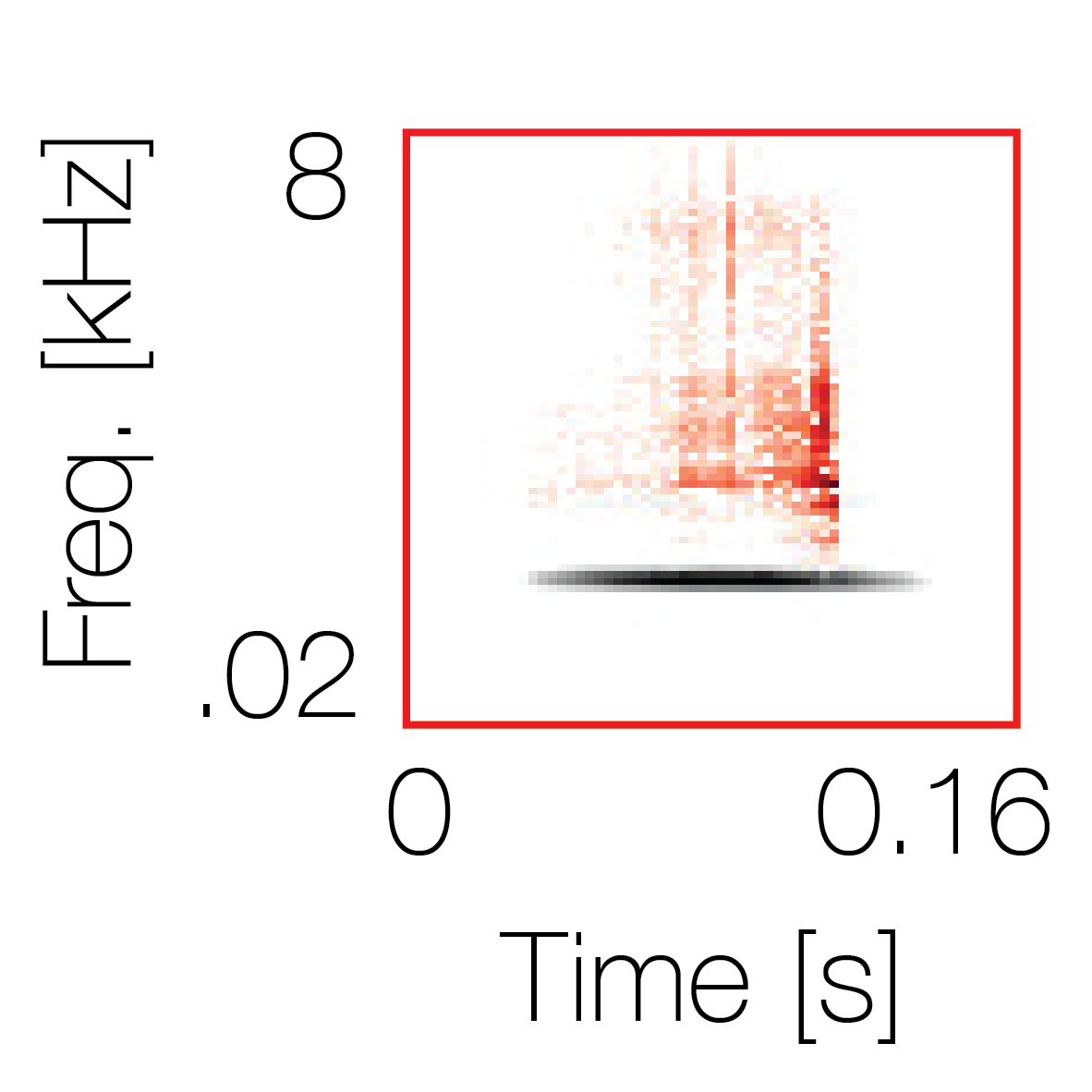
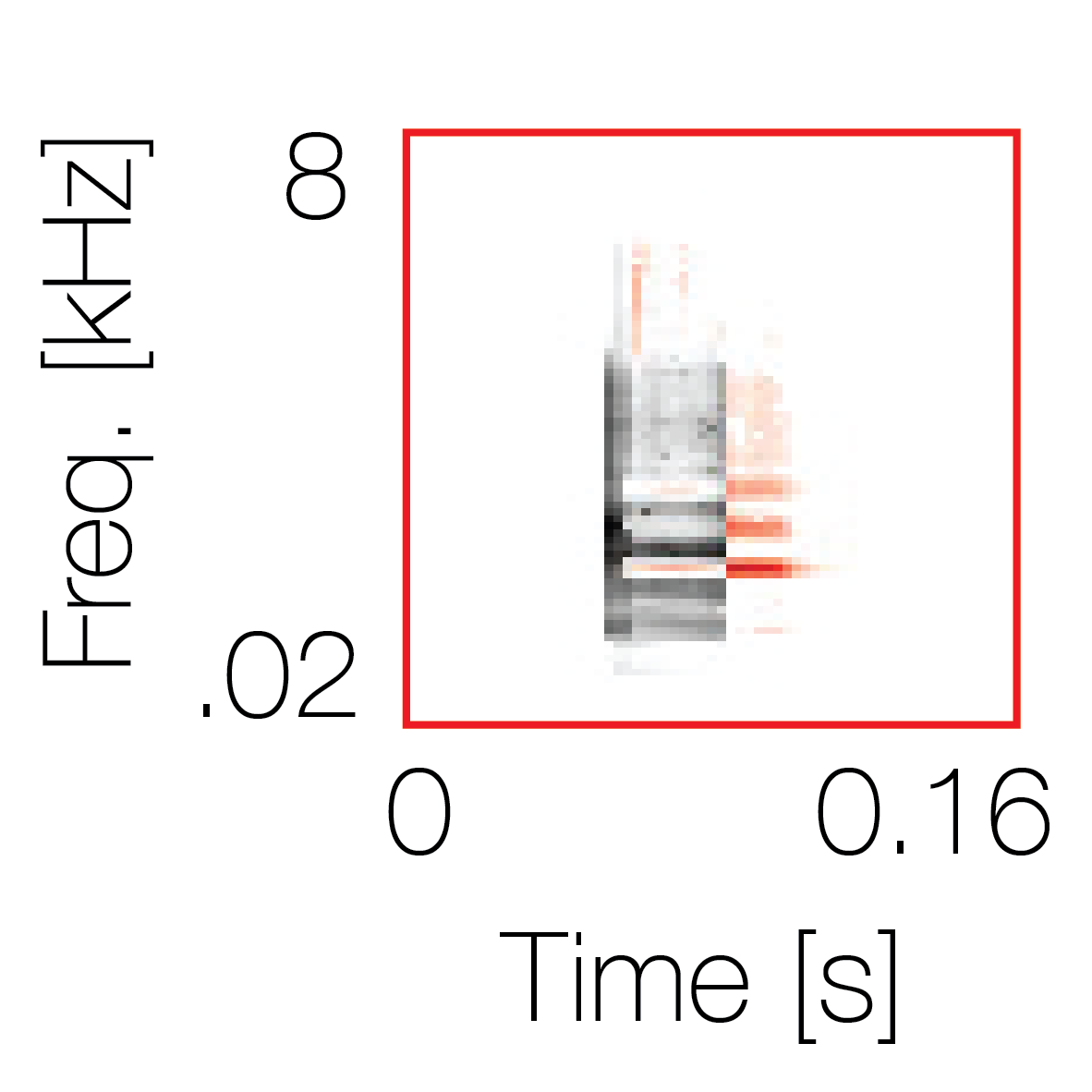
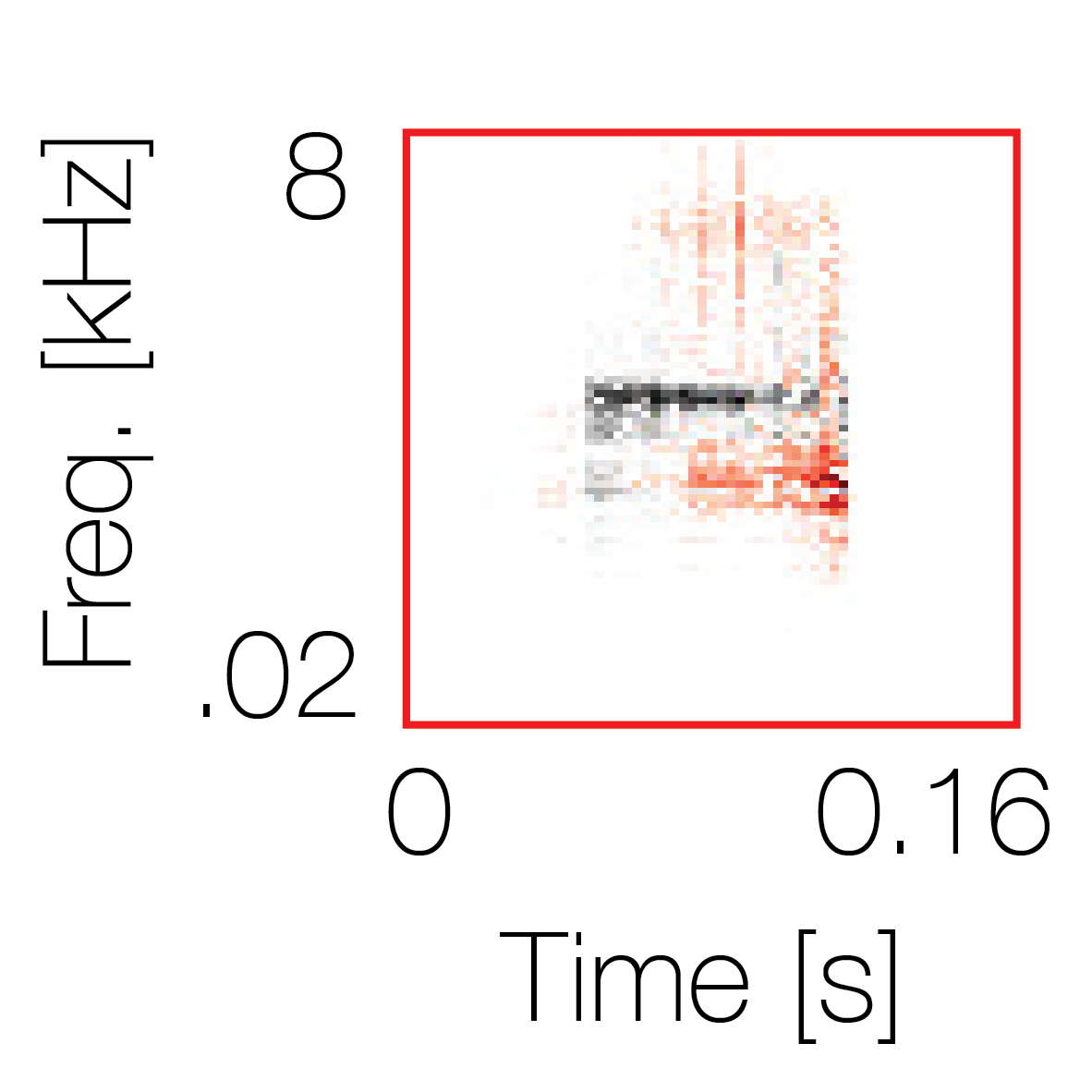
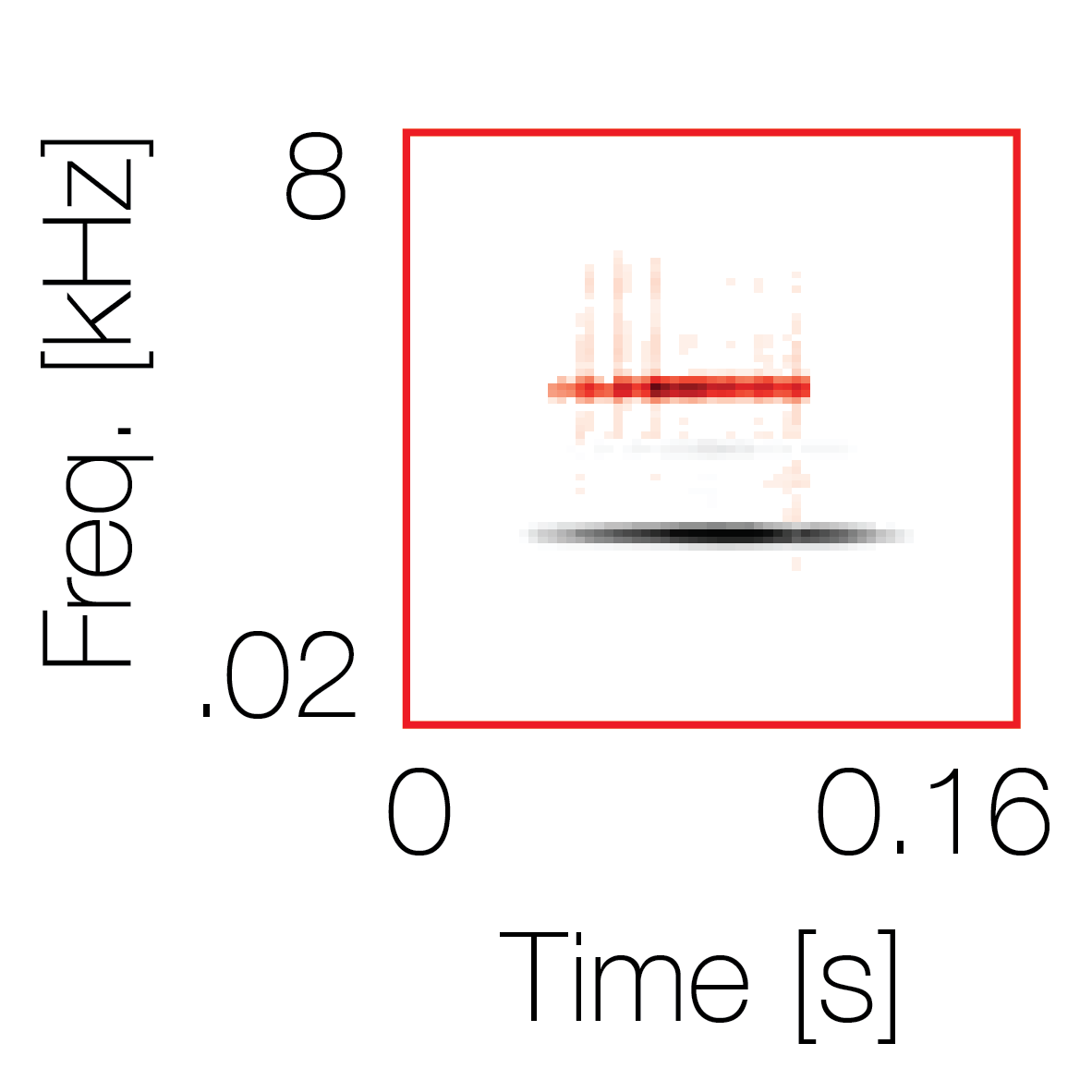
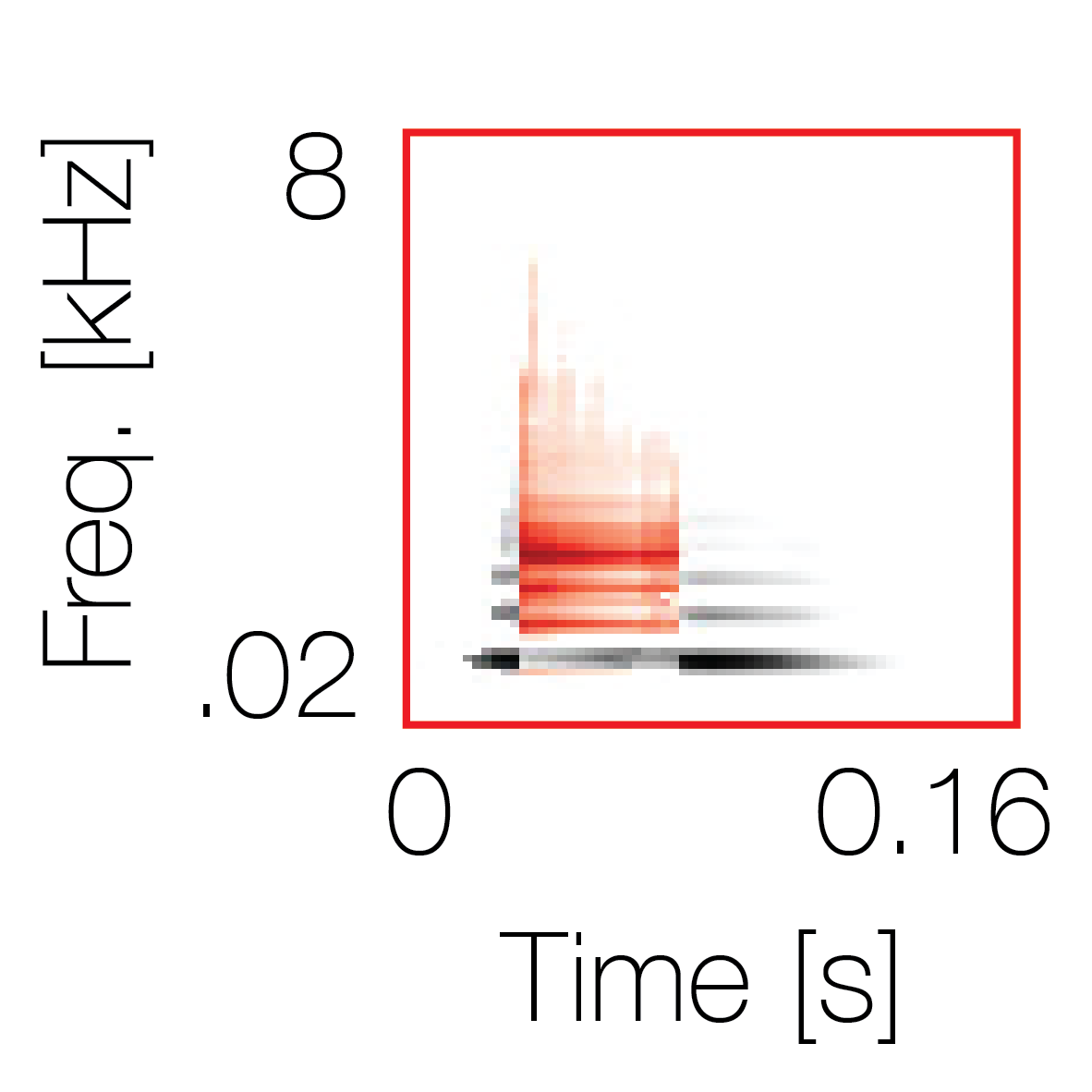
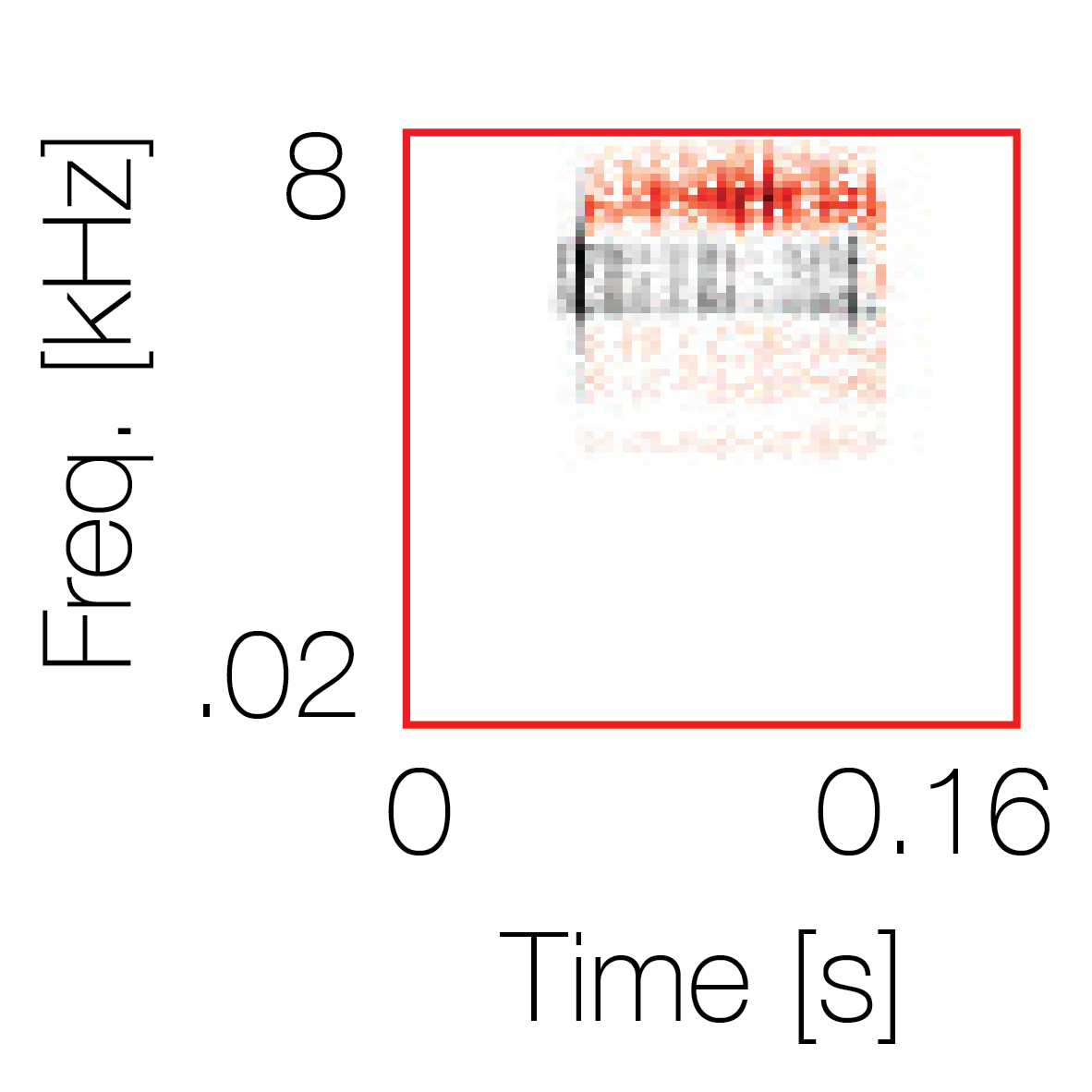
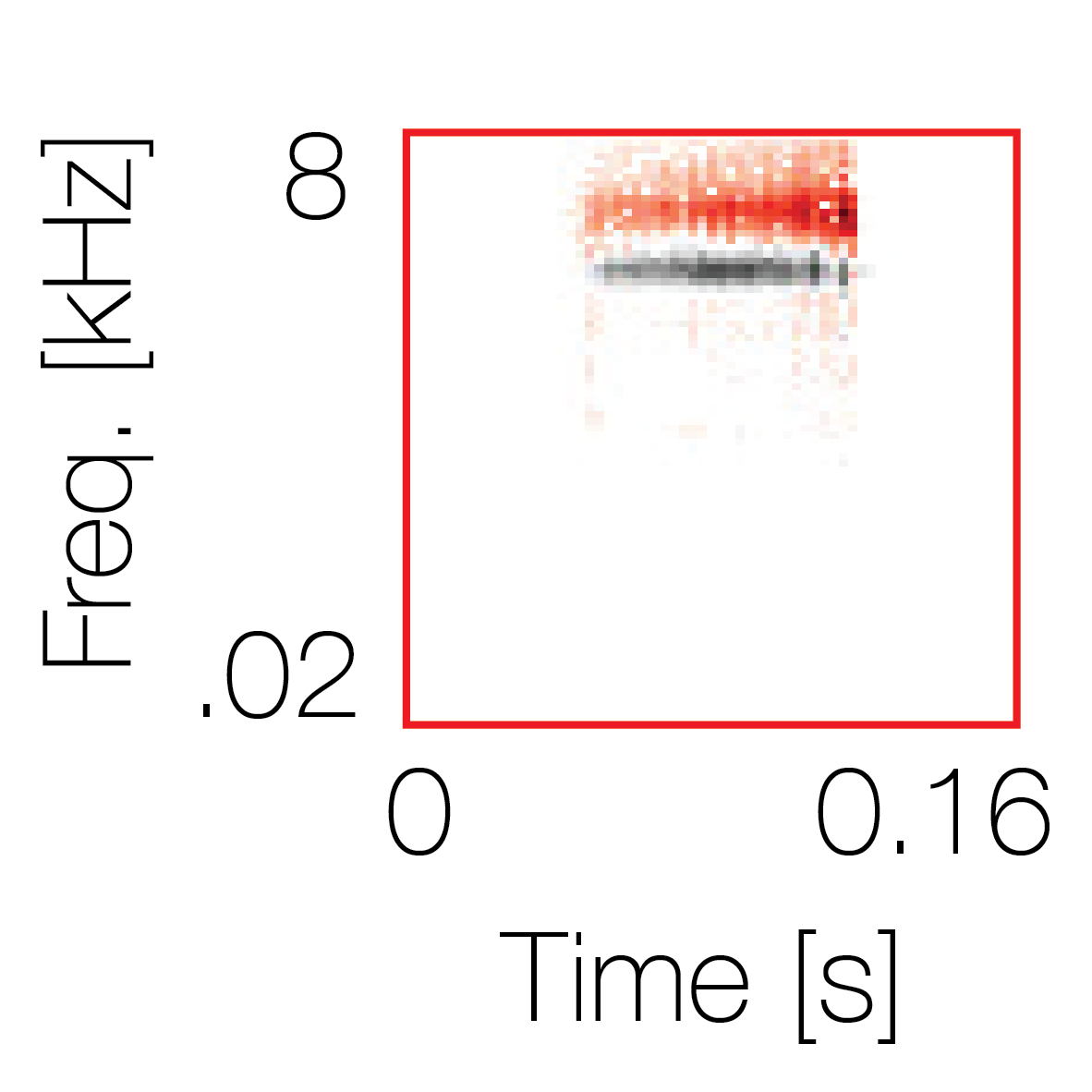
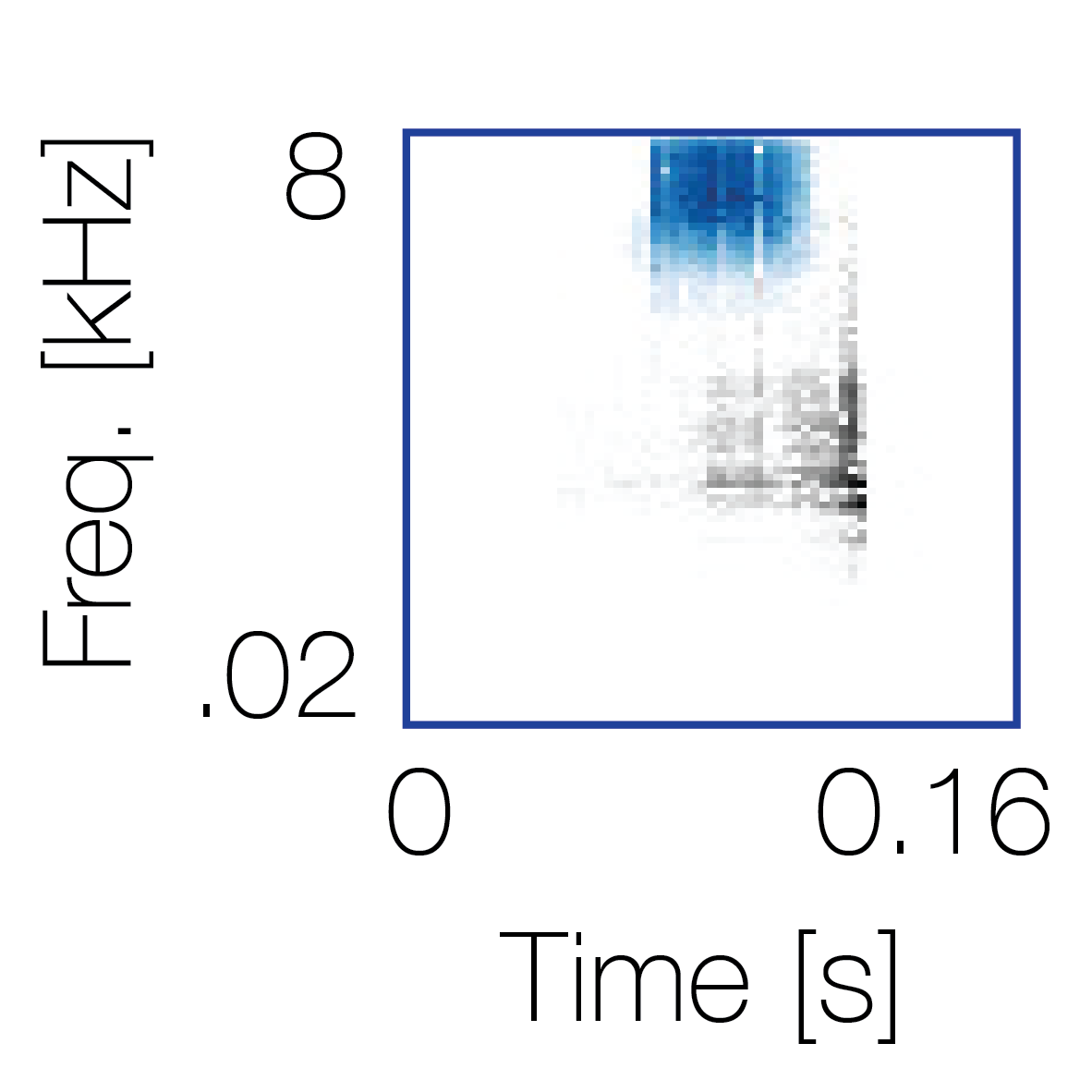
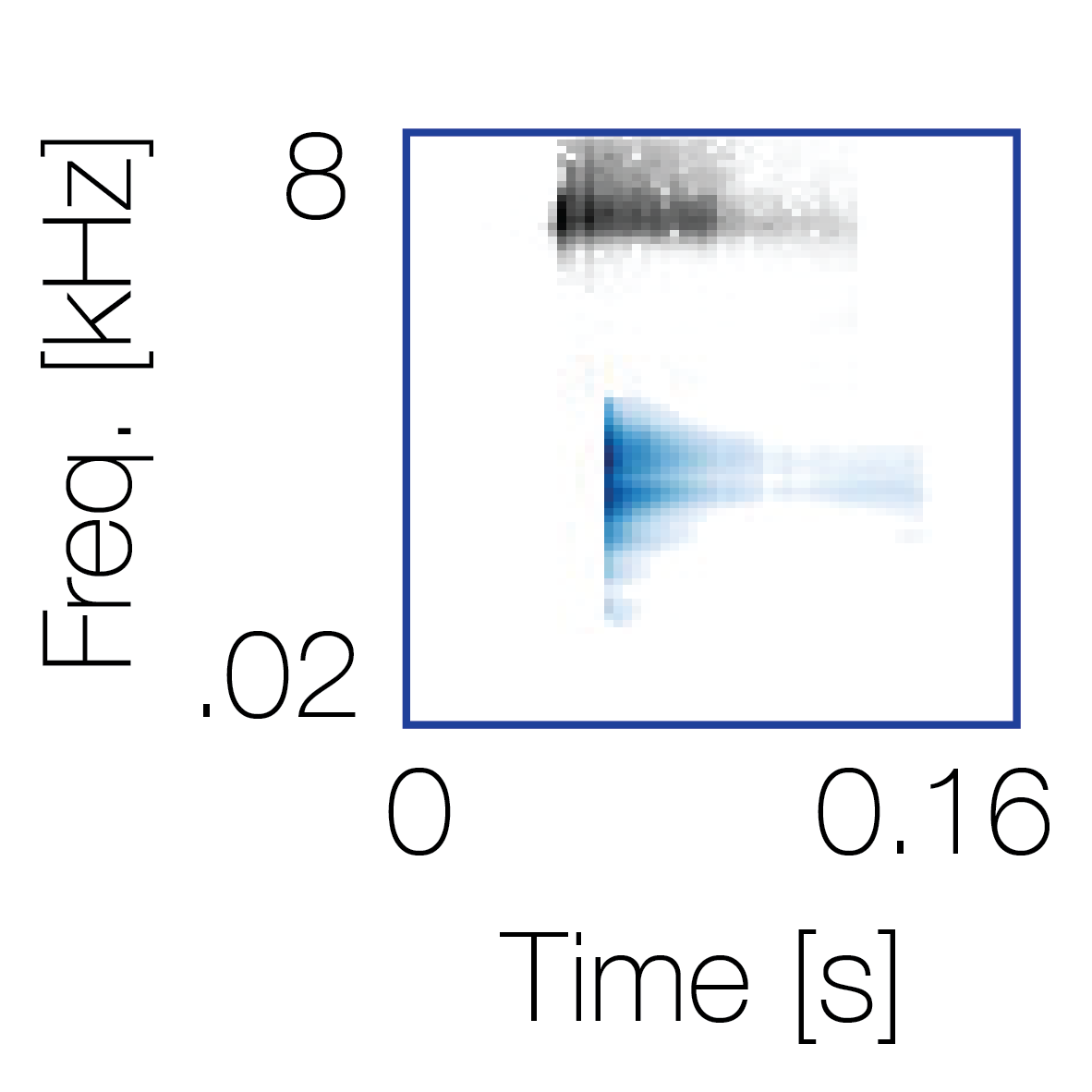
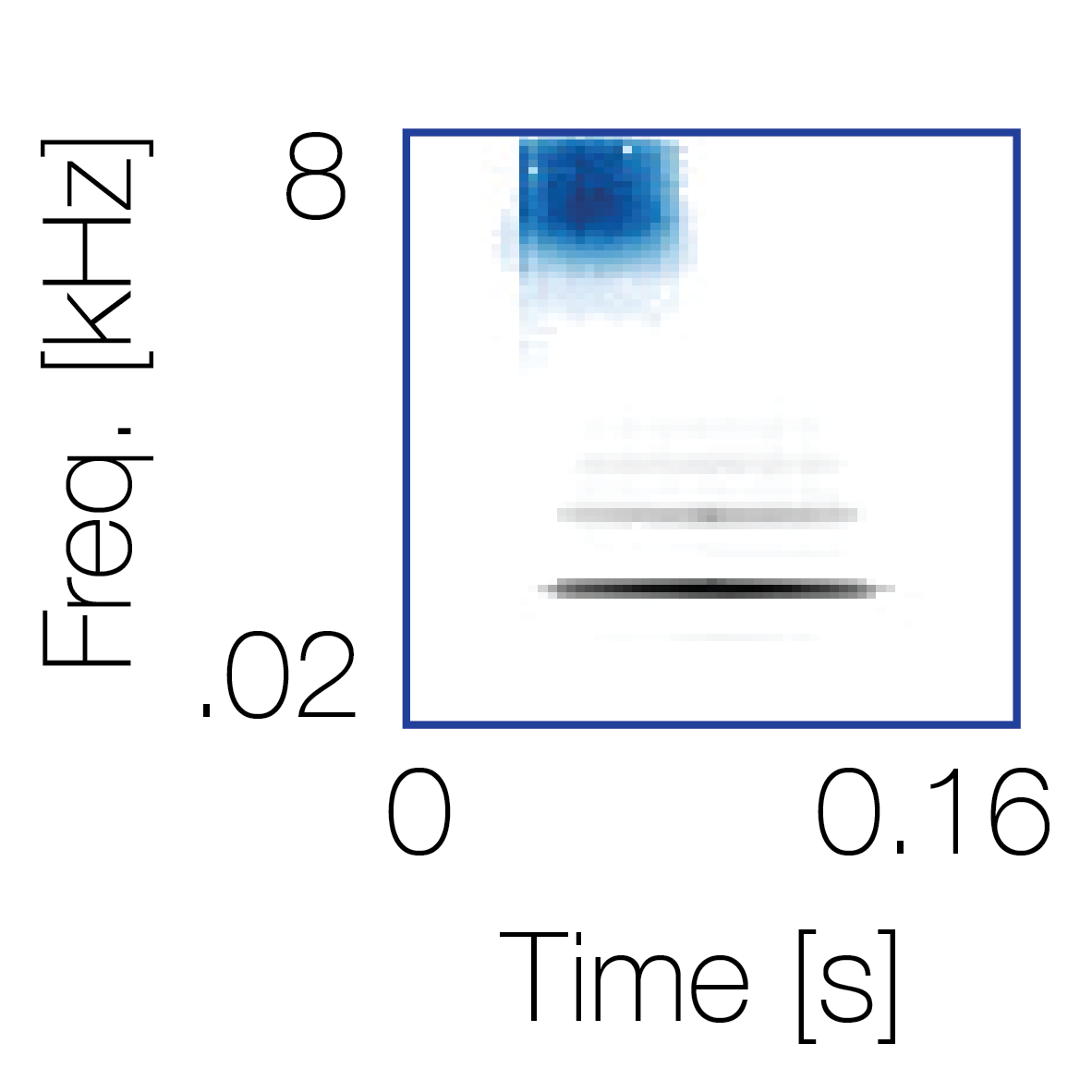
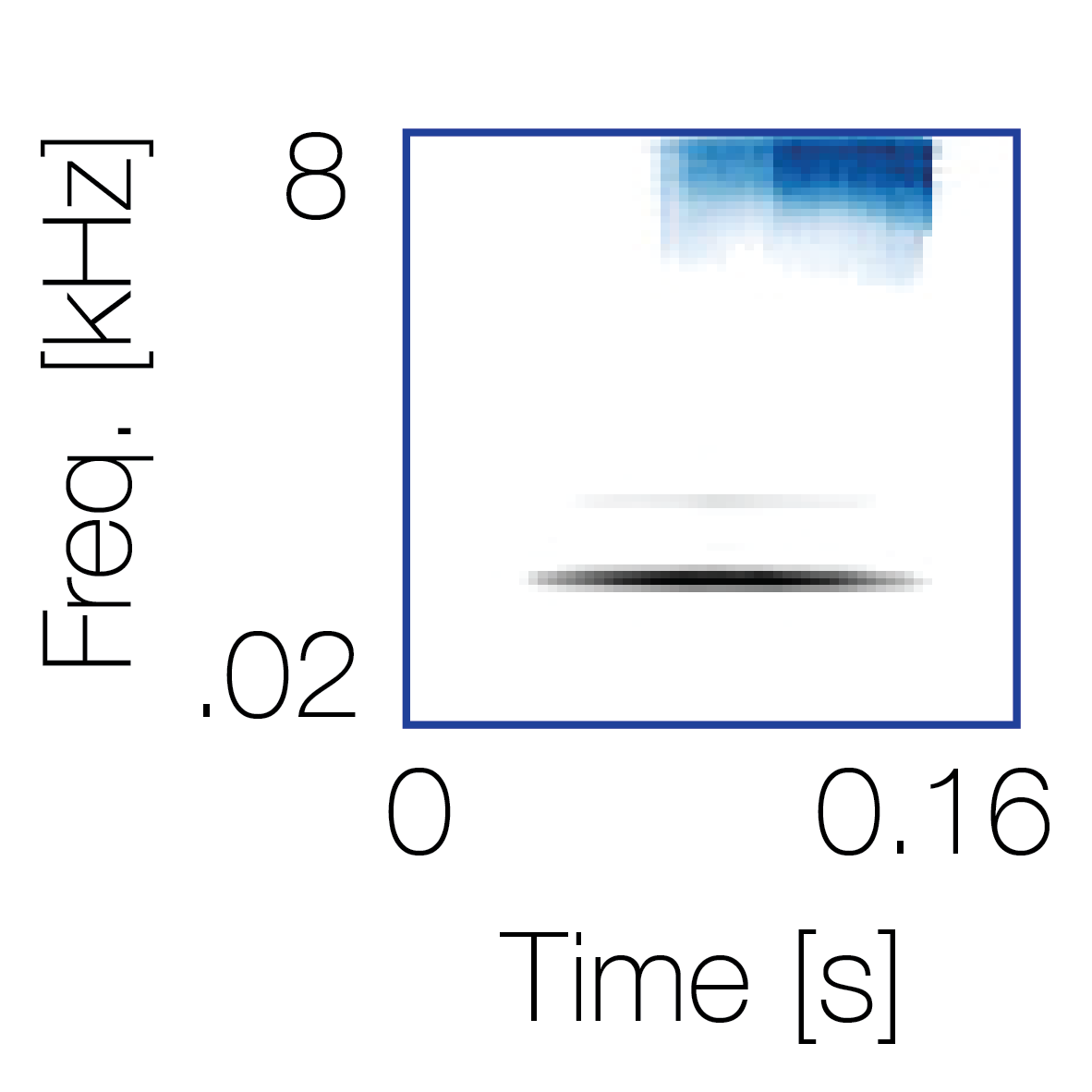

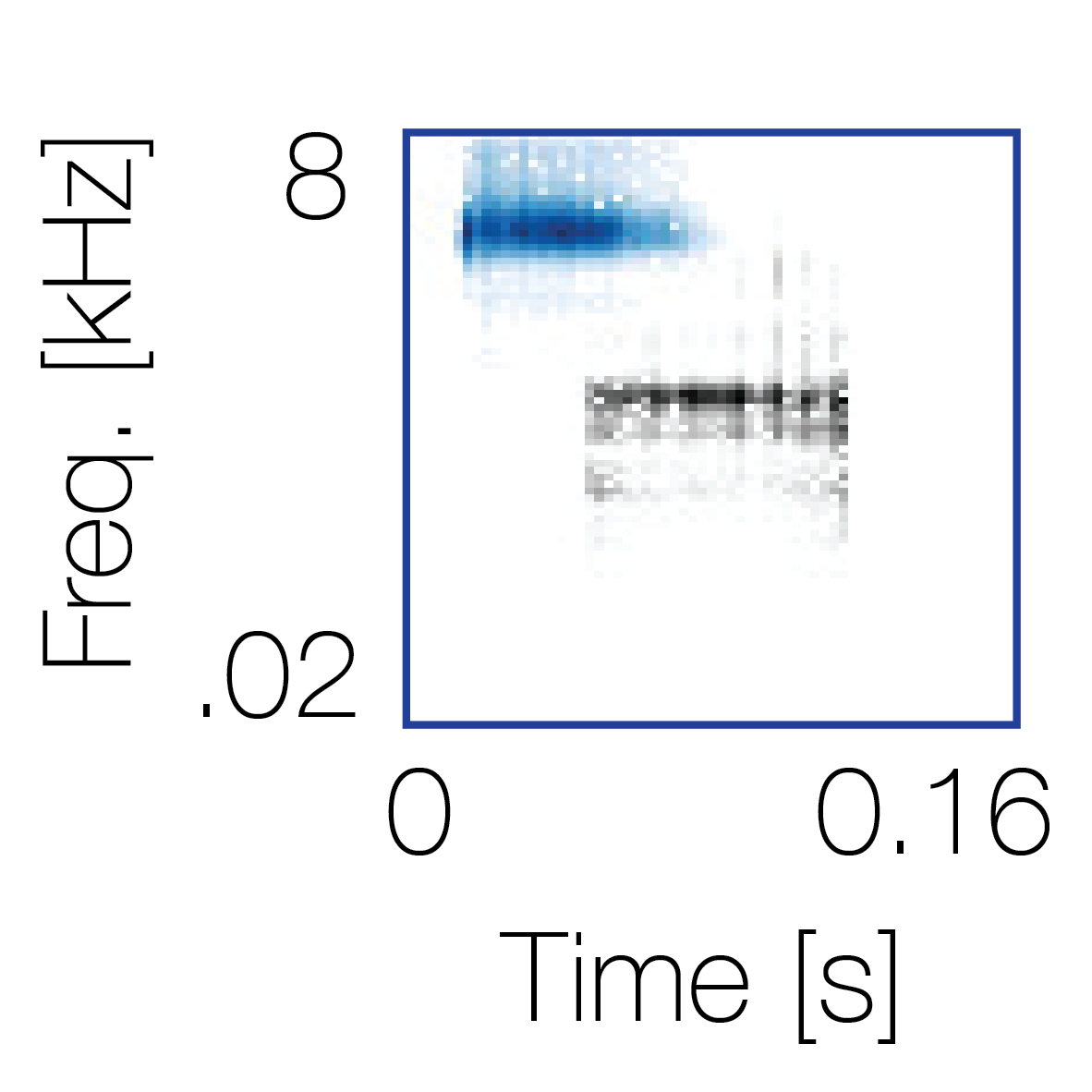
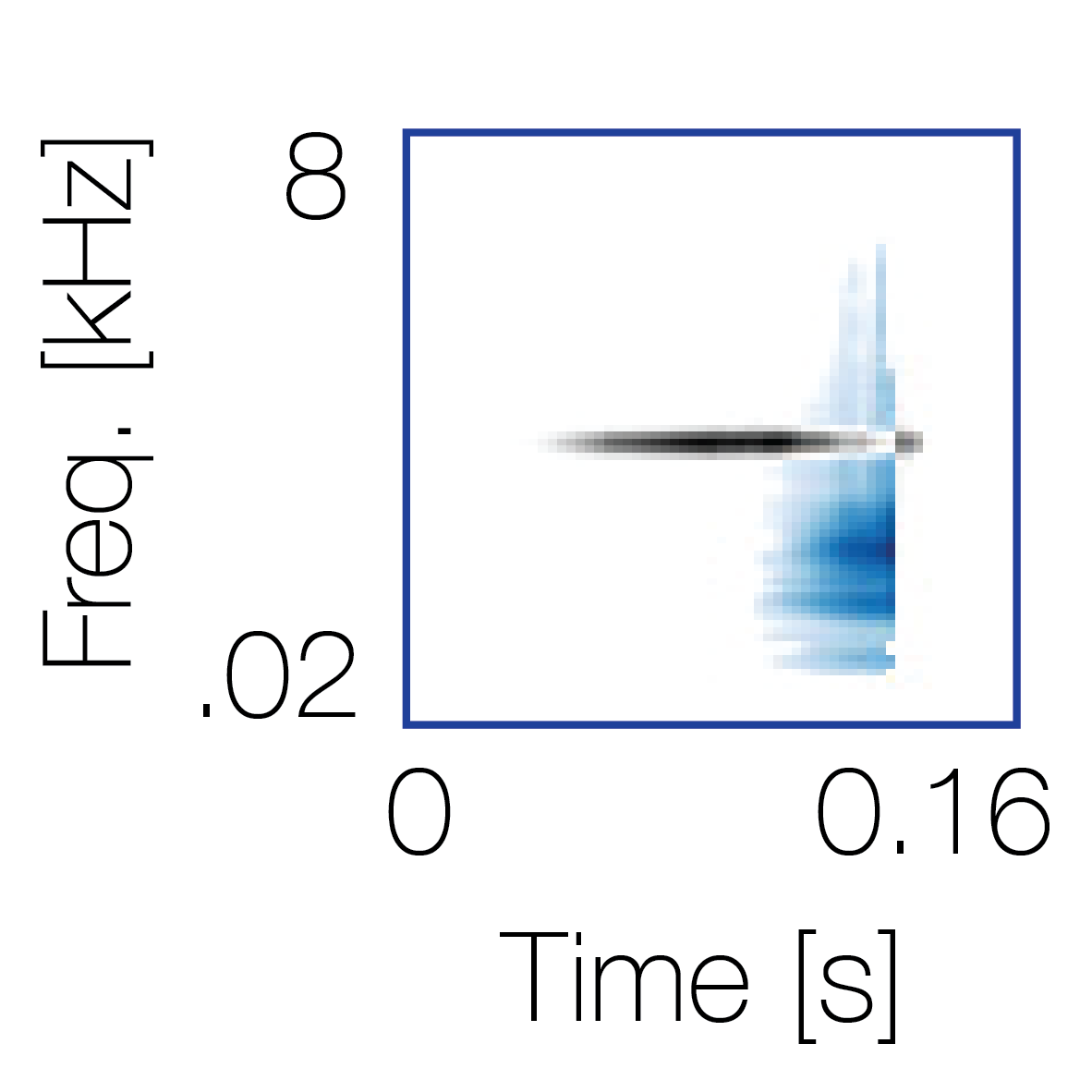
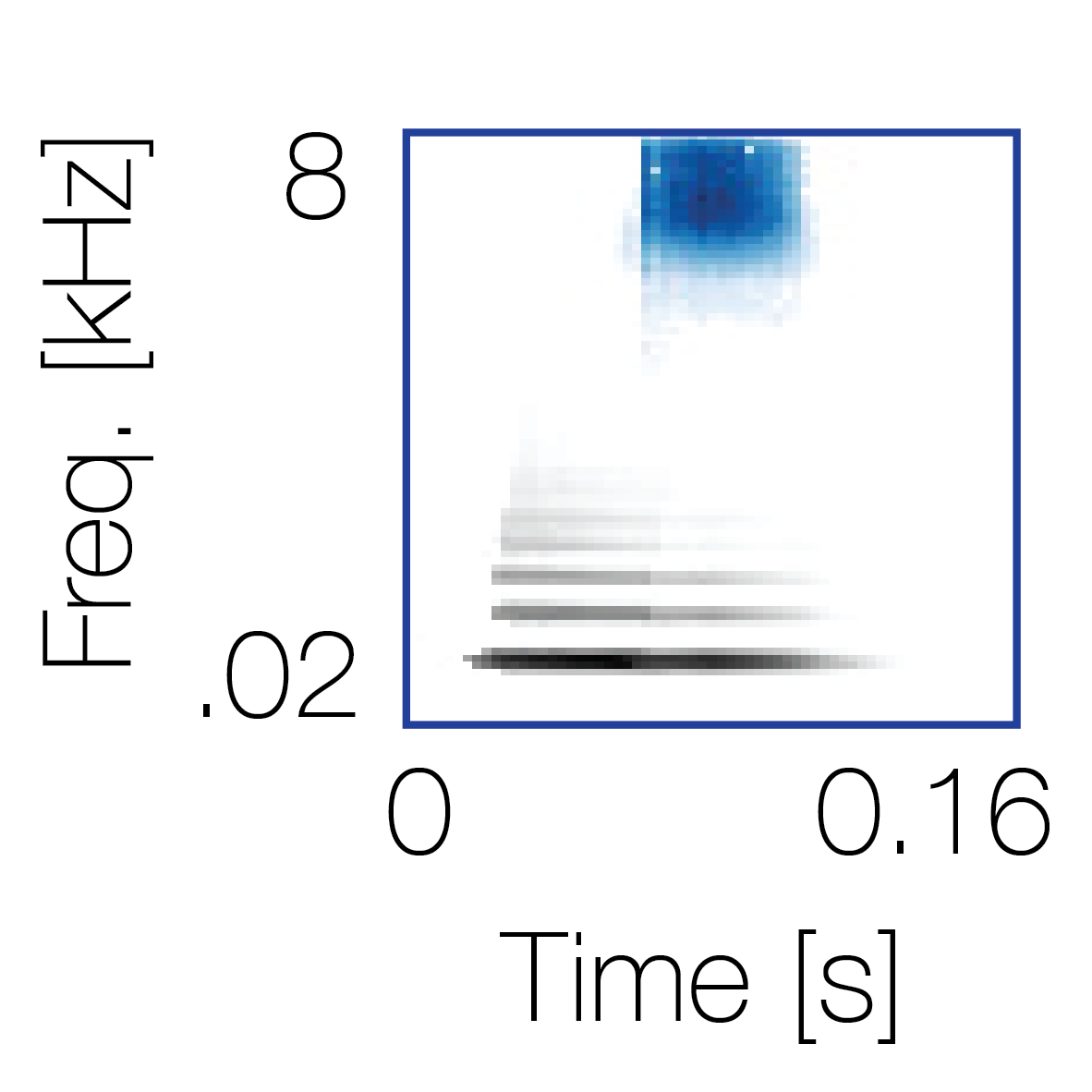
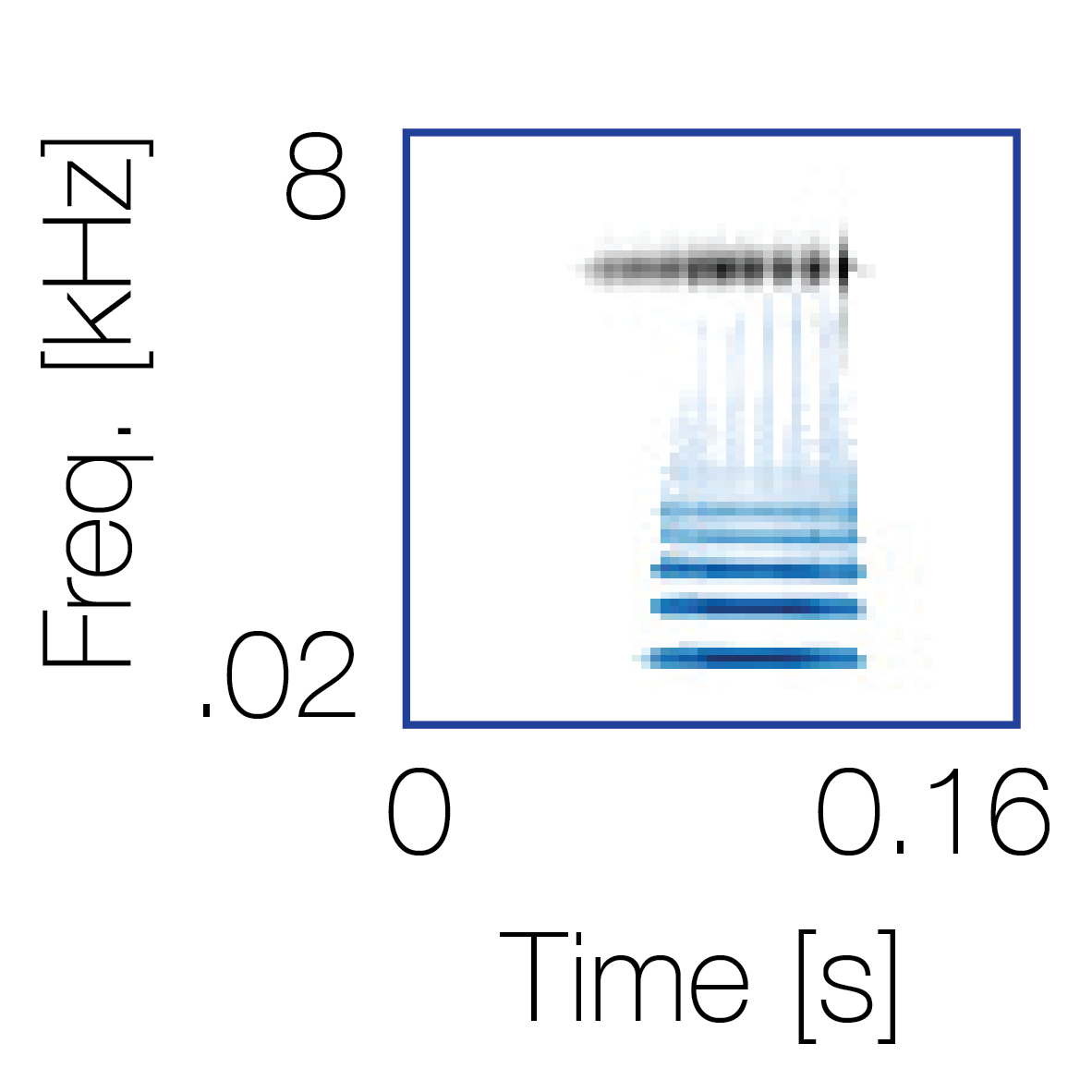
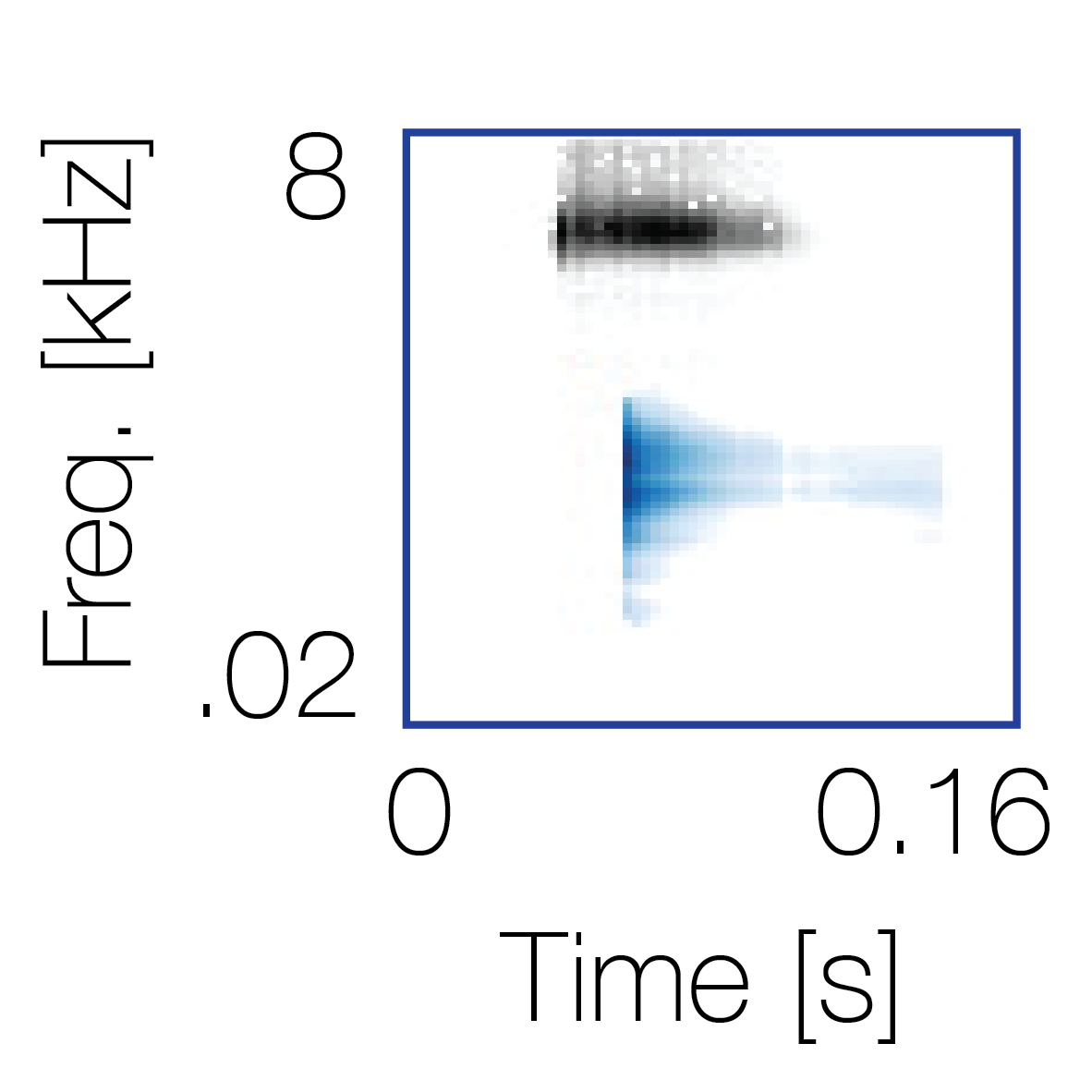 Spectrotemporal cue 1
Spectrotemporal cue 1 Grouping feature mixtures (low cue value)All 4 cues have low values |
Non-grouping feature mixtures (high cue value)Remaining 3 cues have low values |
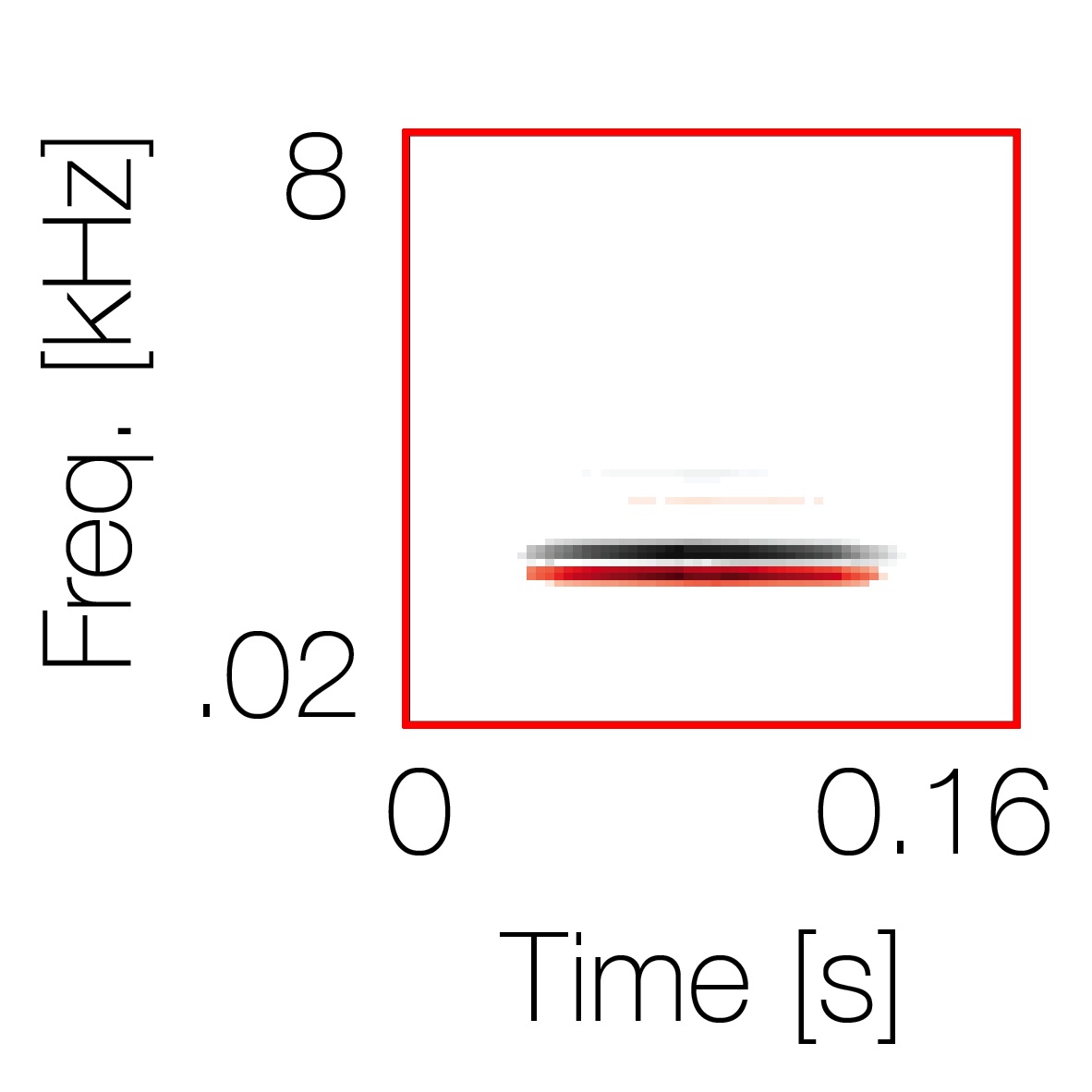
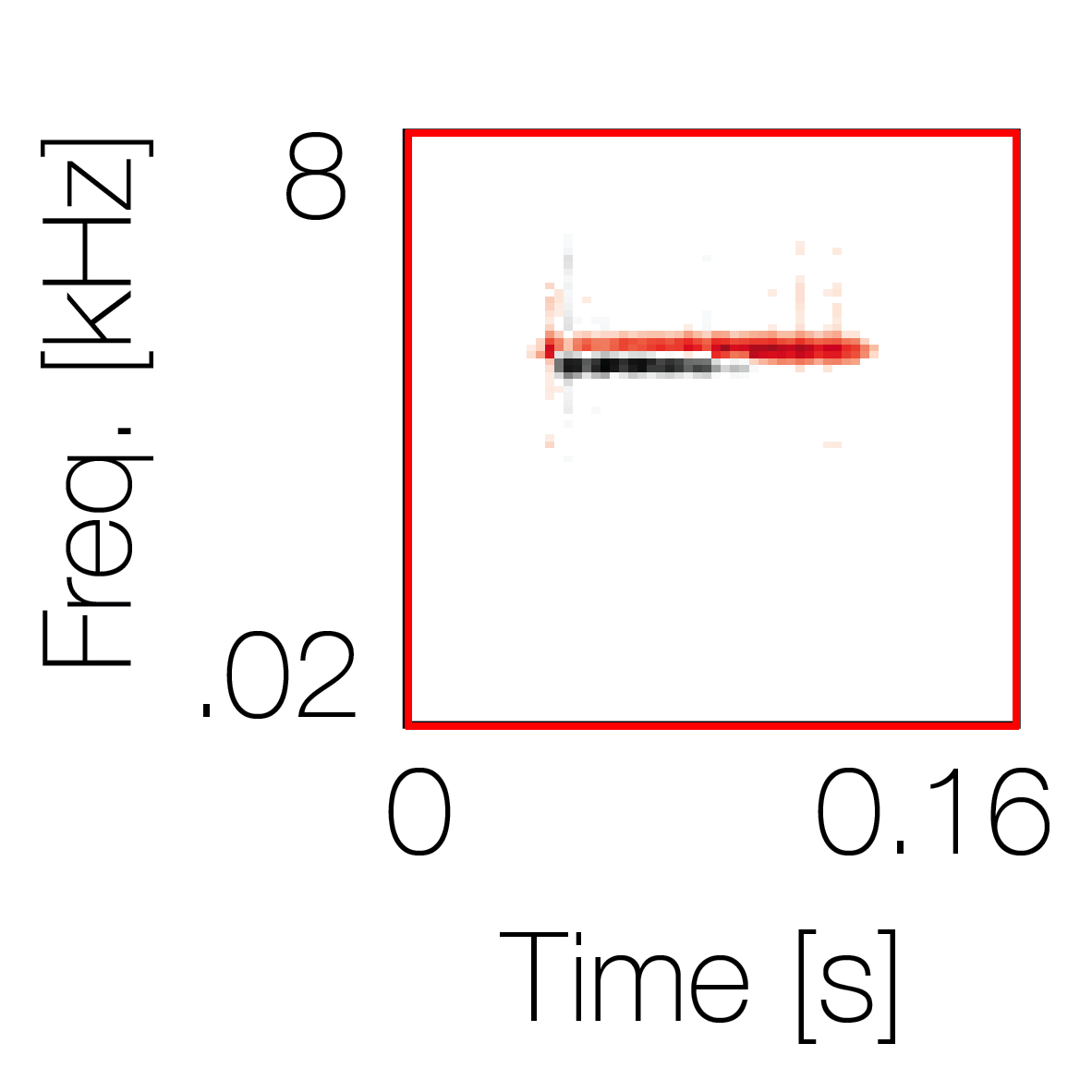
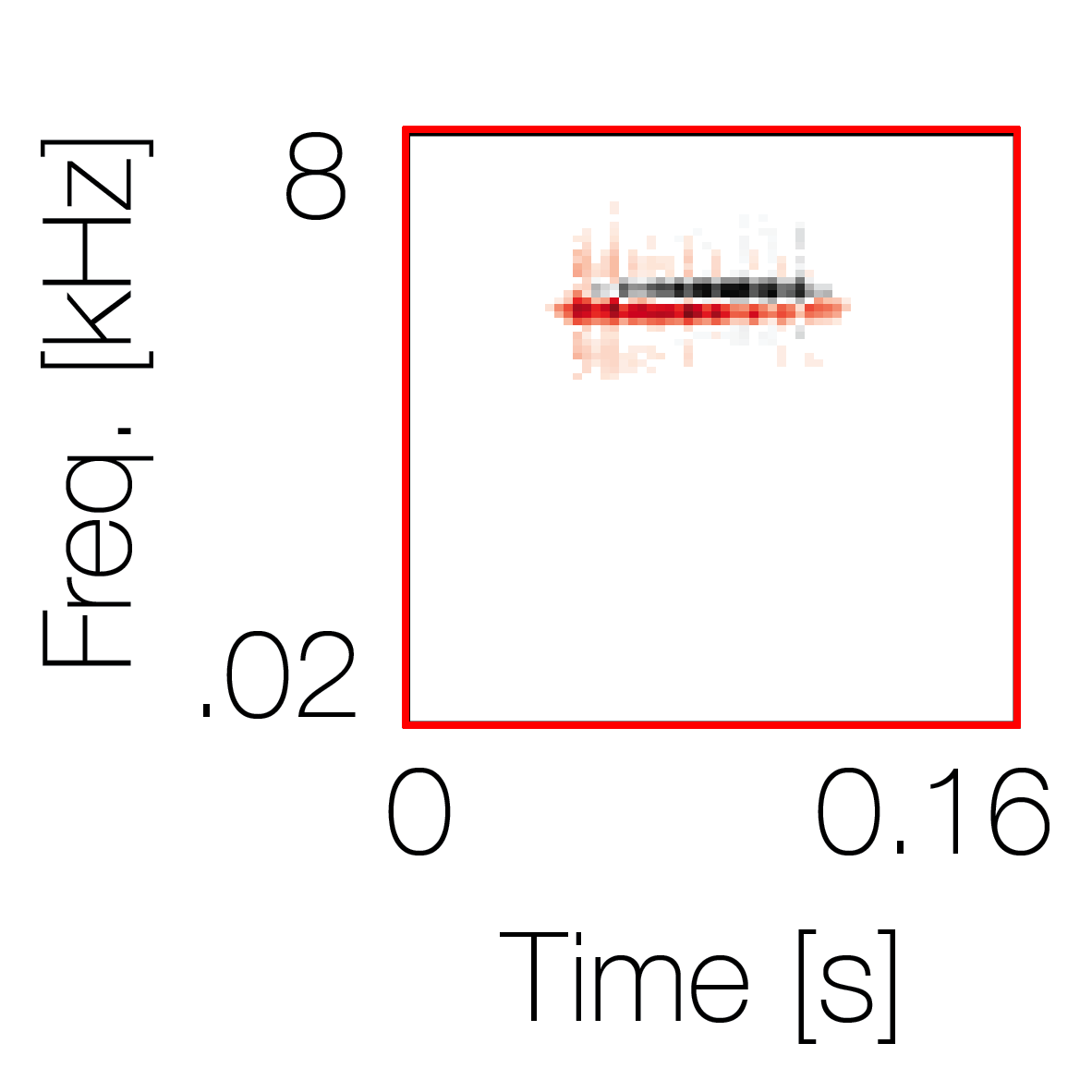
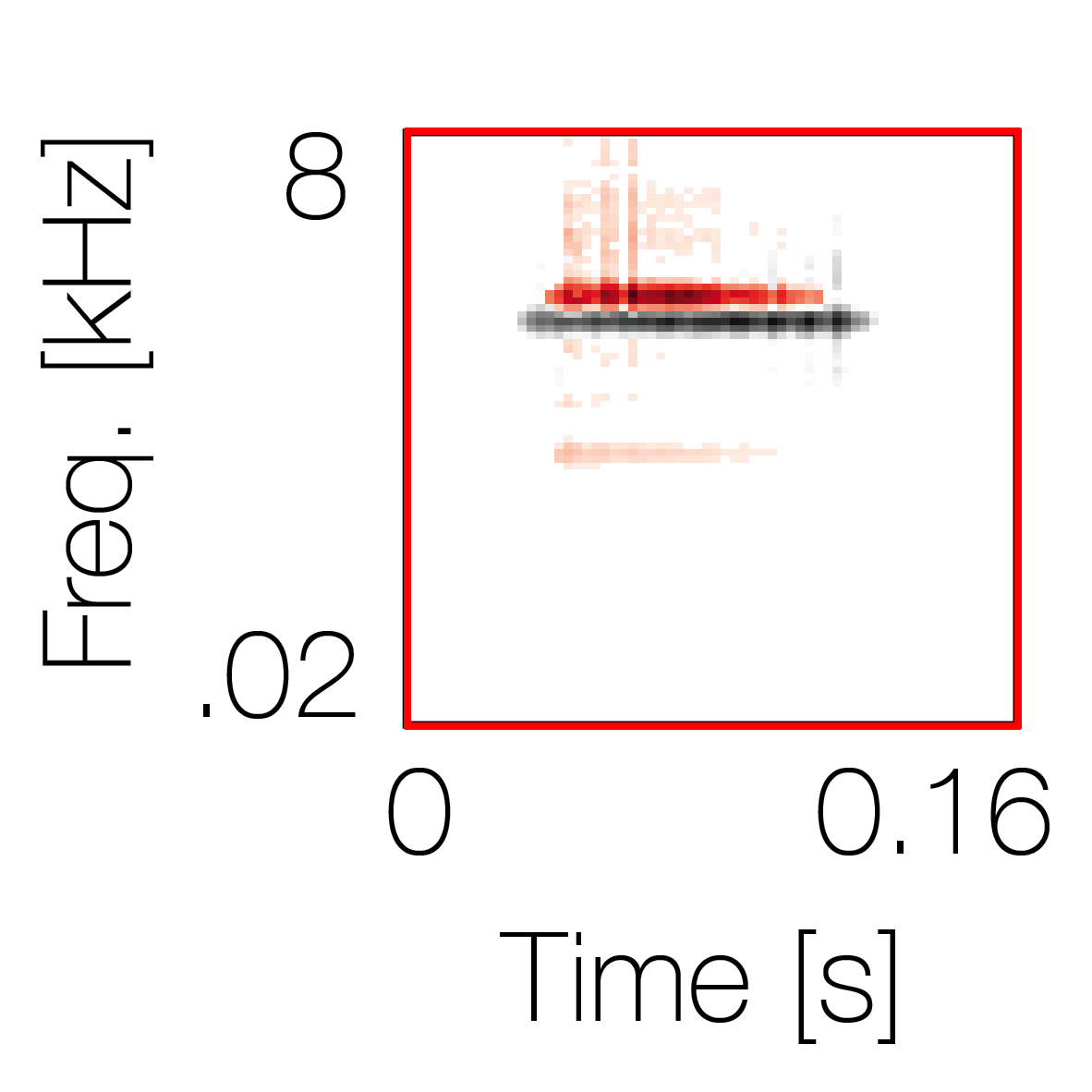
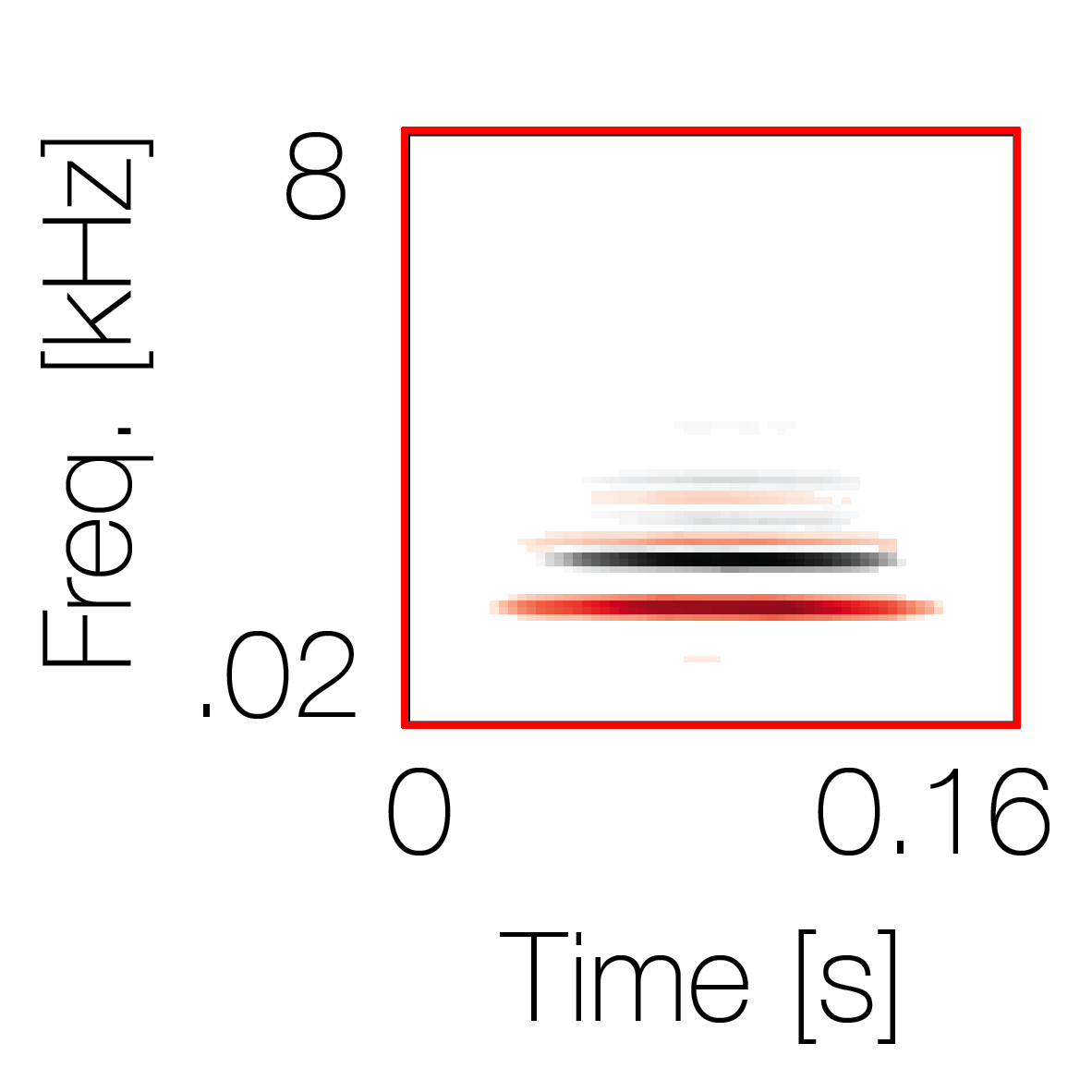
|
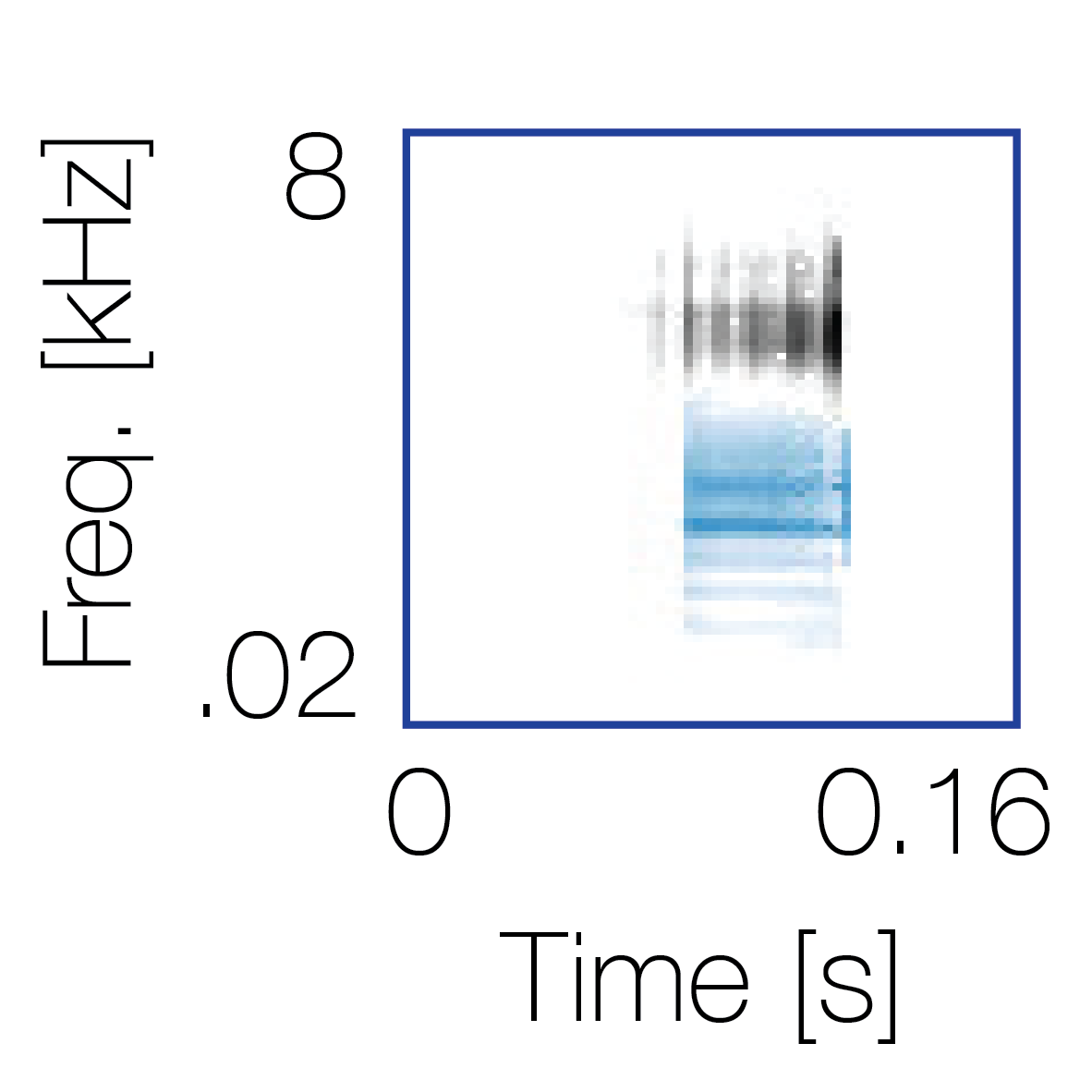
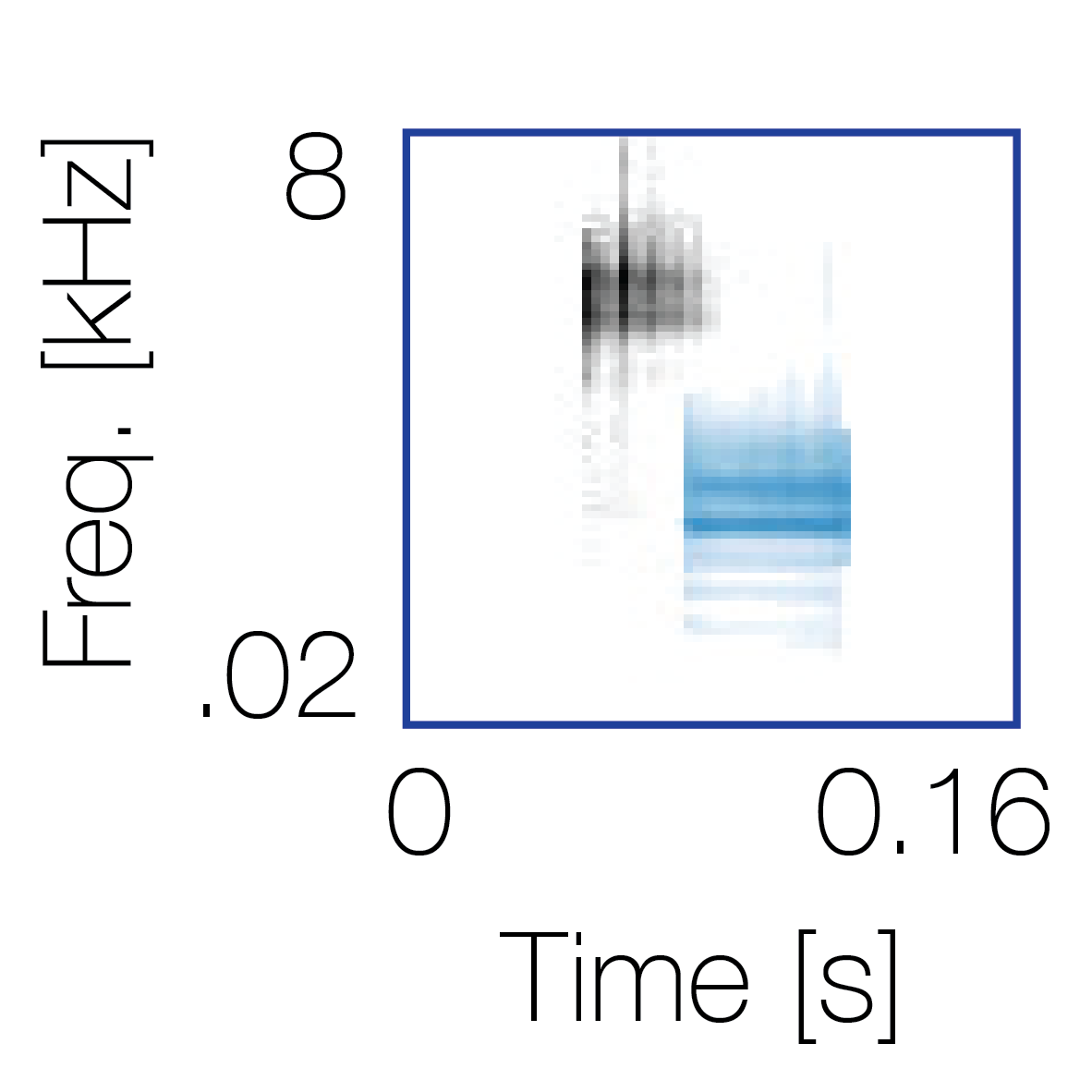
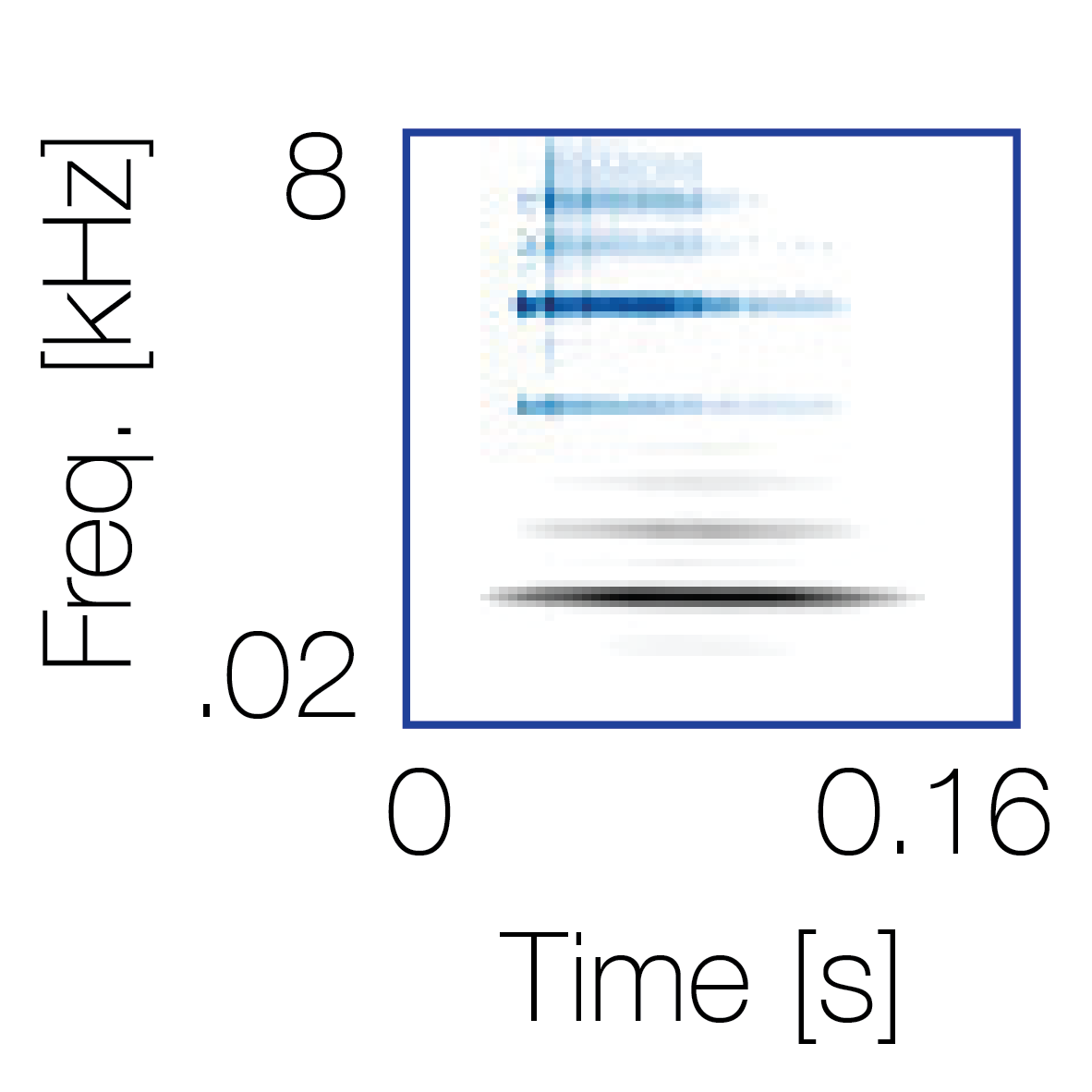
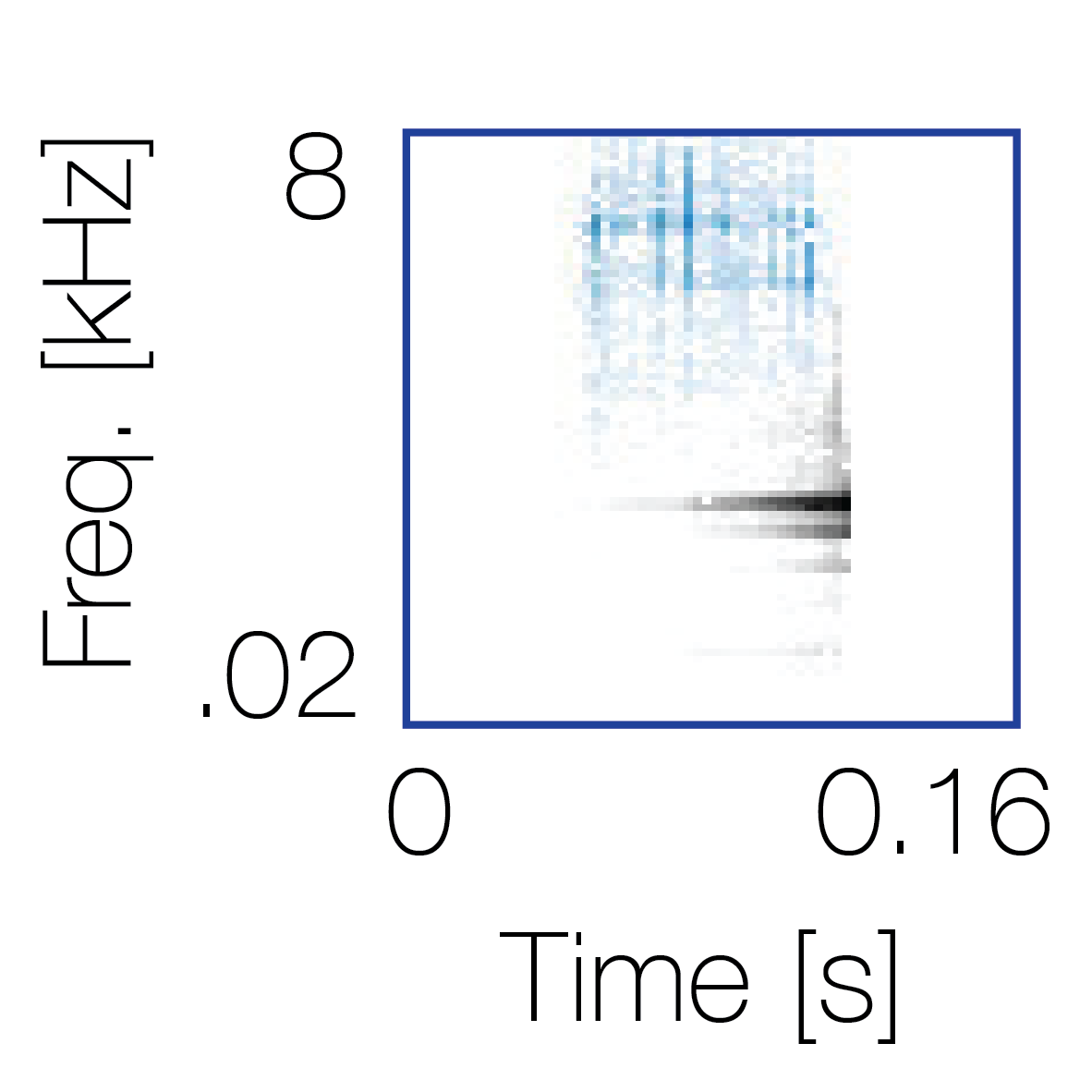
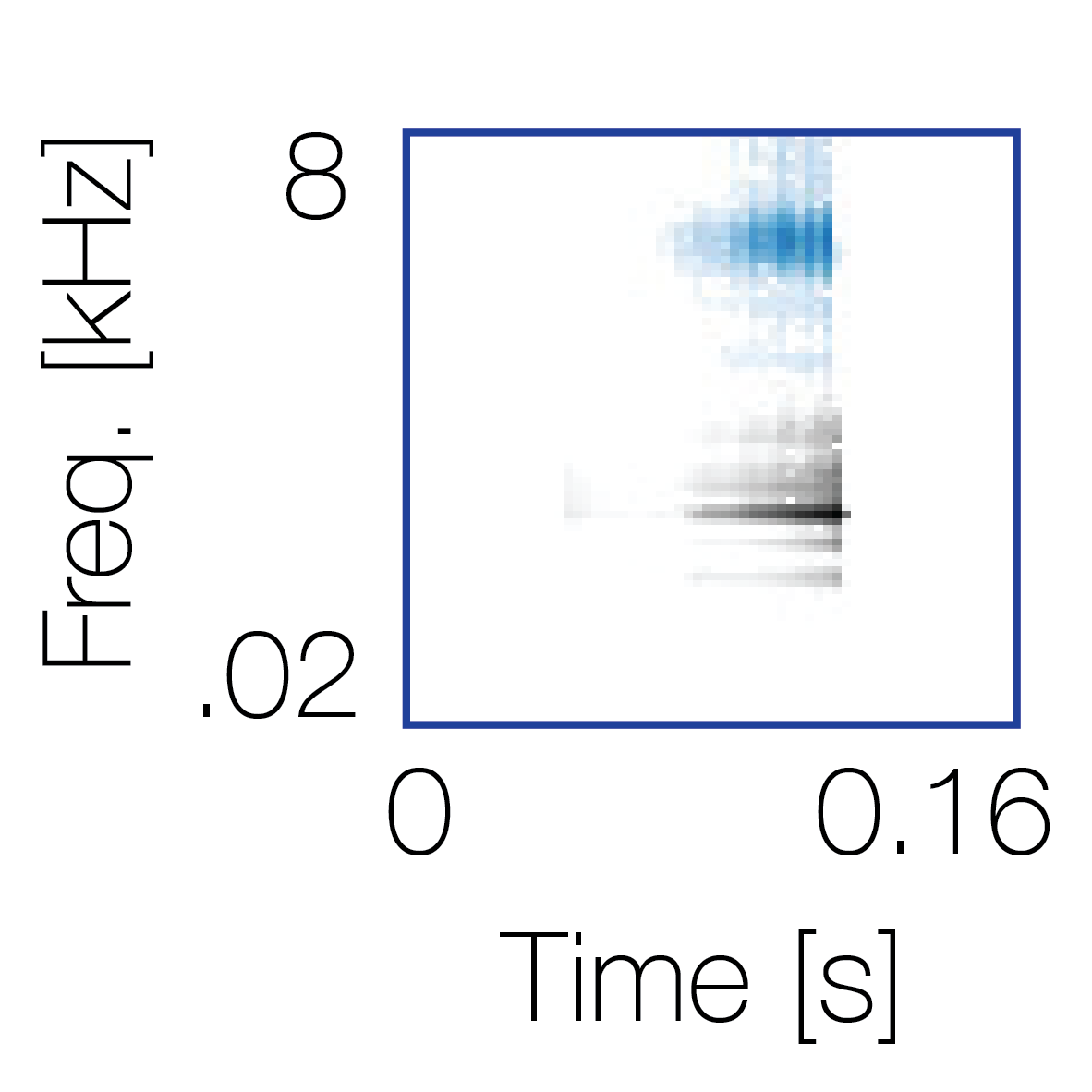
|
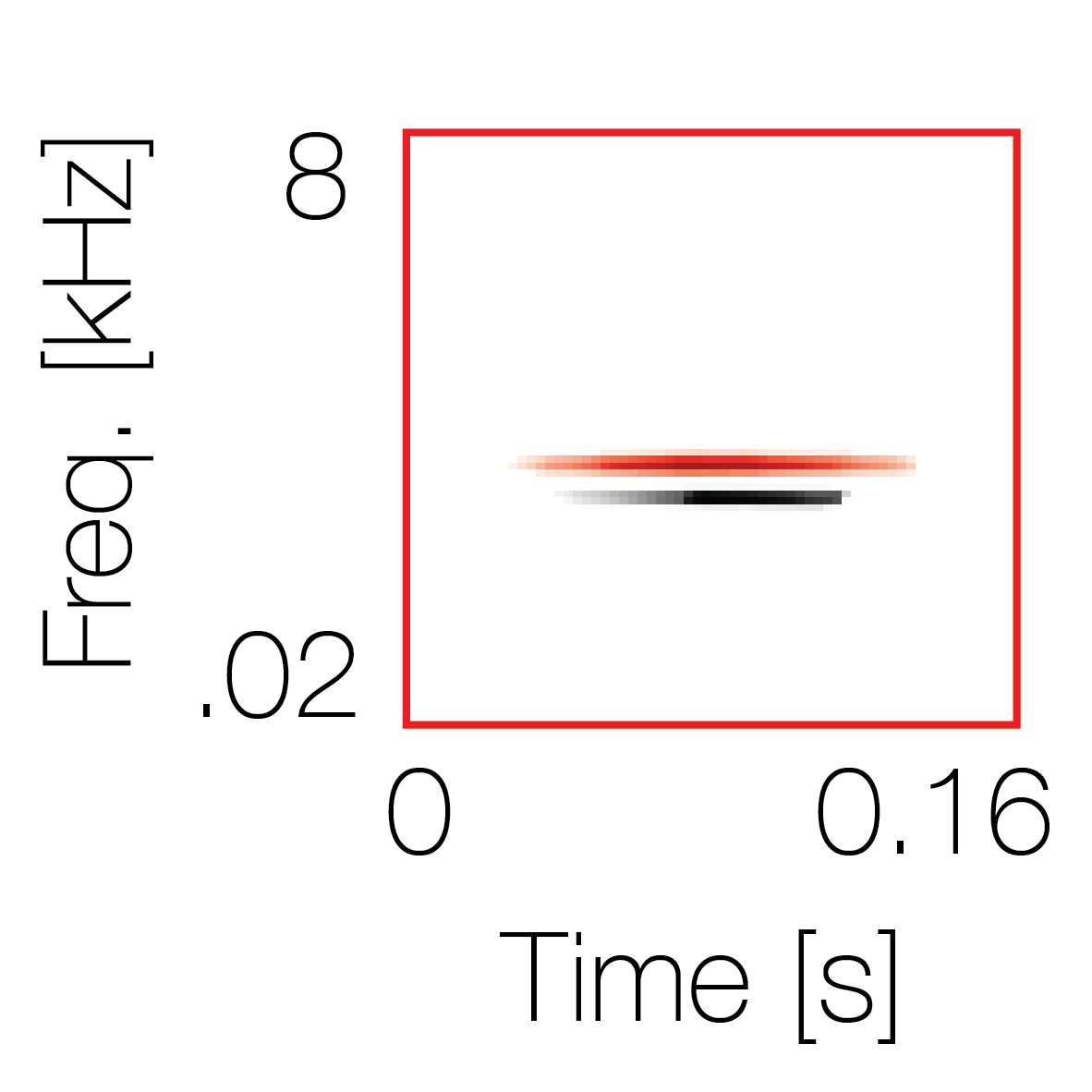
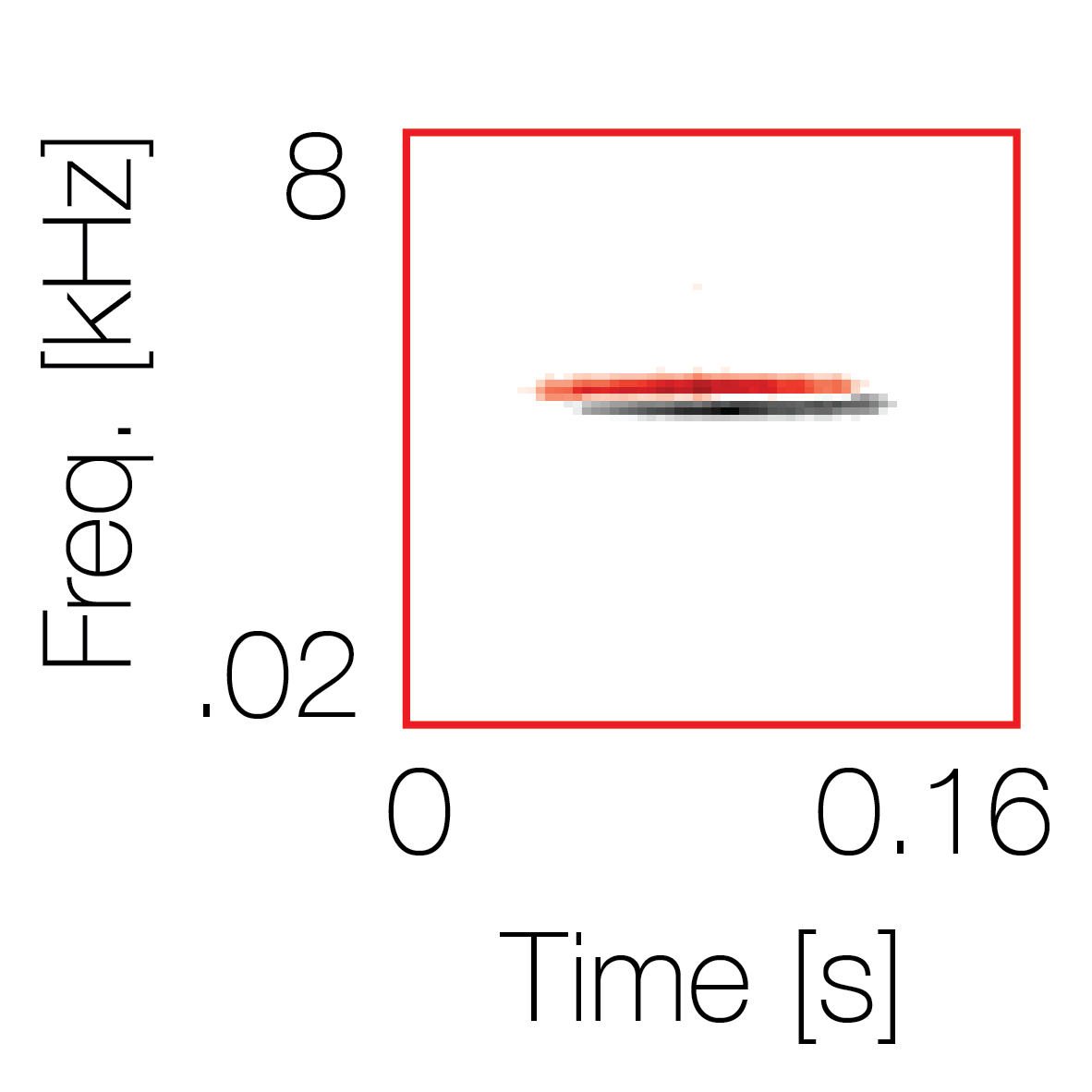
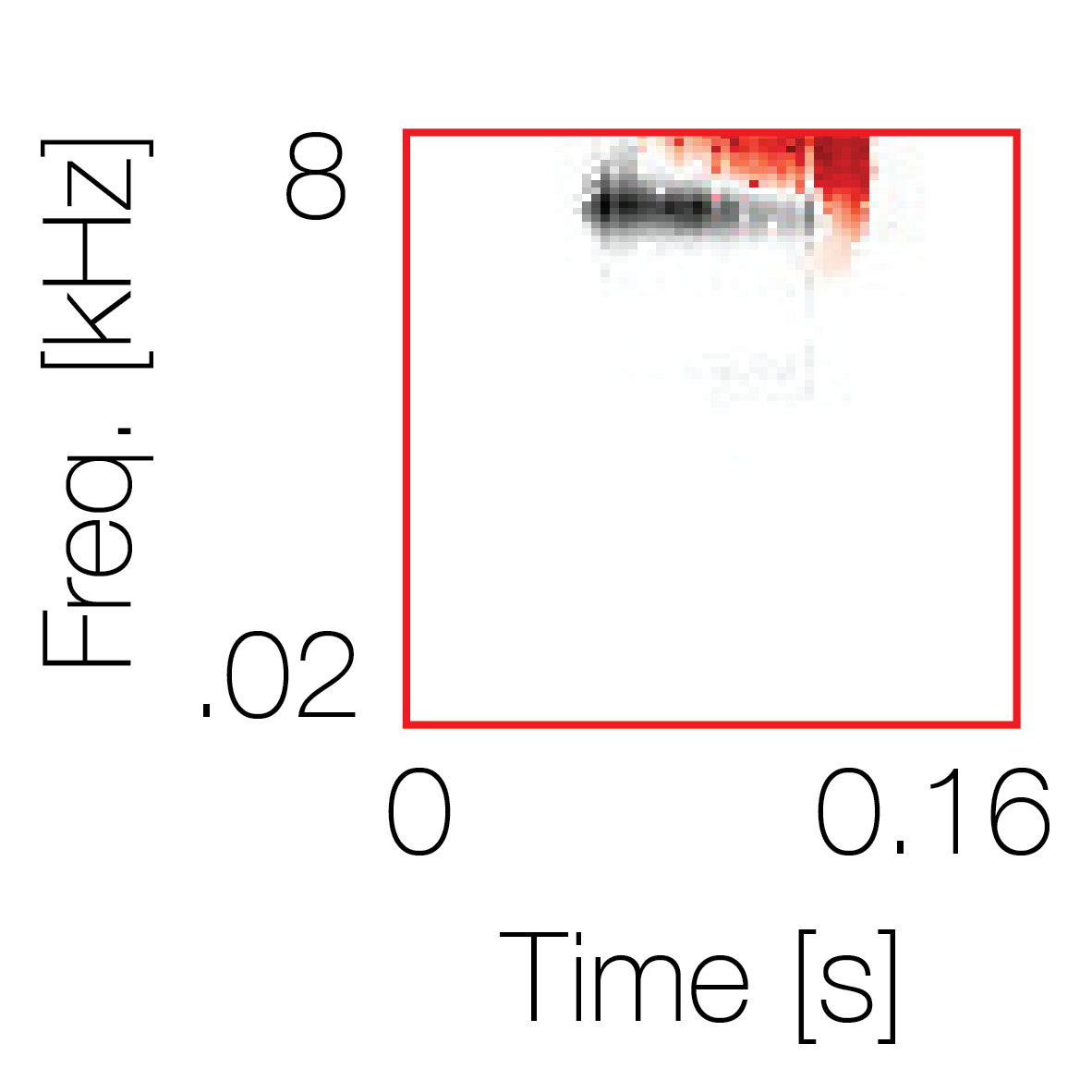
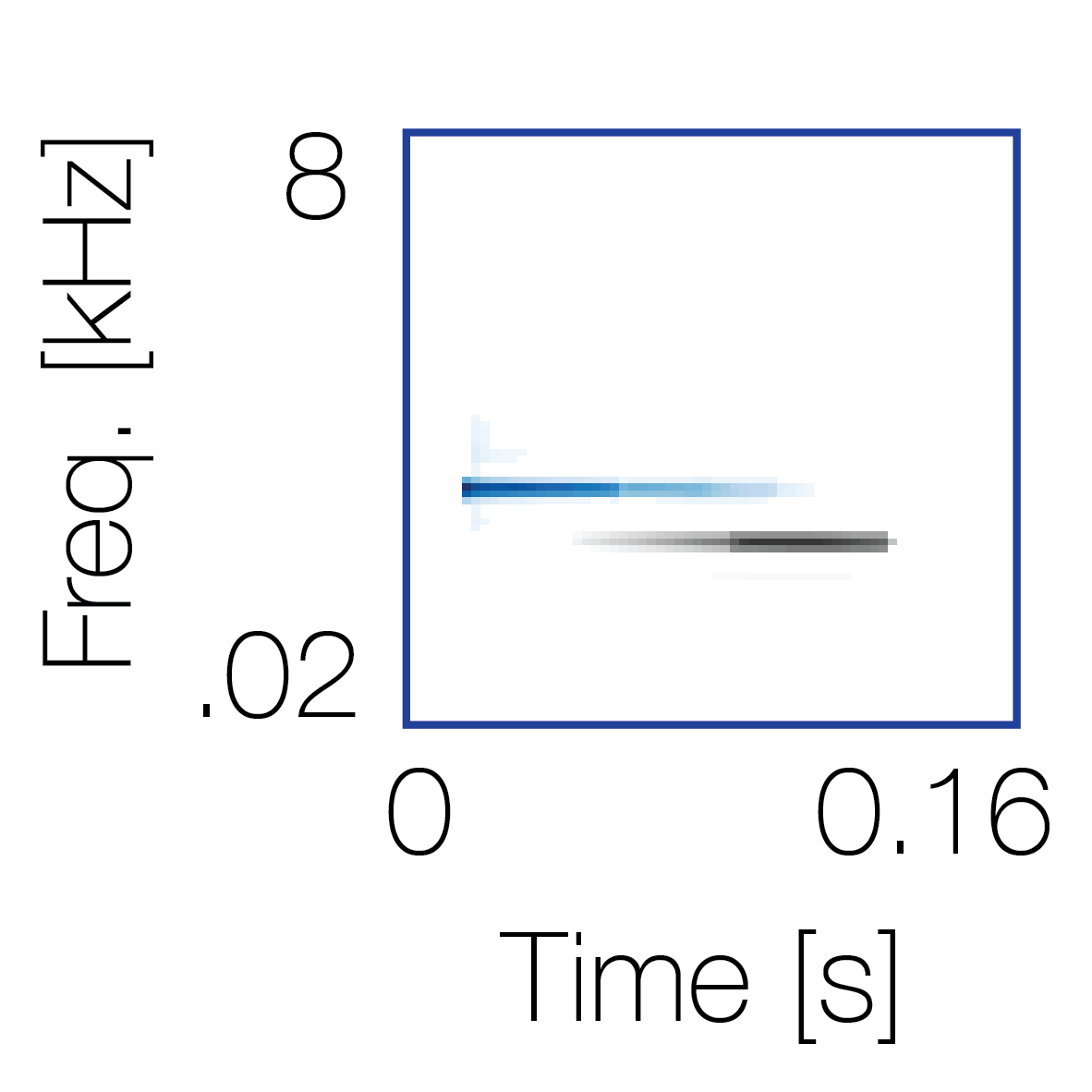
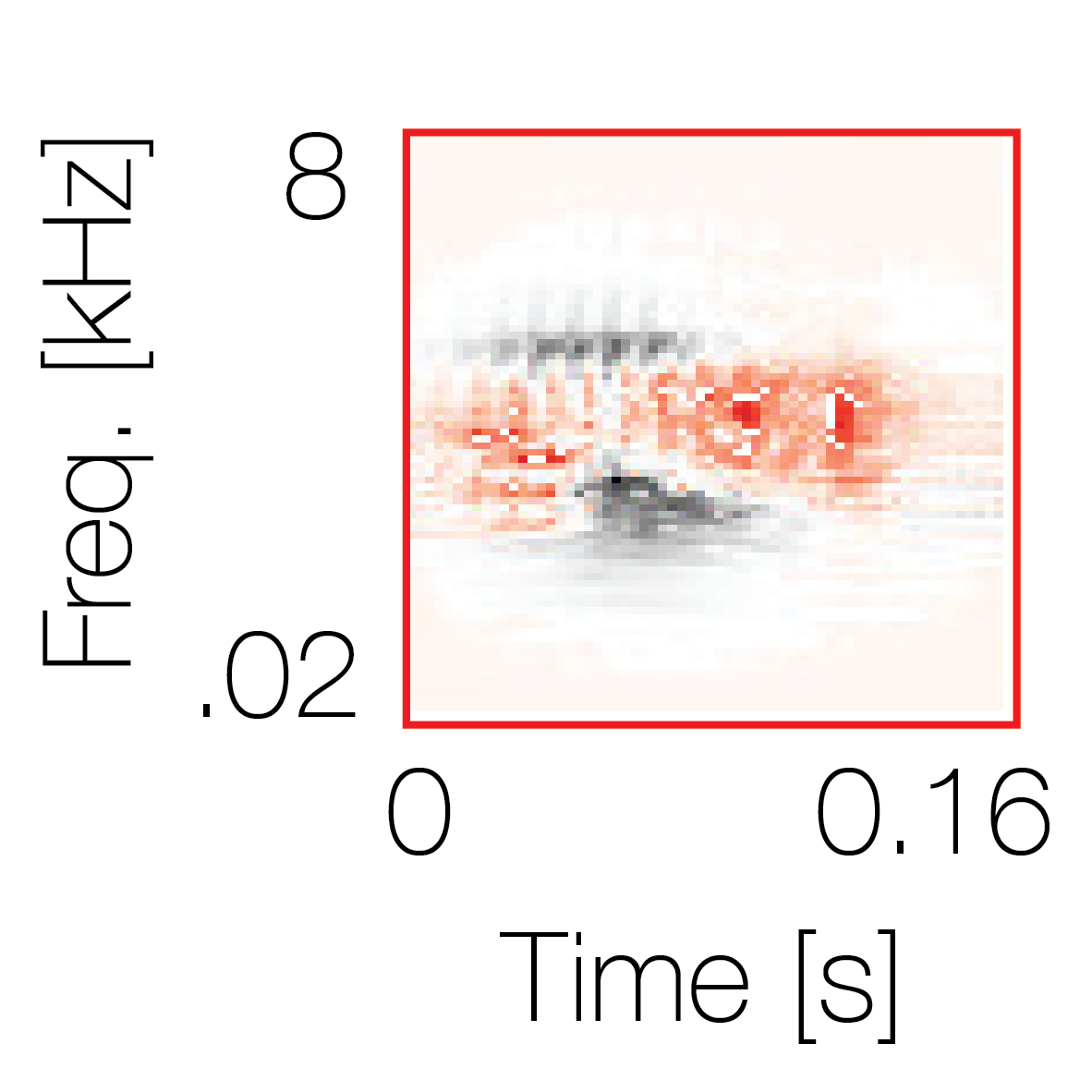
 Spectrotemporal cue 2
Spectrotemporal cue 2 Grouping feature mixtures (low cue value)All 4 cues have low values |
Non-grouping feature mixtures (high cue value)Remaining 3 cues have low values |
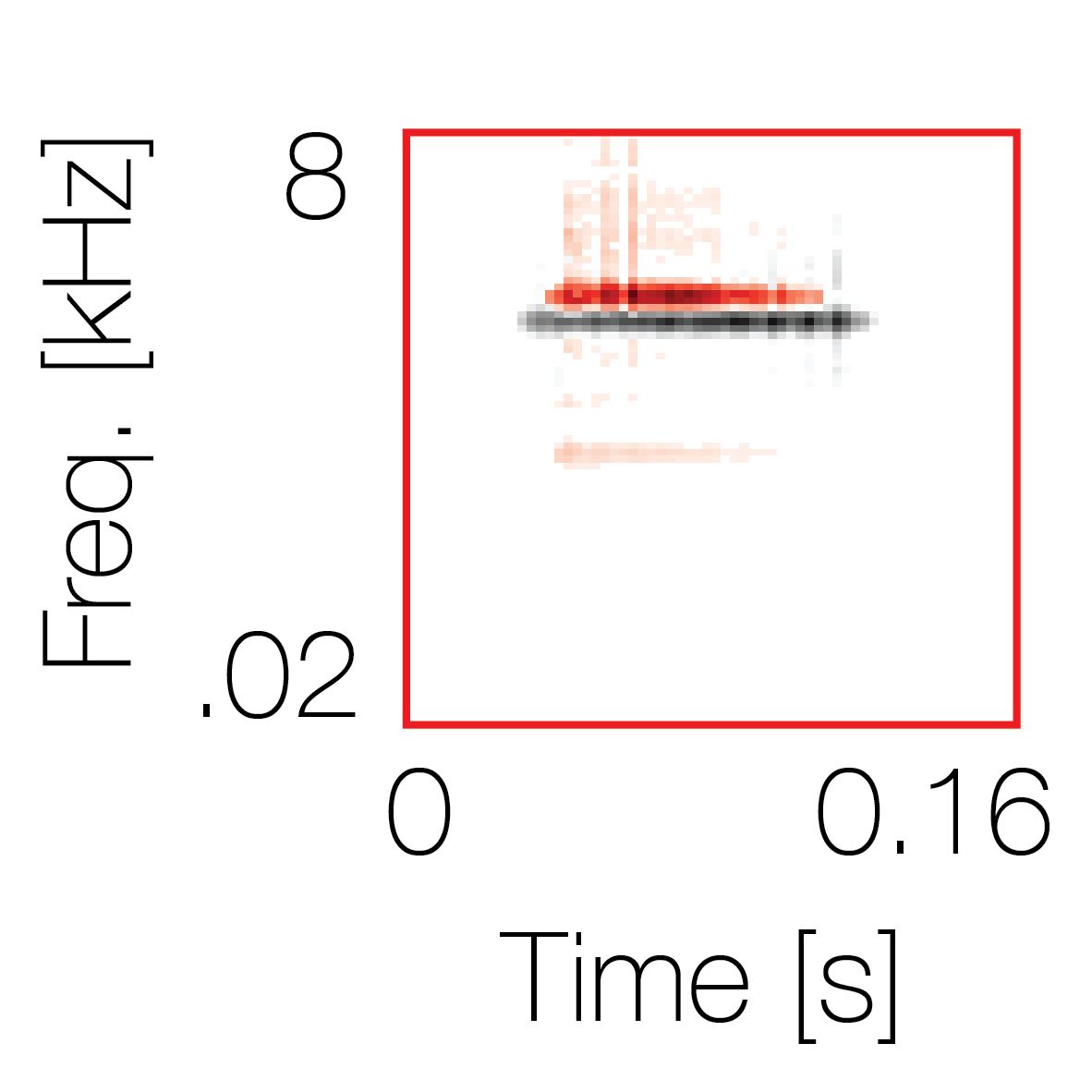
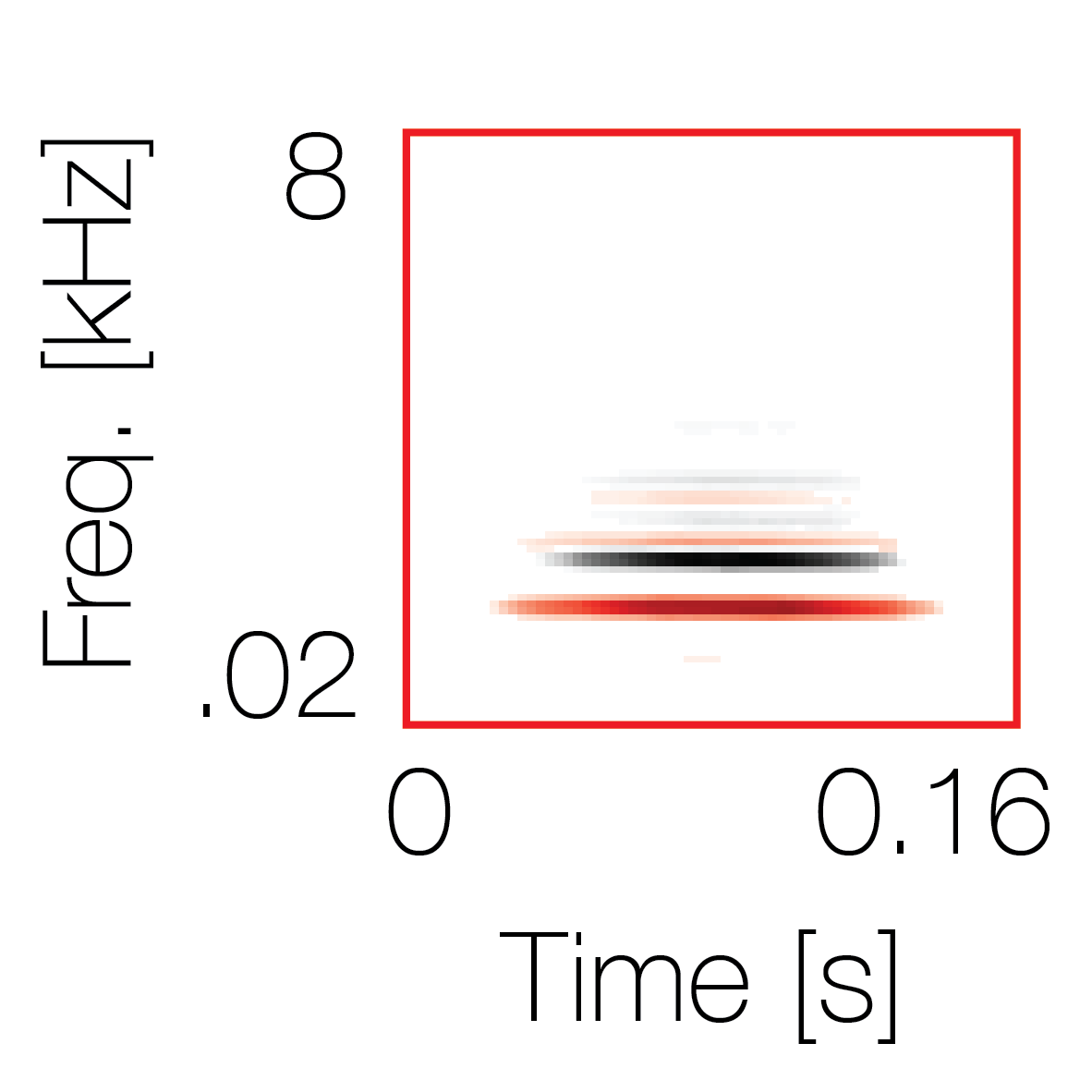
|
|
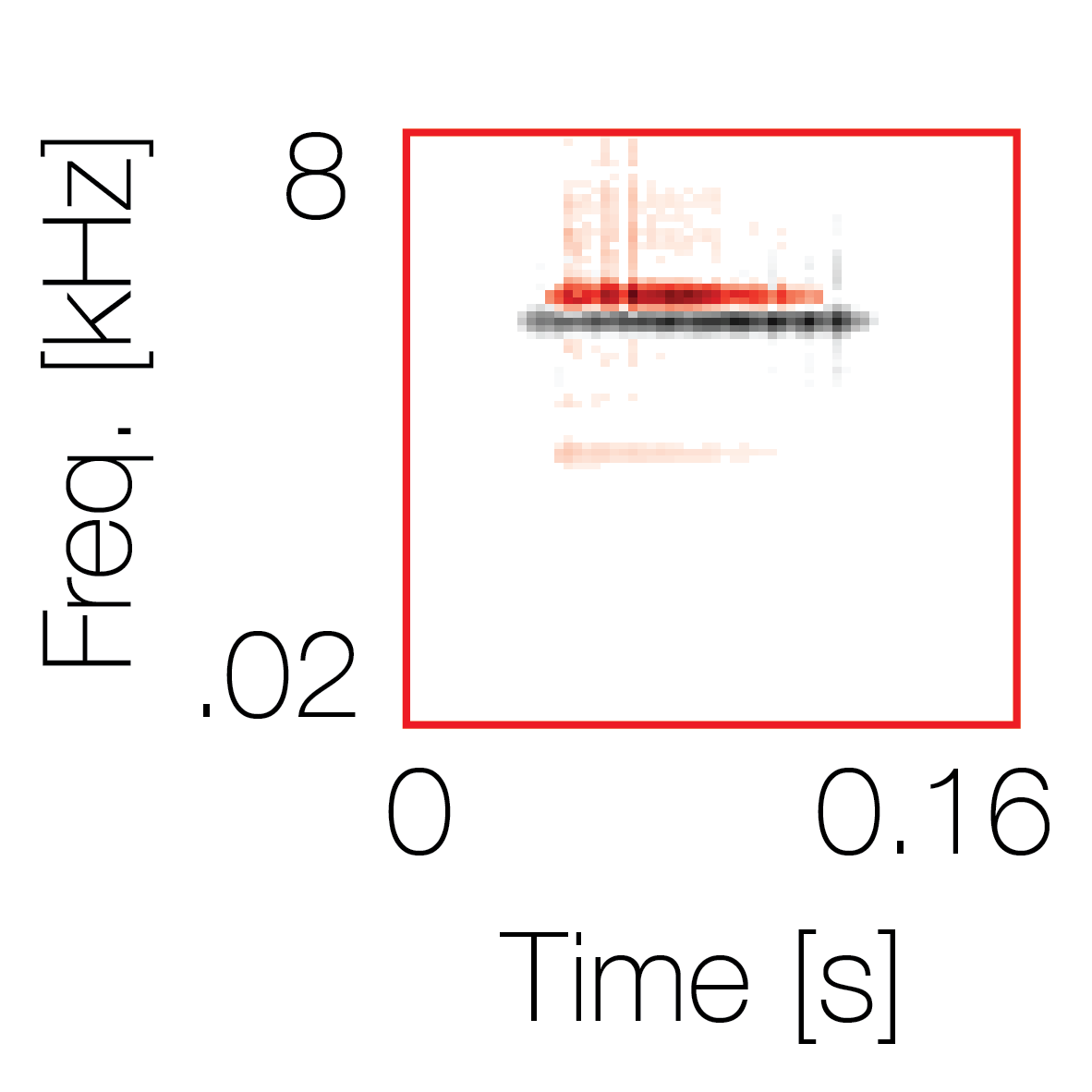
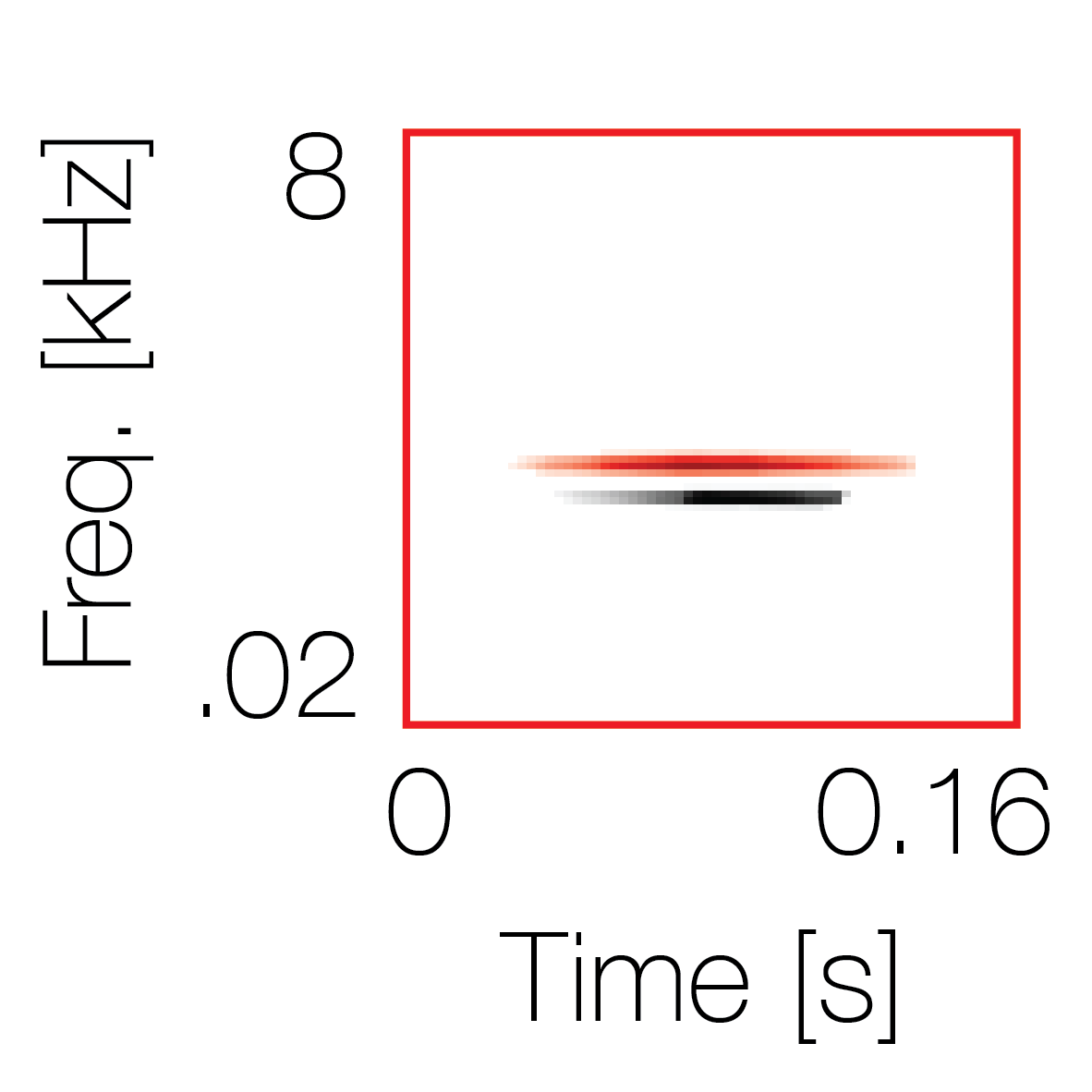
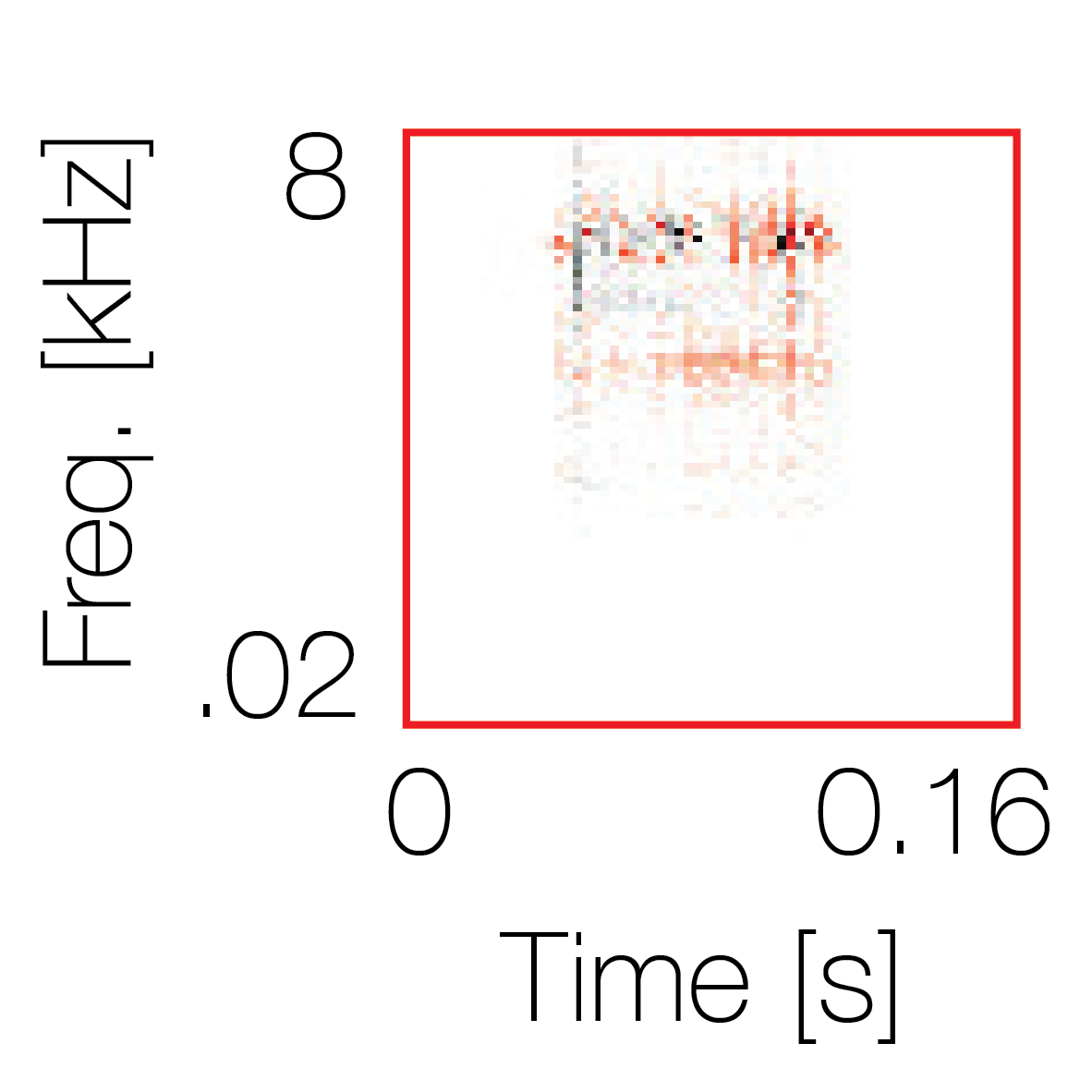
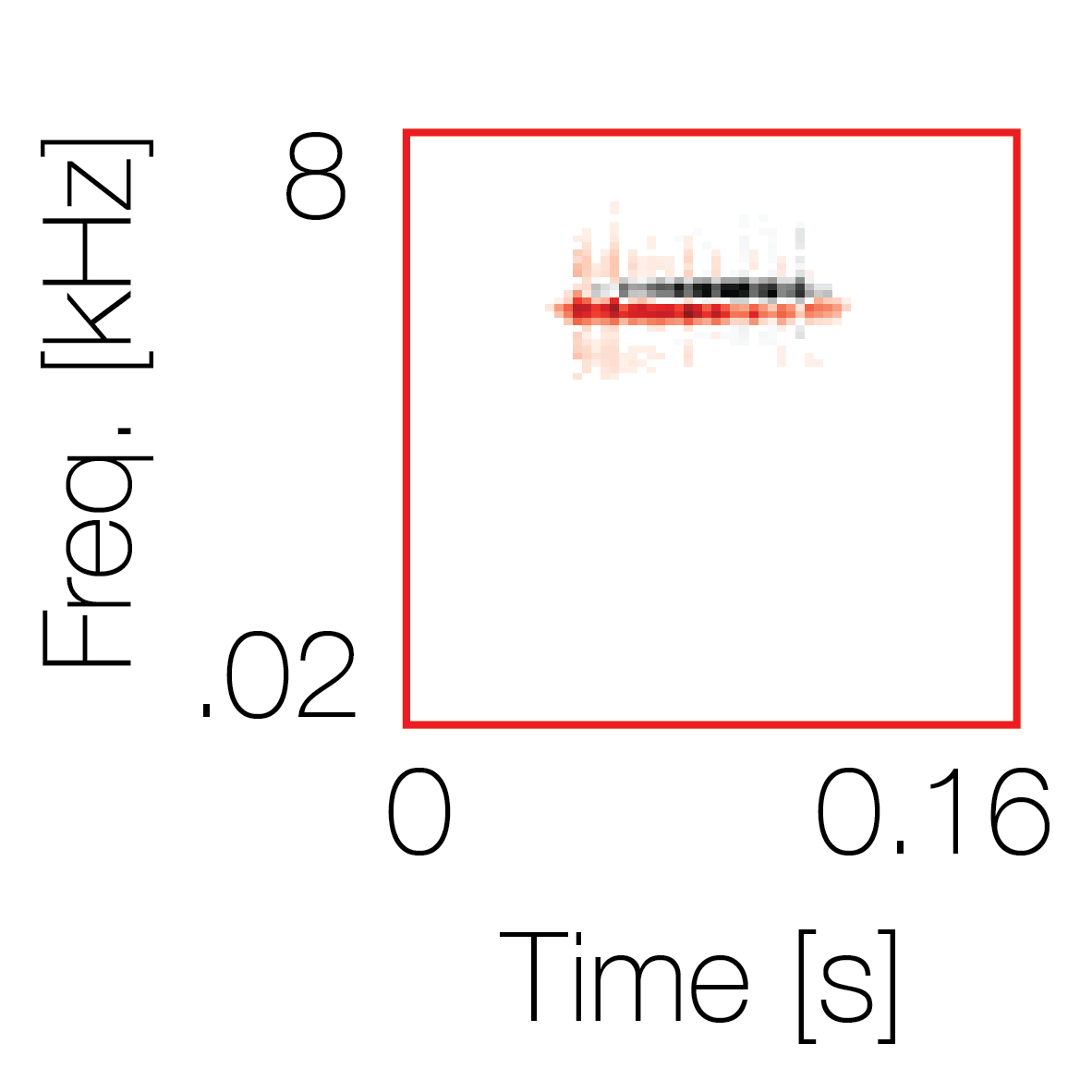
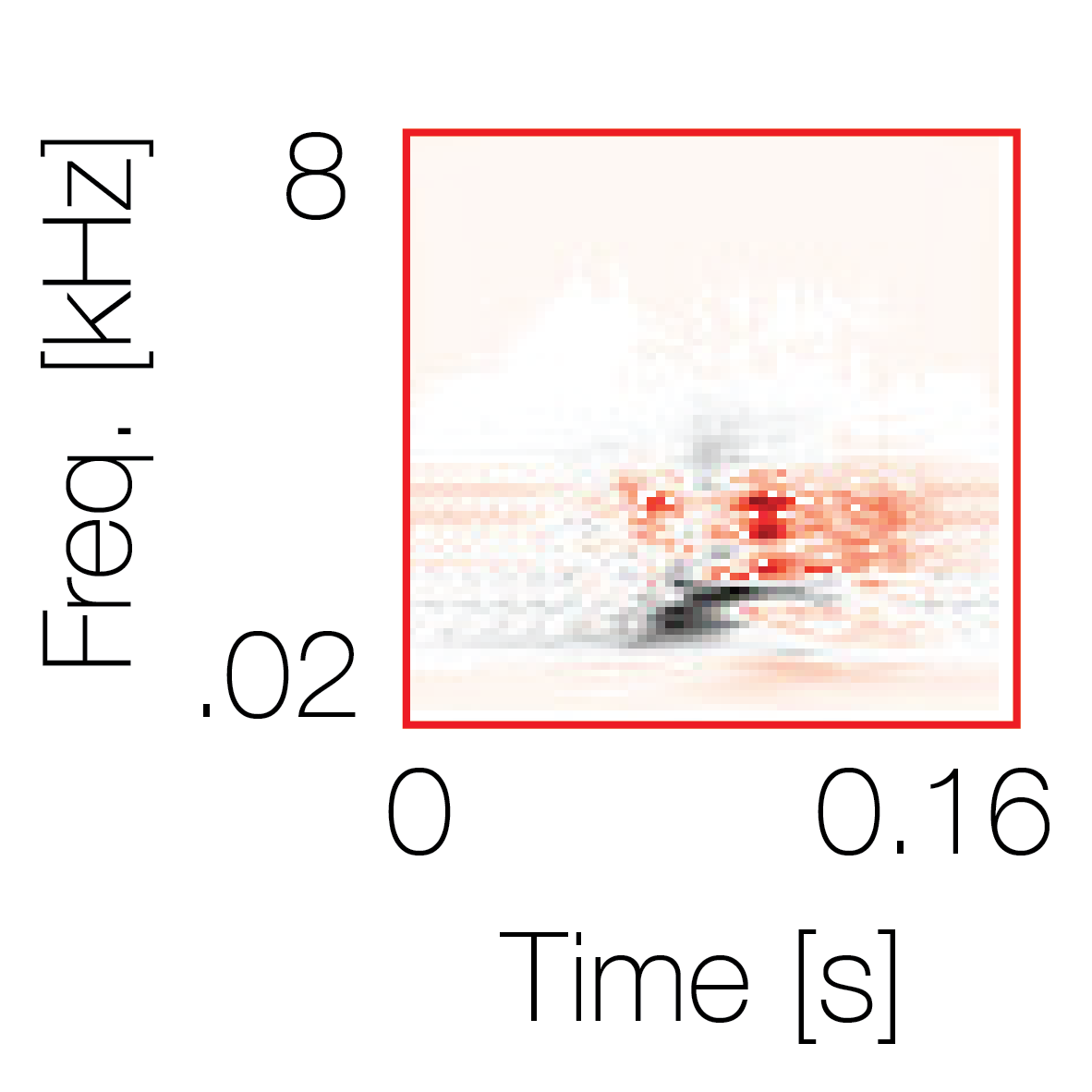
 Modulation cue 1
Modulation cue 1 Grouping feature mixtures (low cue value)All 4 cues have low values |
Non-grouping feature mixtures (high cue value)Remaining 3 cues have low values |
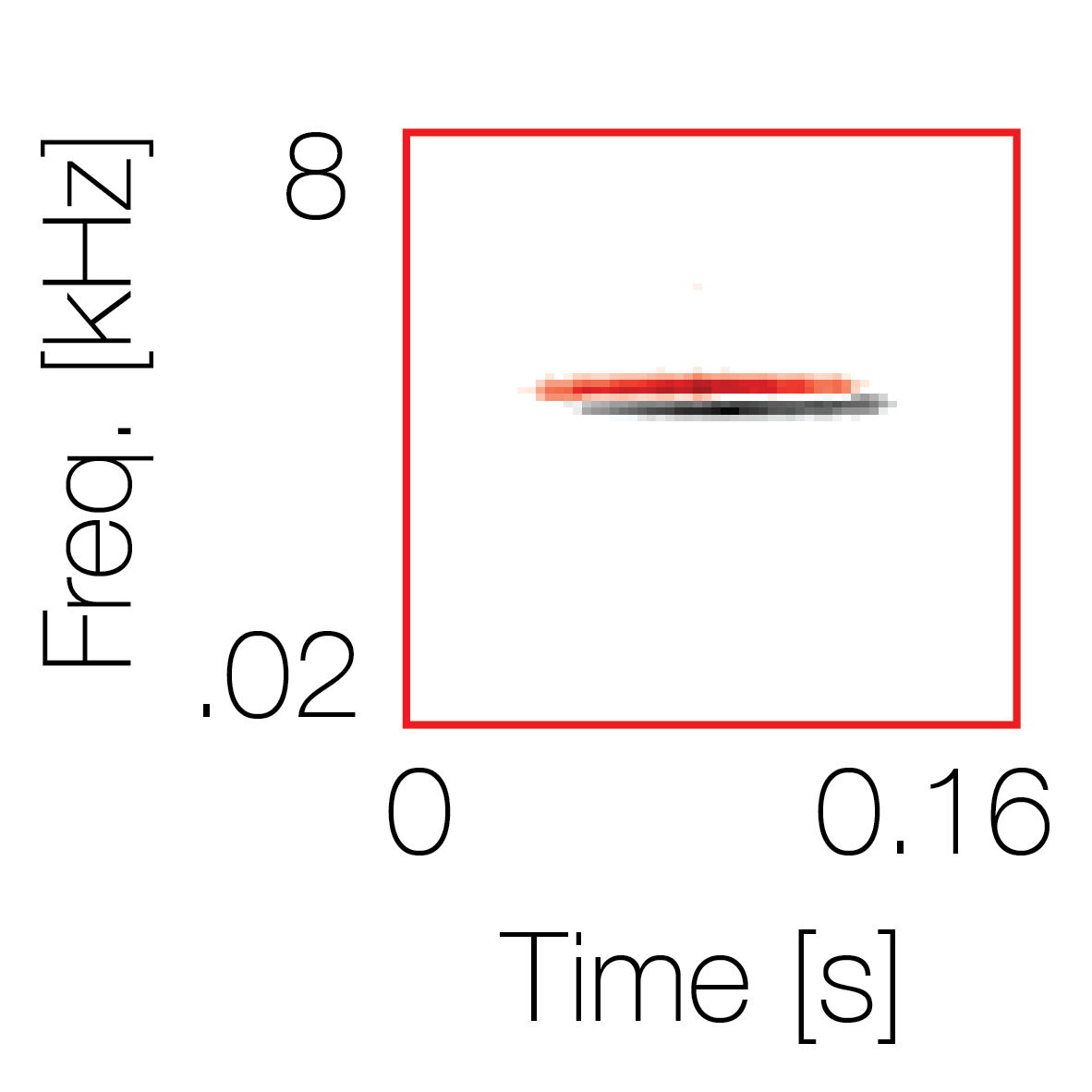
|
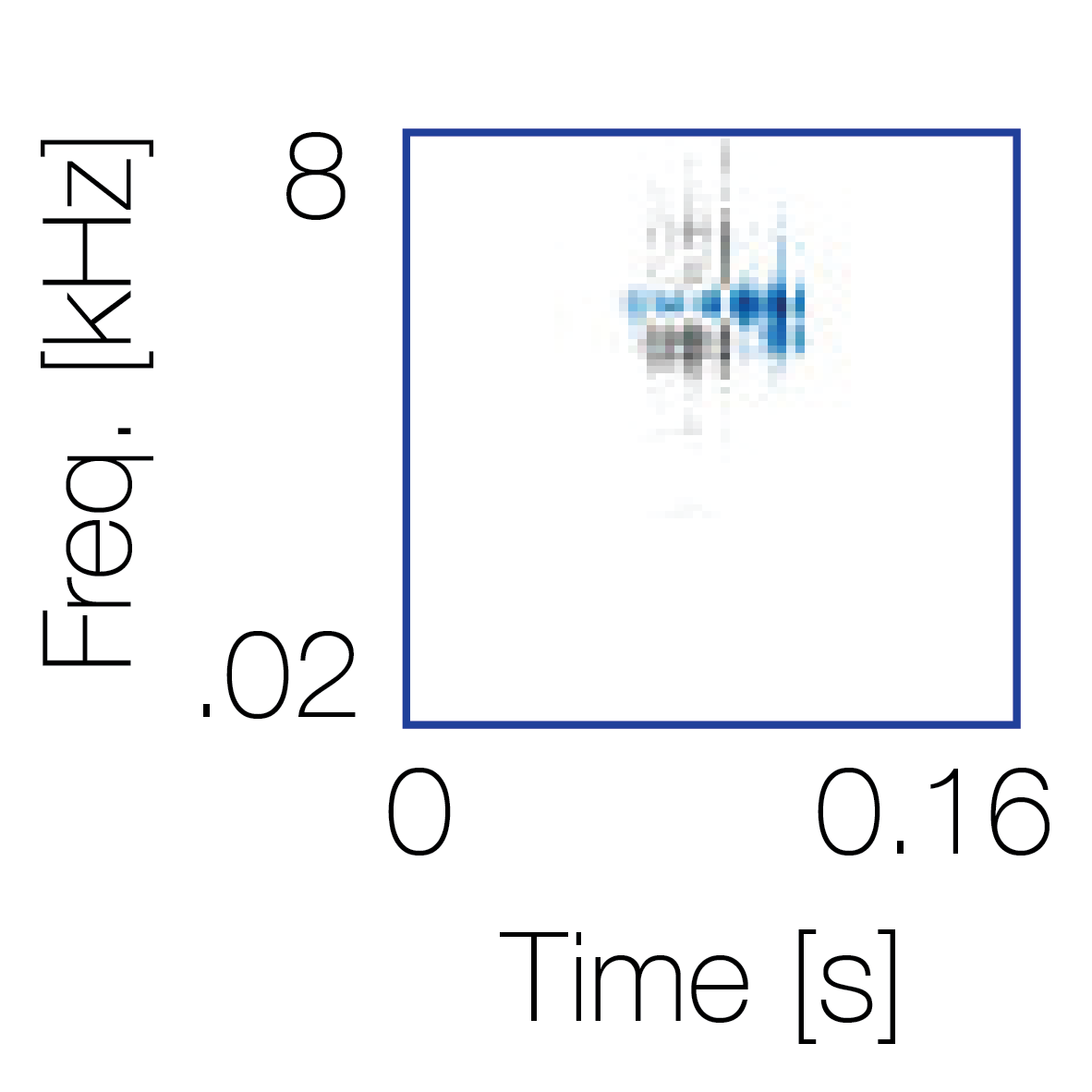
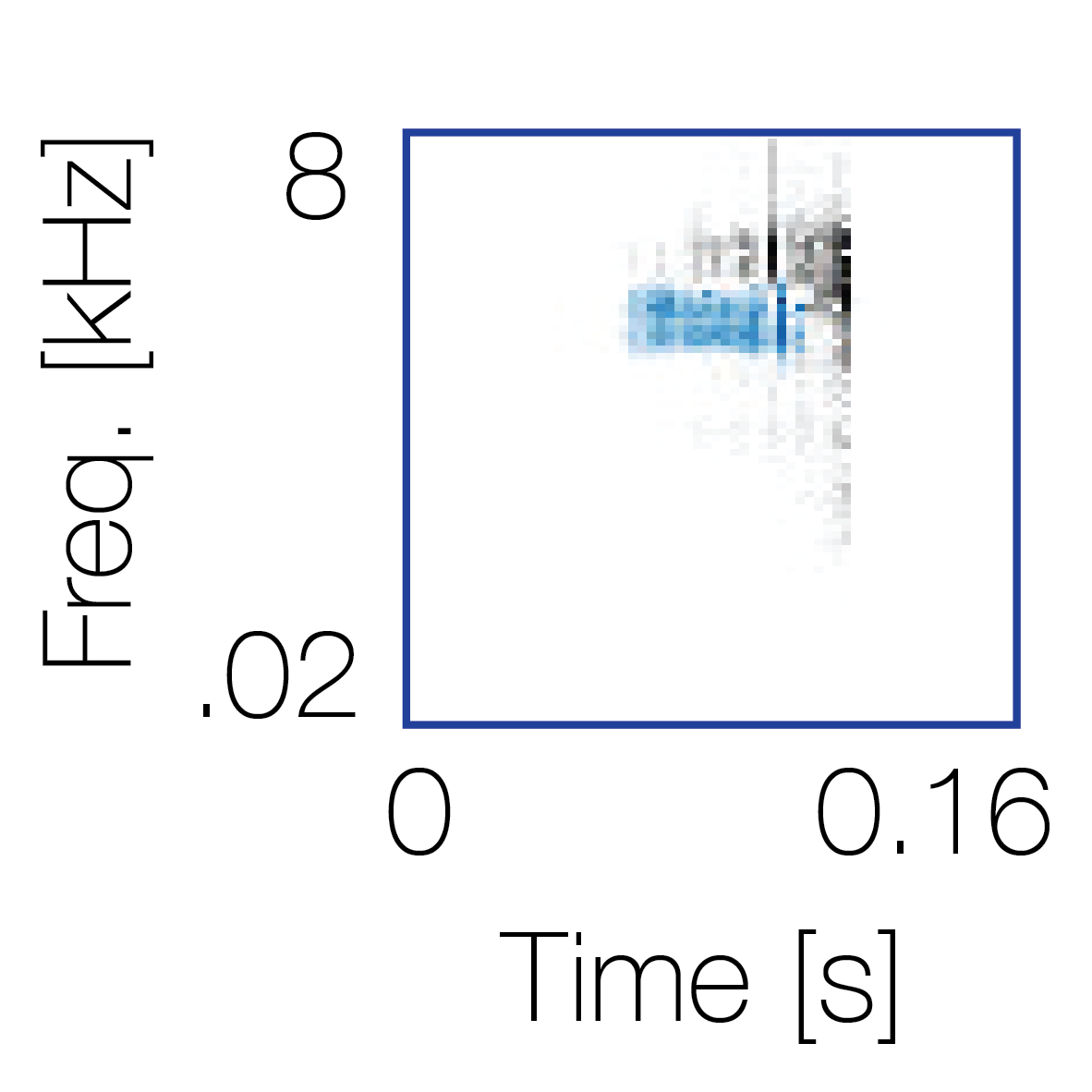
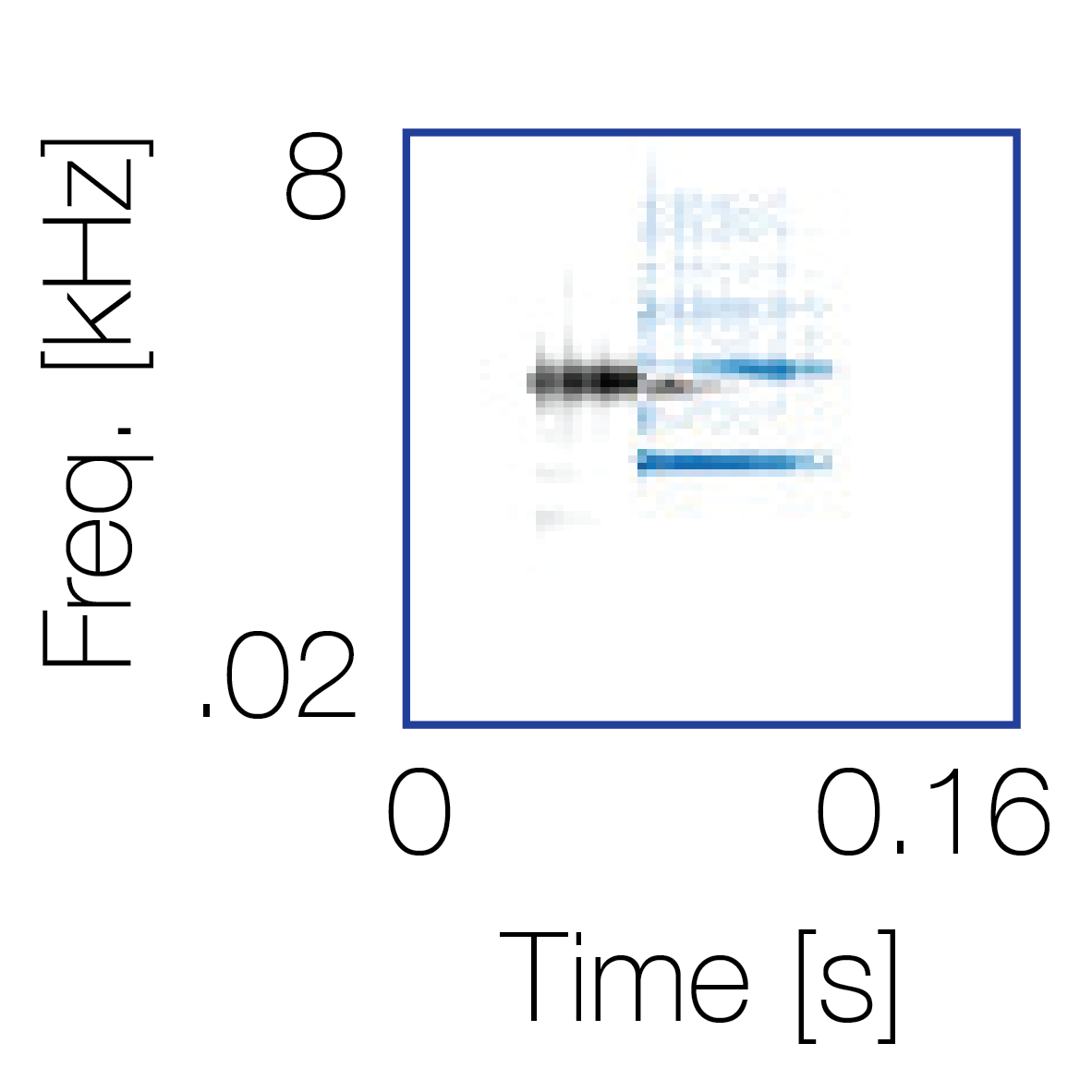
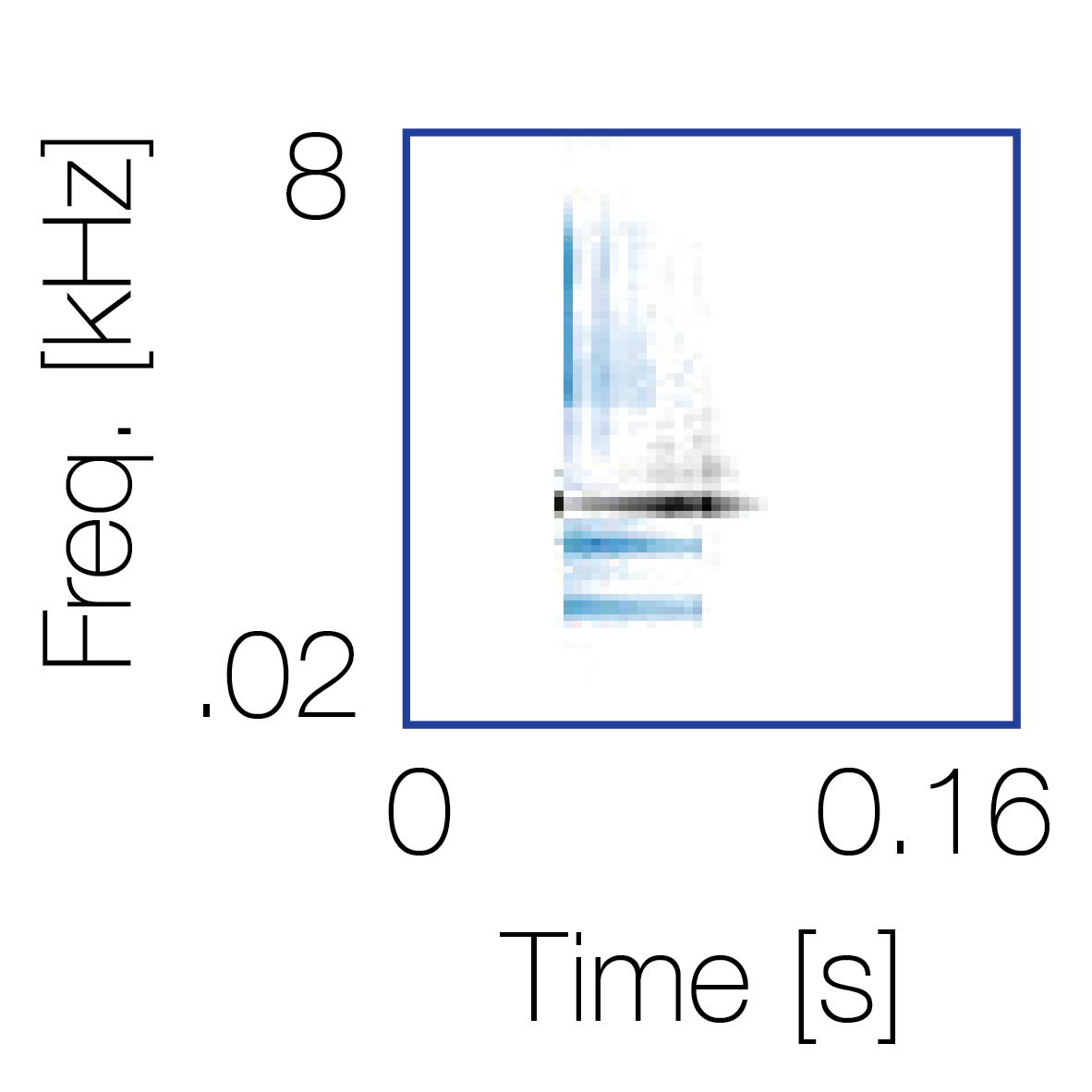
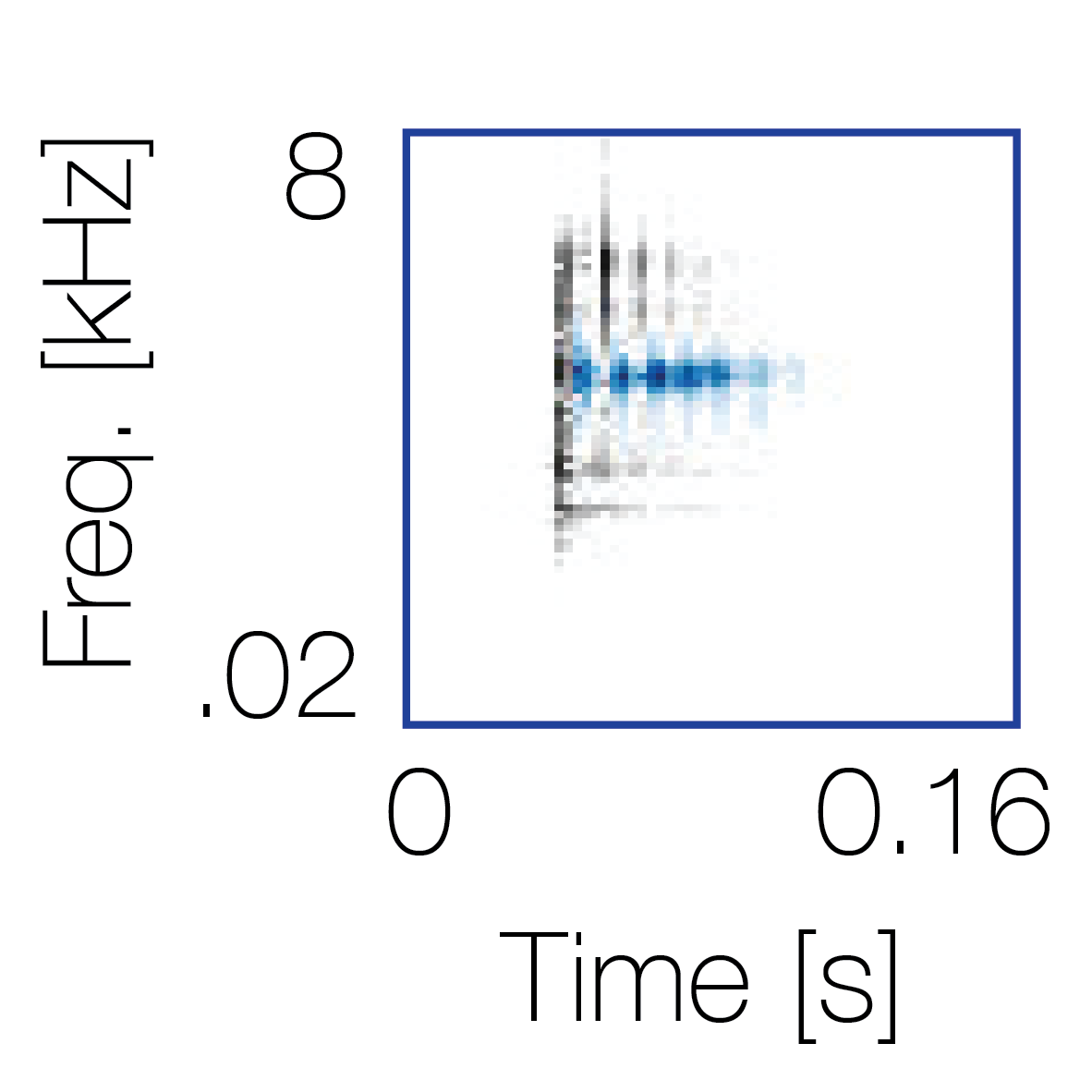
|
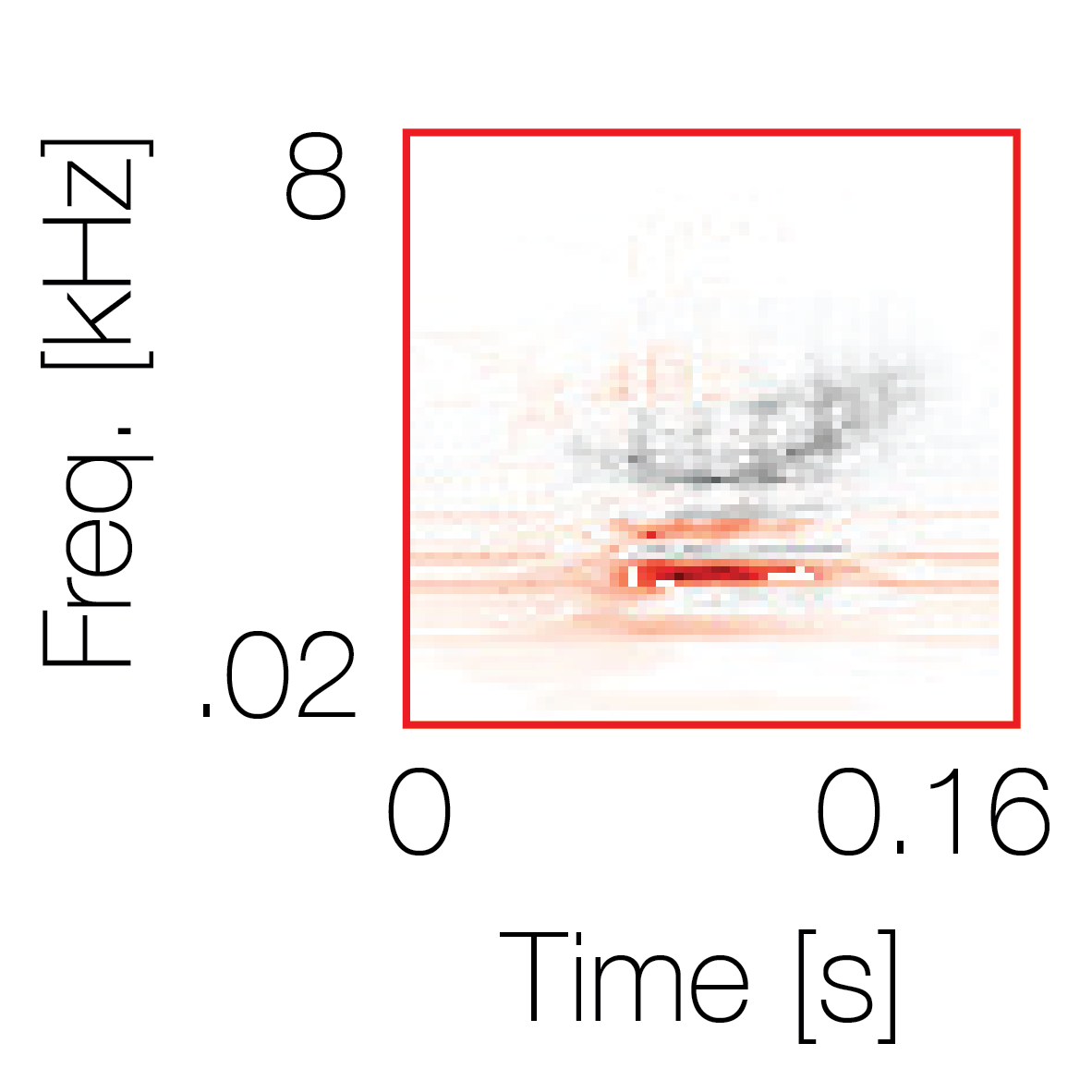
 Modulation cue 2
Modulation cue 2 Grouping feature mixtures (low cue value)All 4 cues have low values |
Non-grouping feature mixtures (high cue value)Remaining 3 cues have low values |
|
|
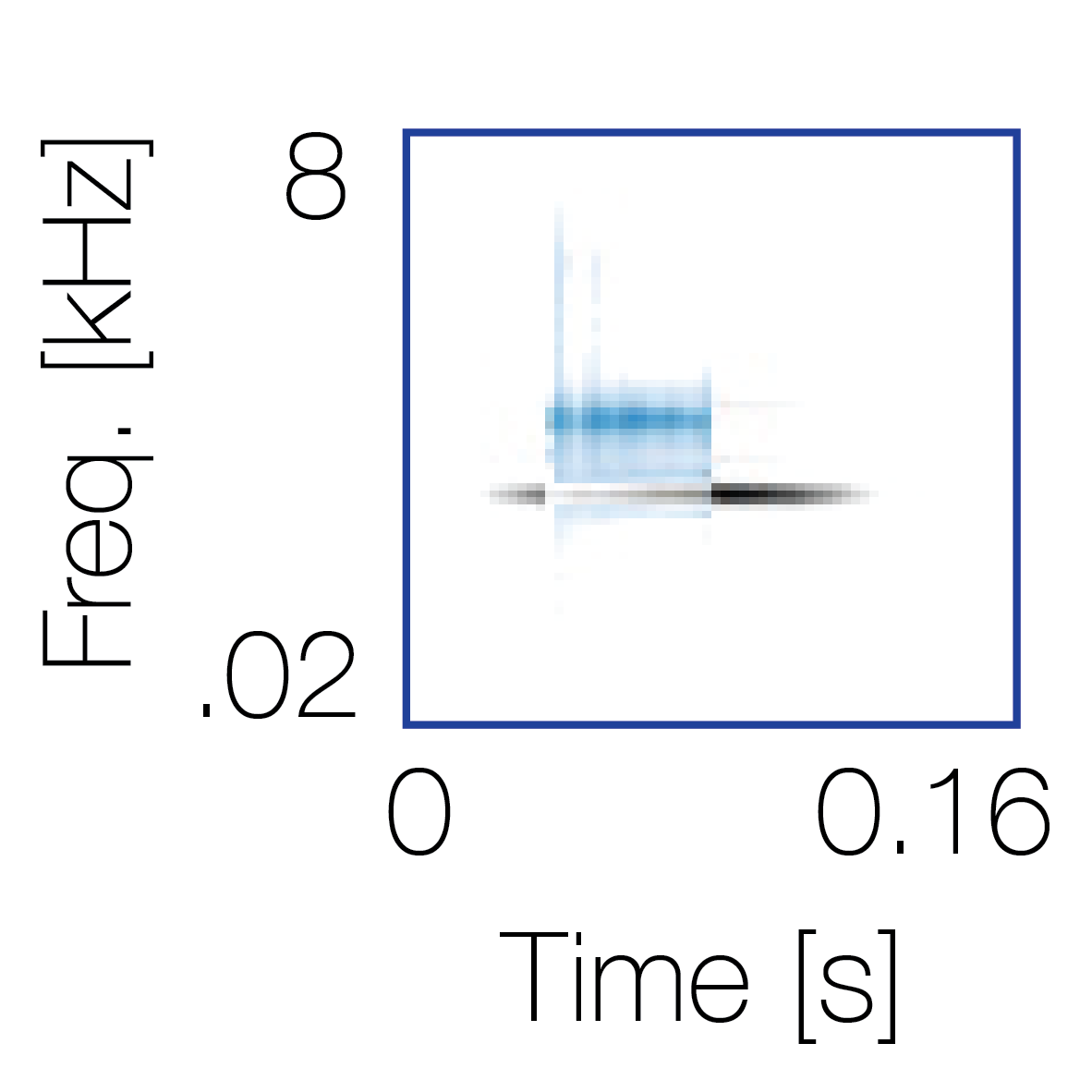
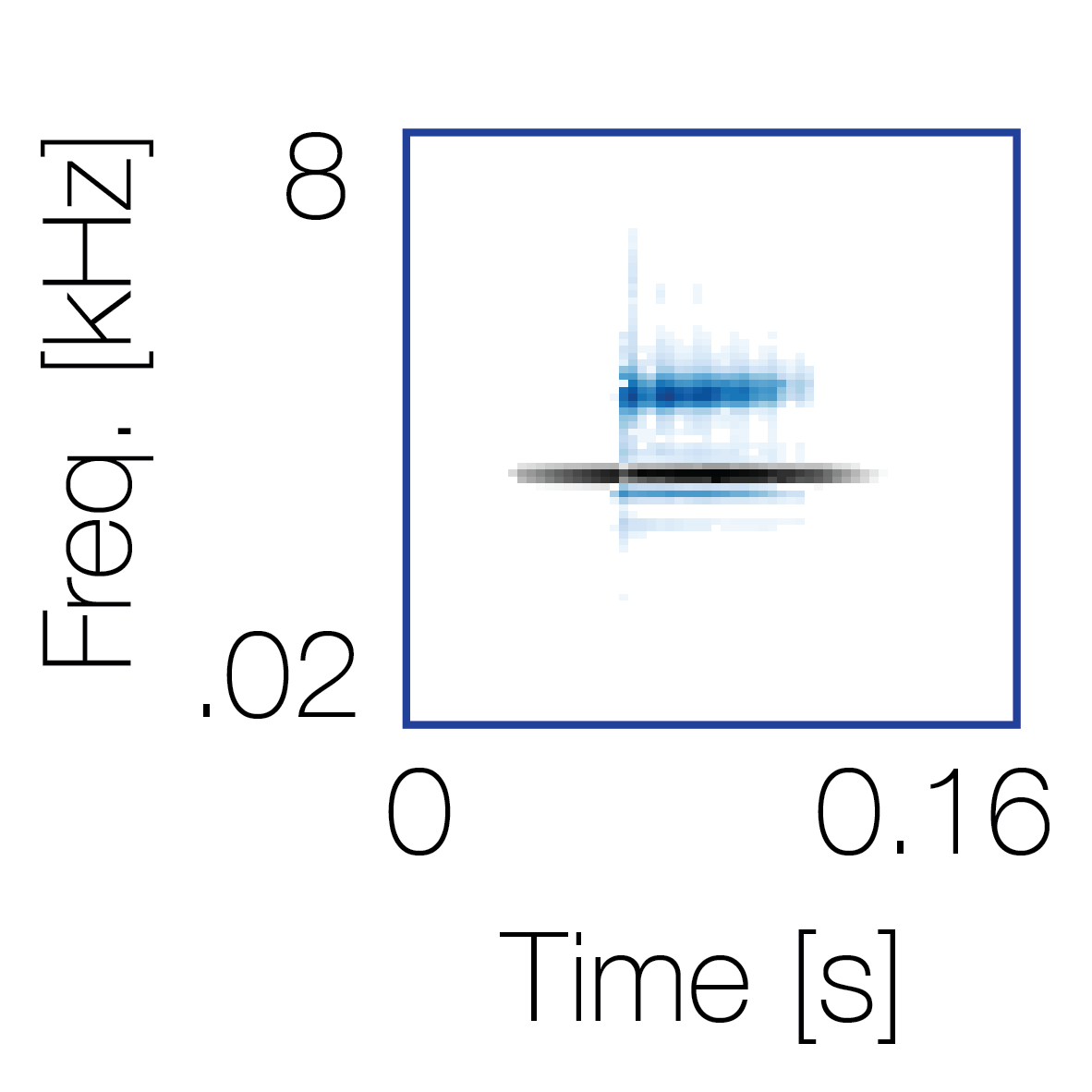
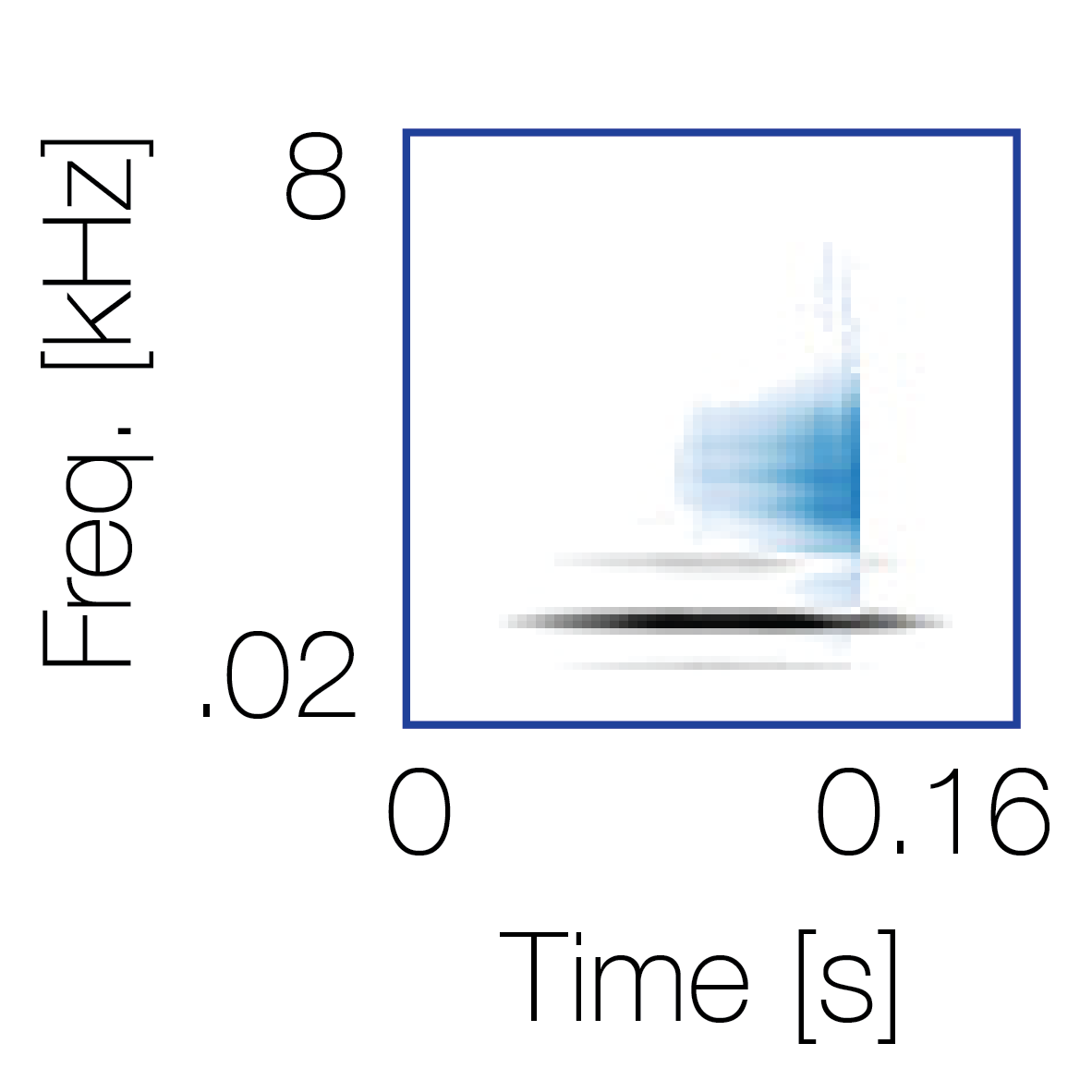
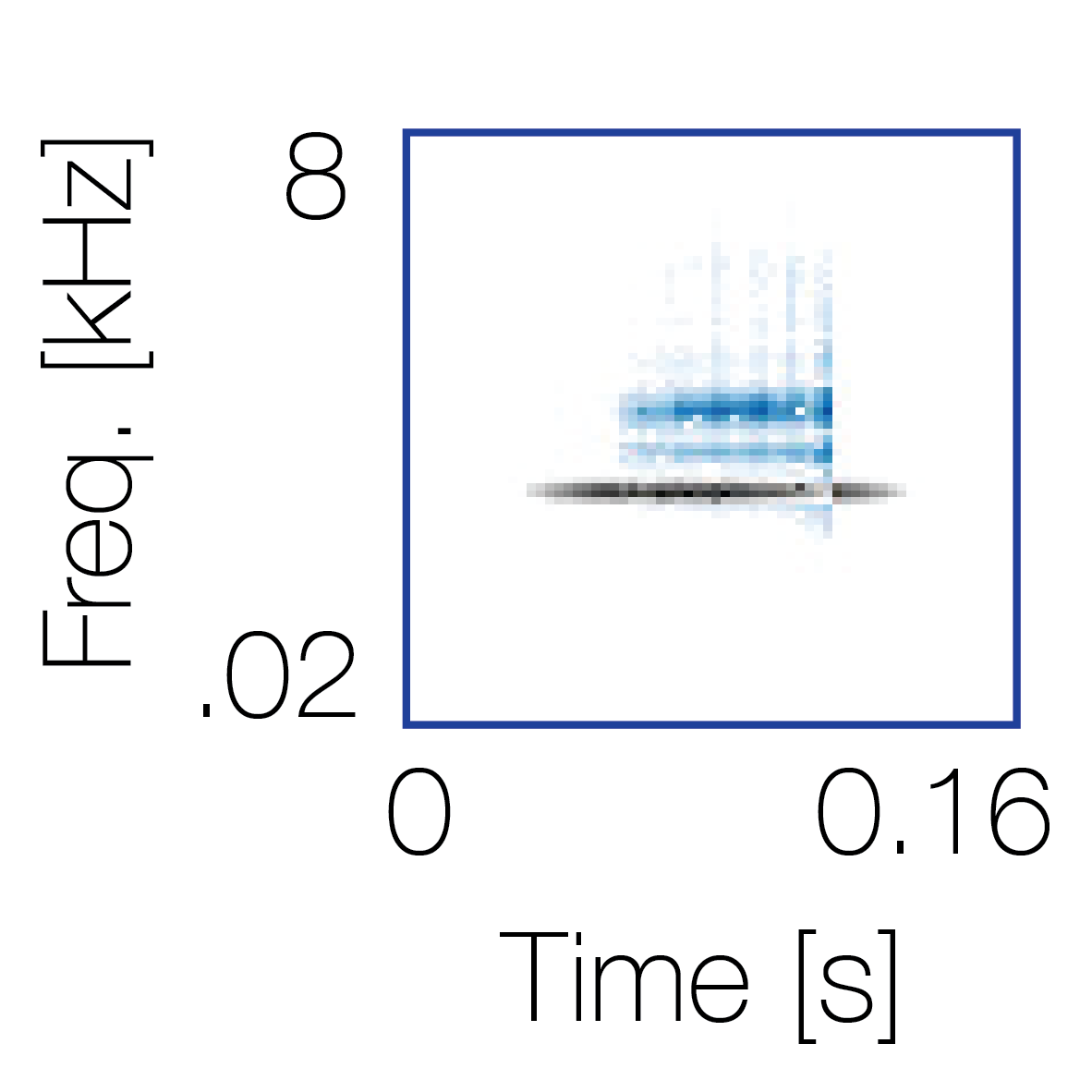
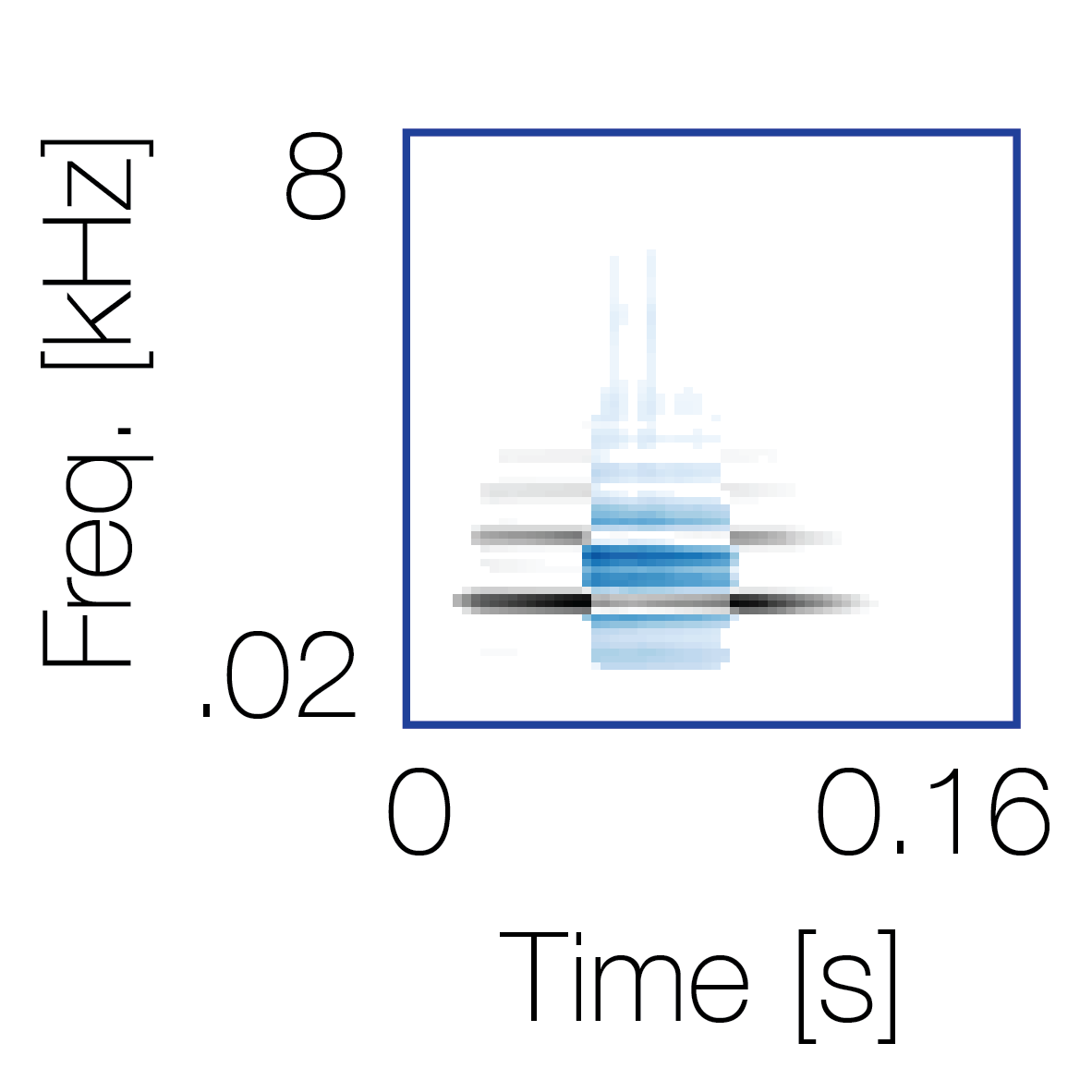
|
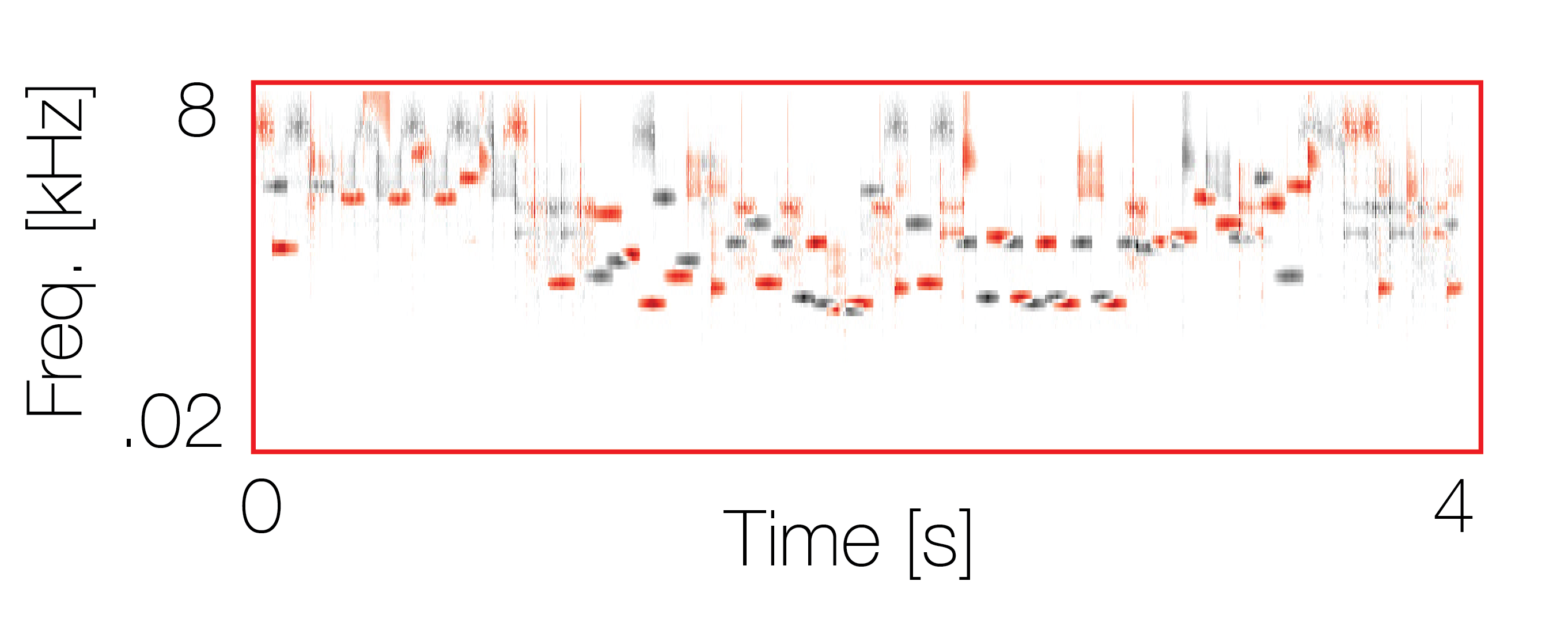
Sound pairs classified as a single source |
Sound pairs classified as different sources |
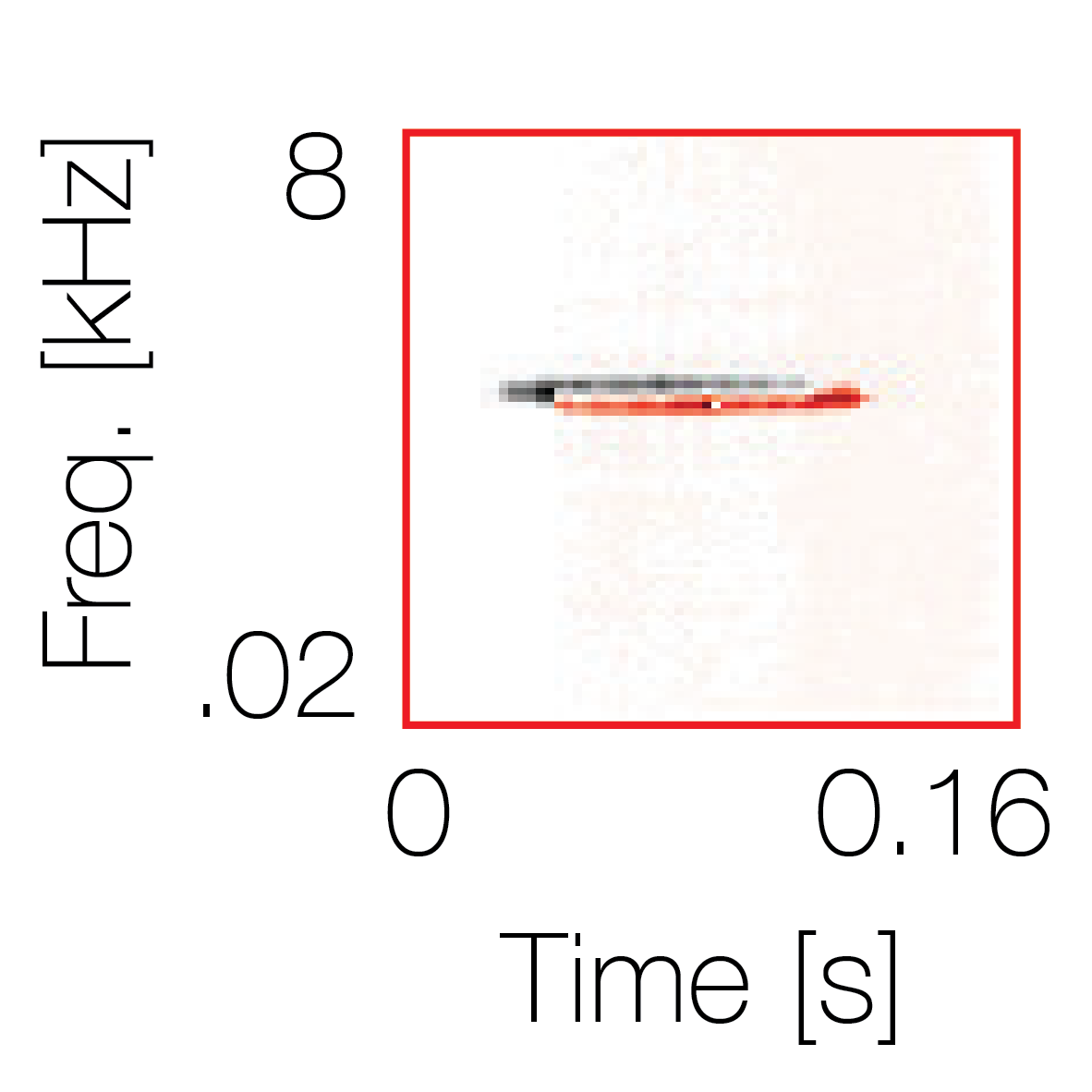
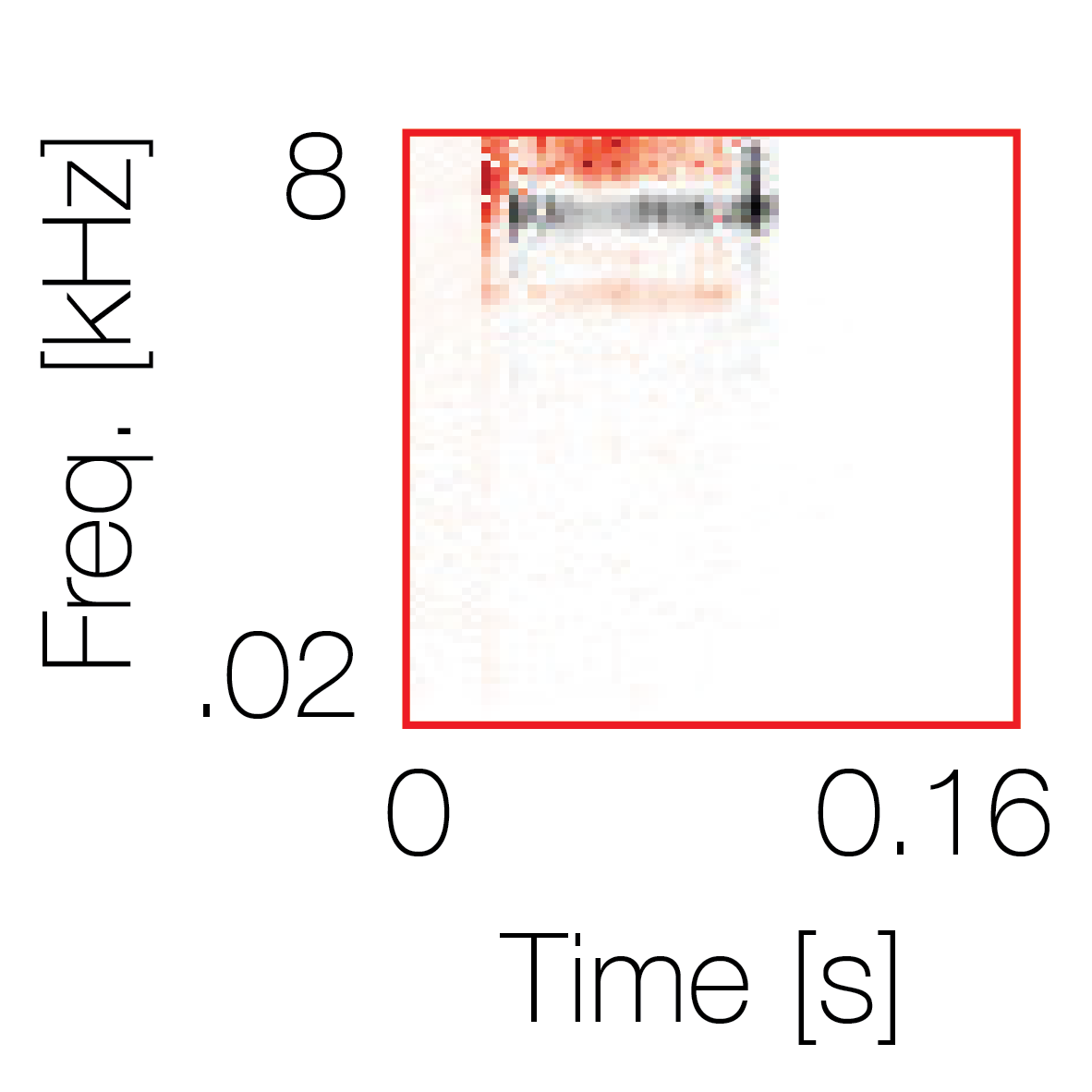
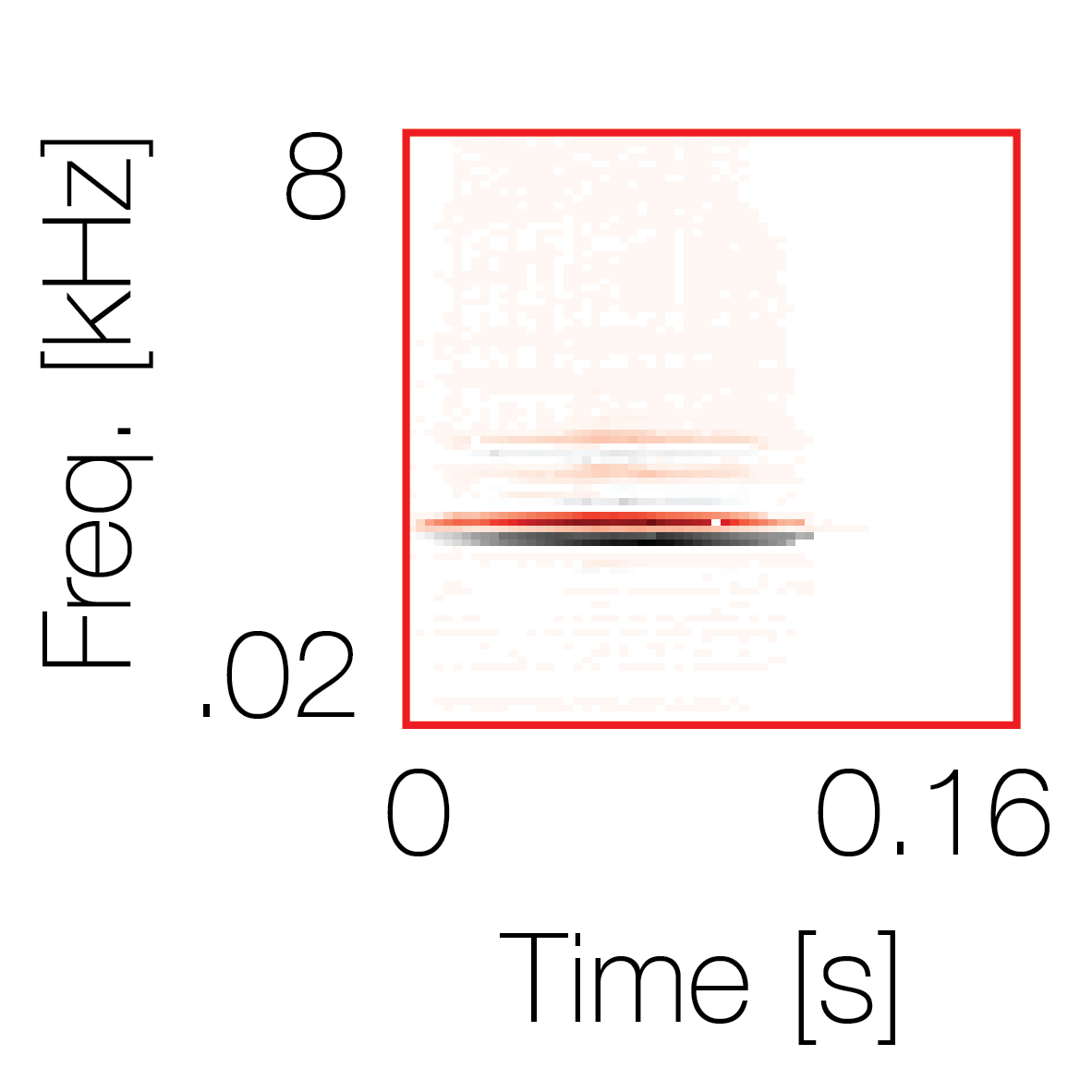
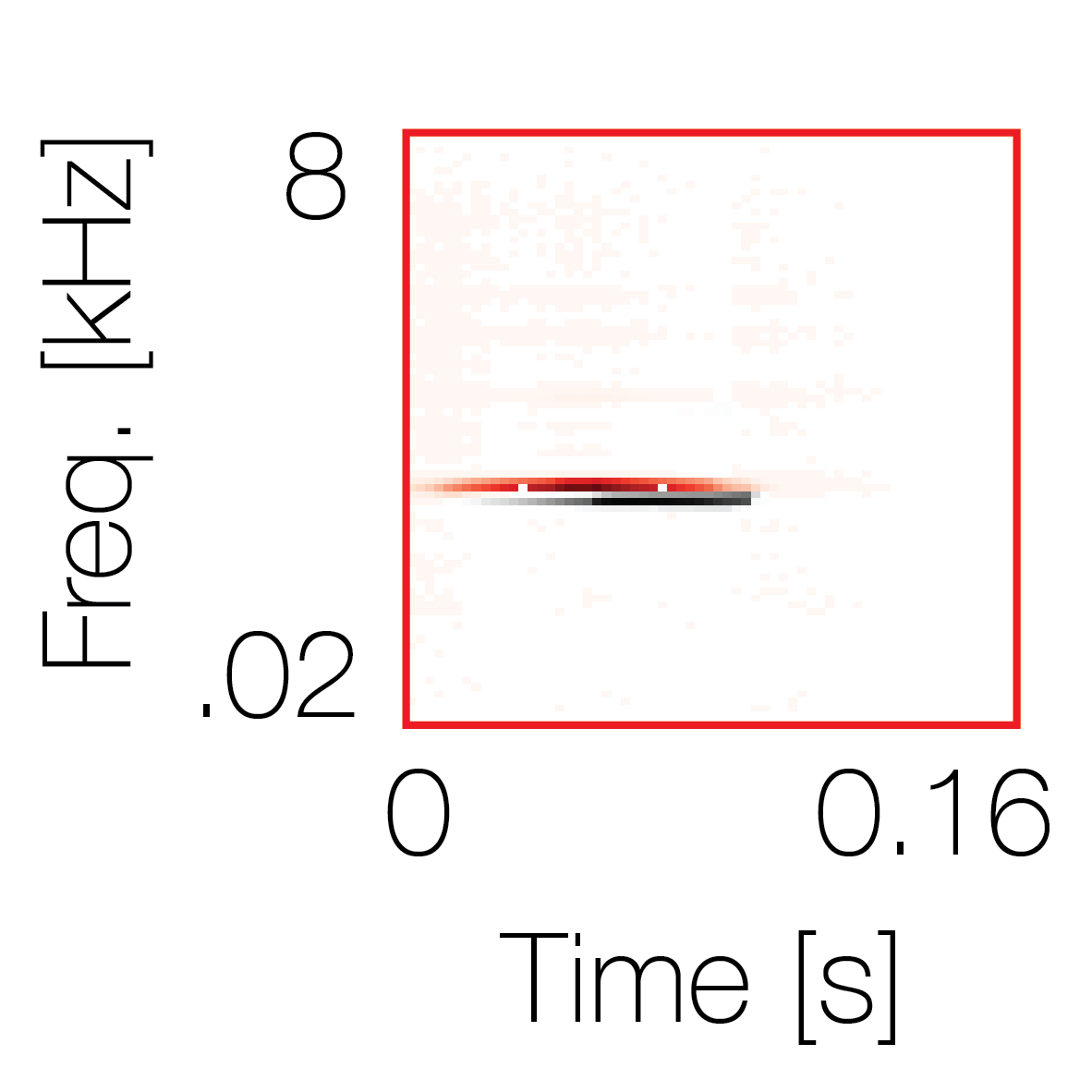
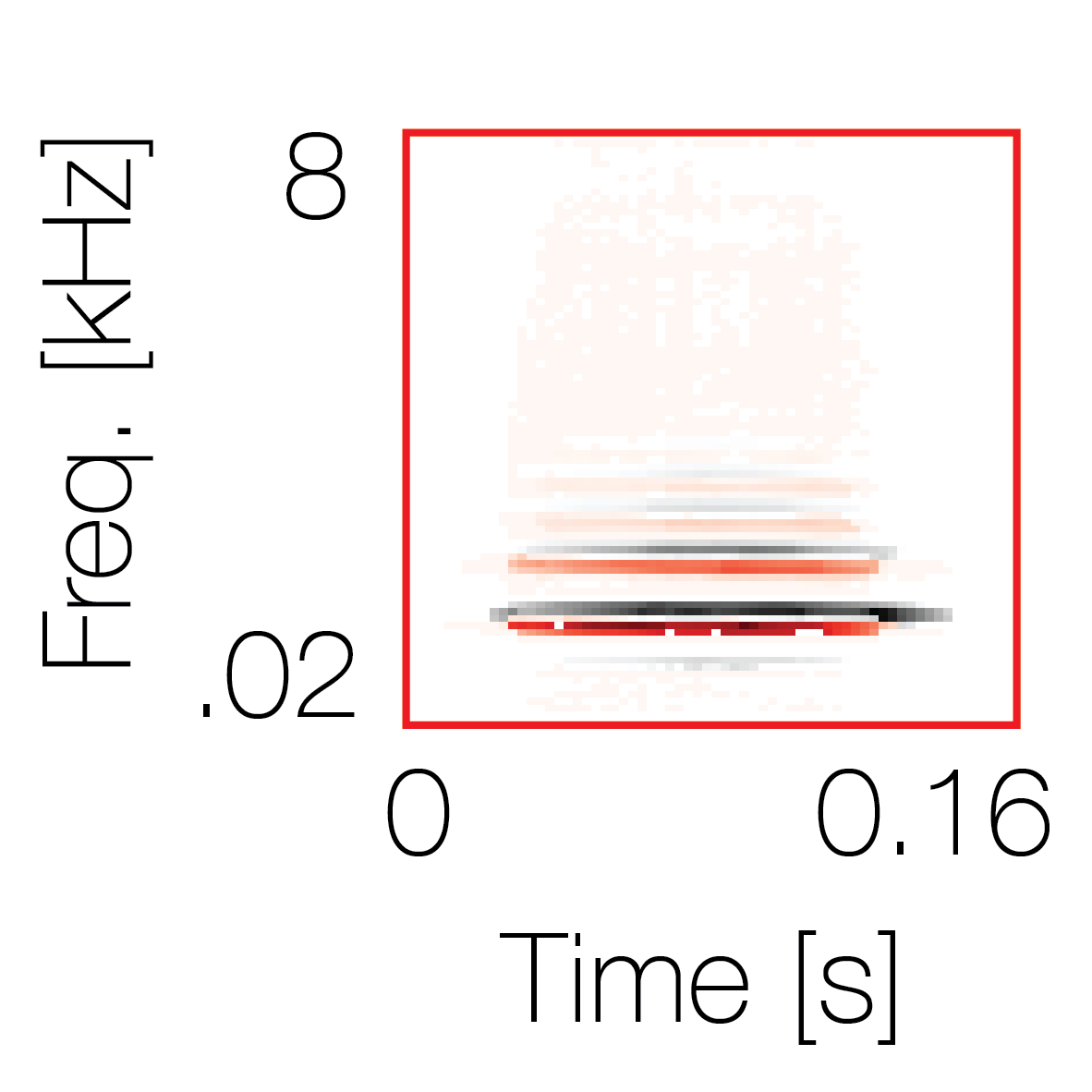
|
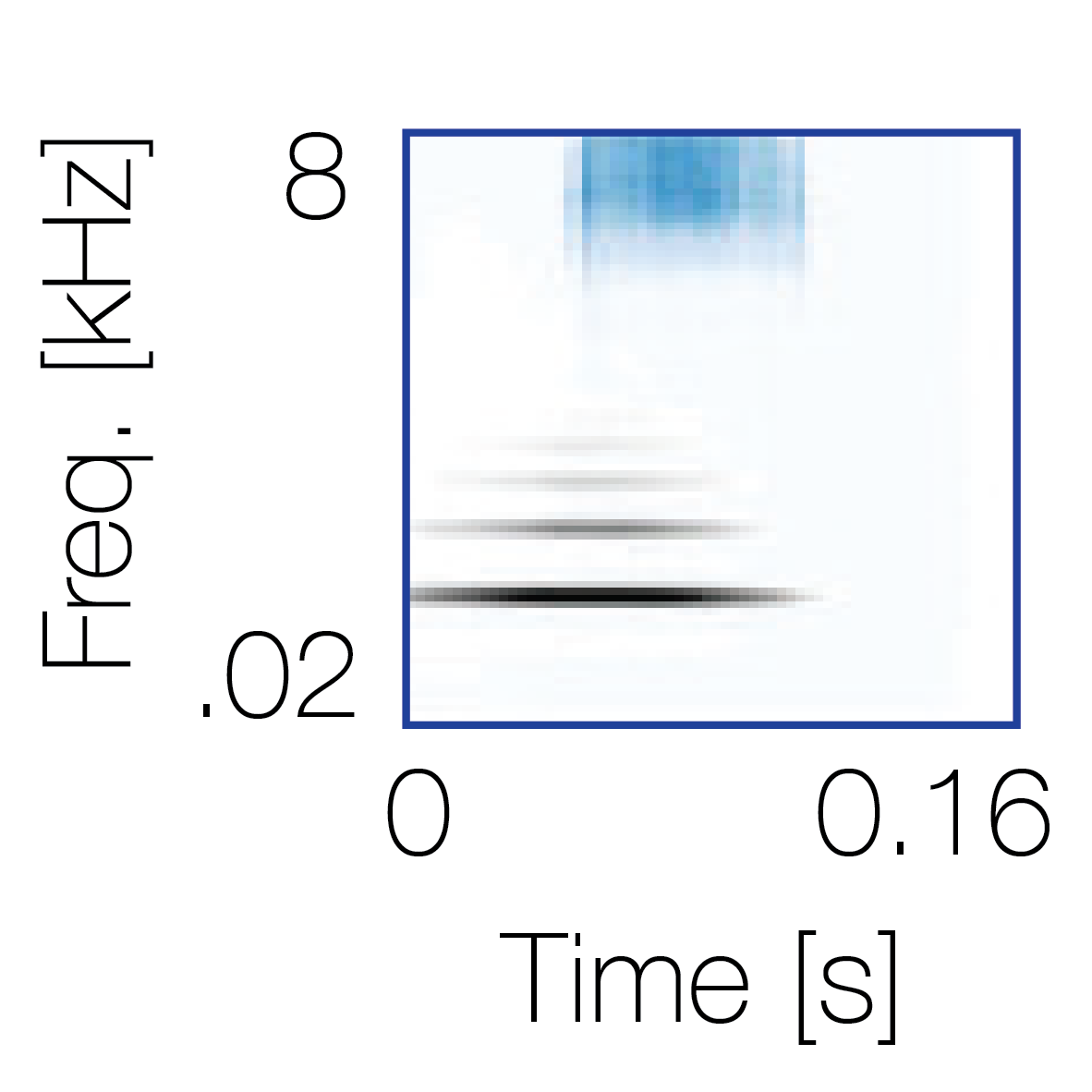
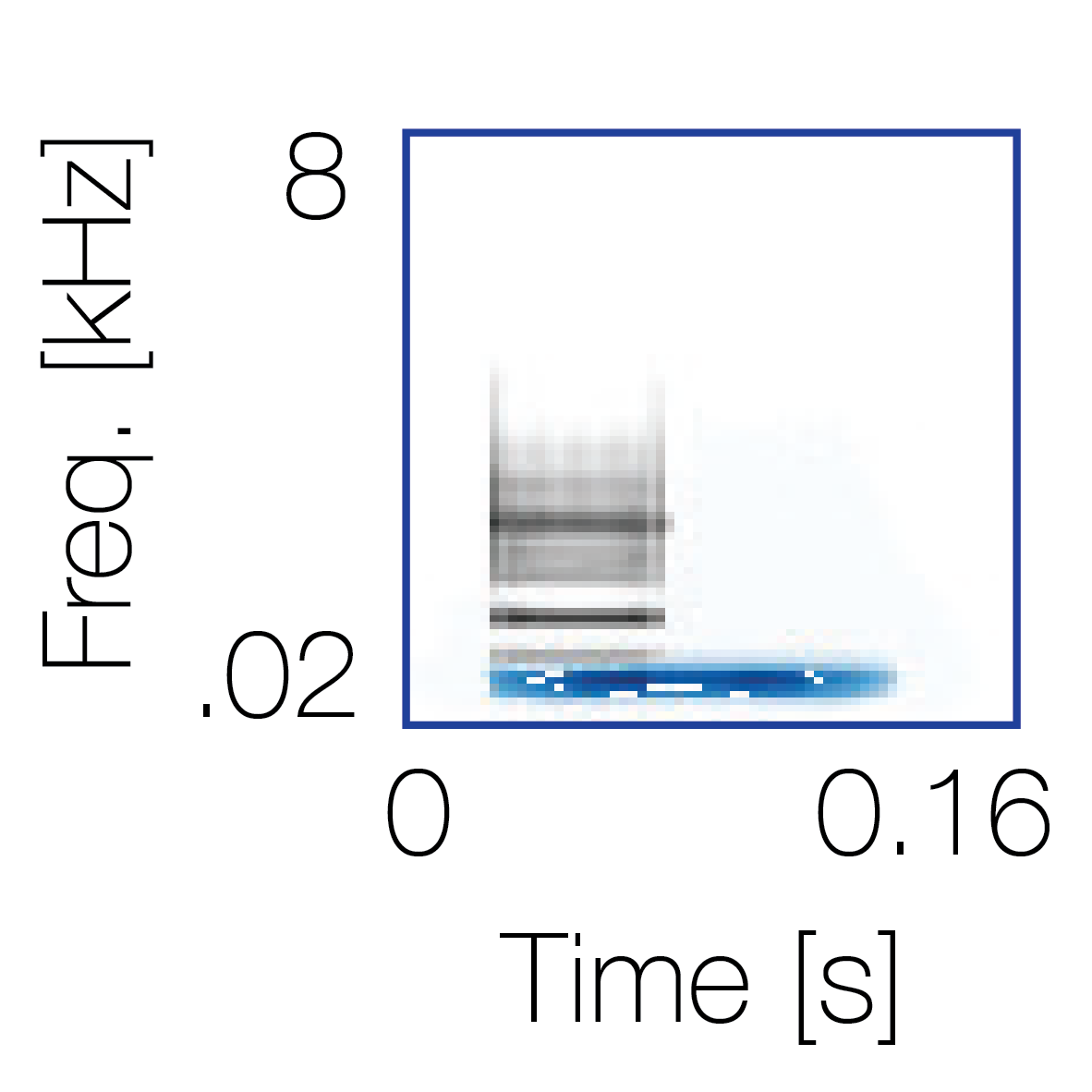
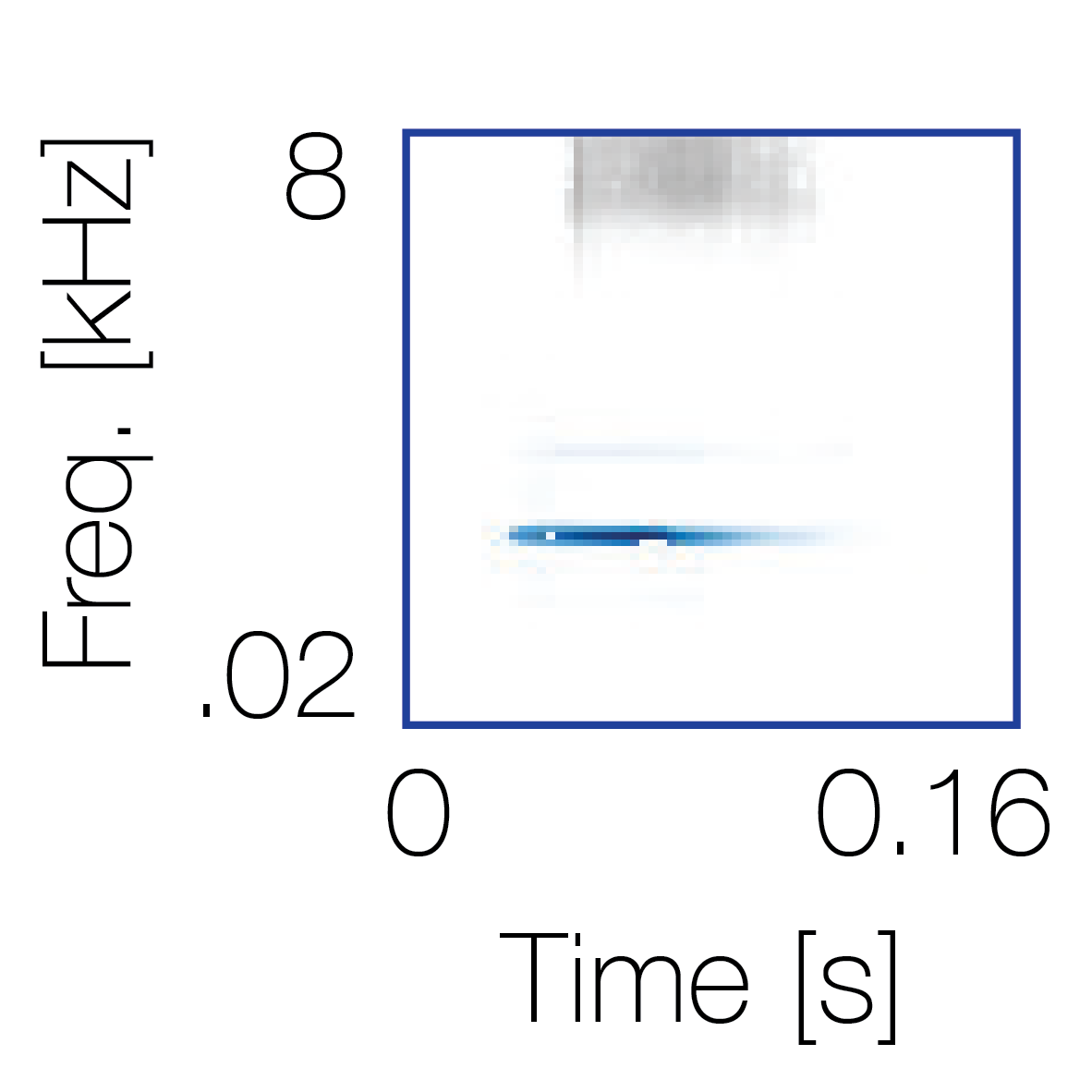
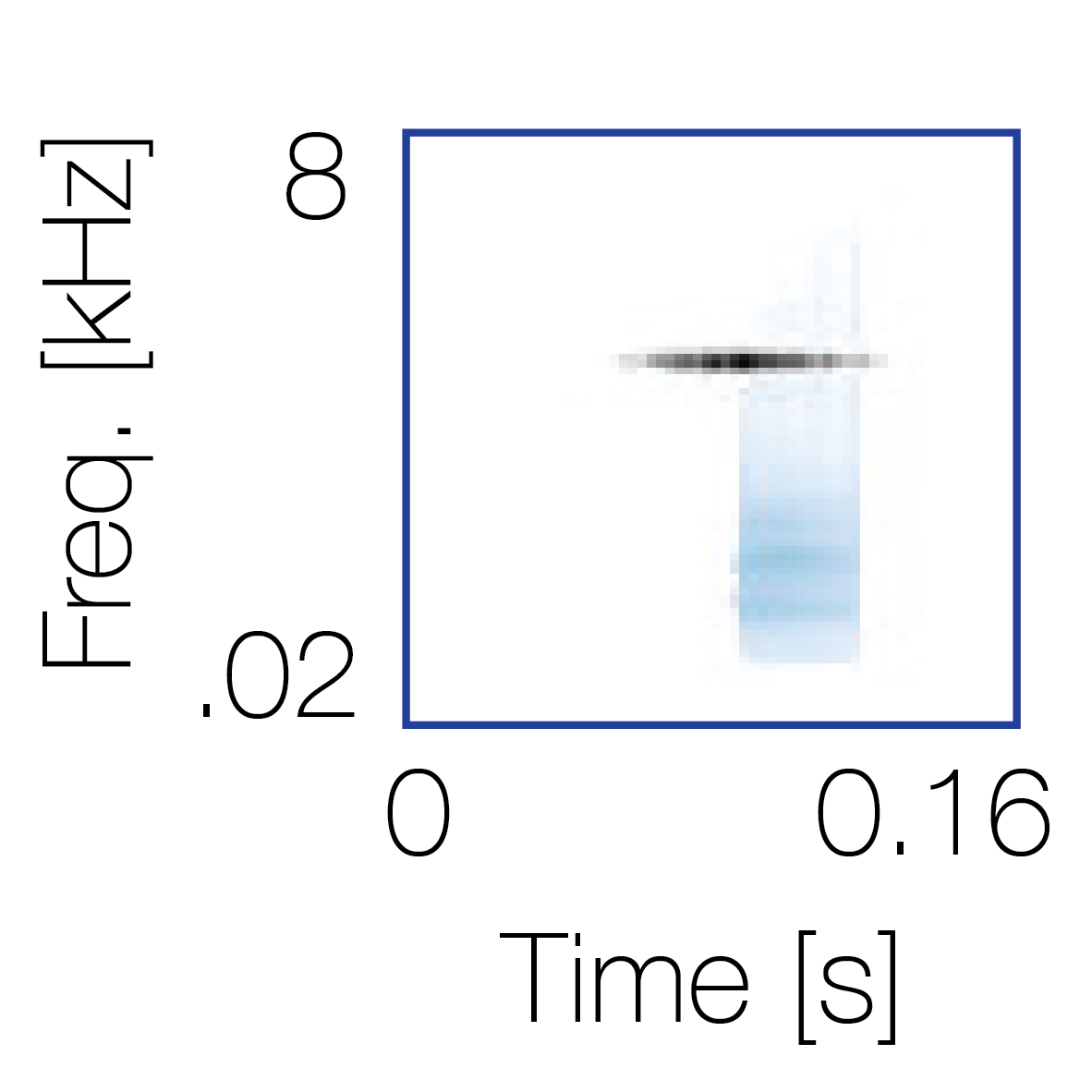
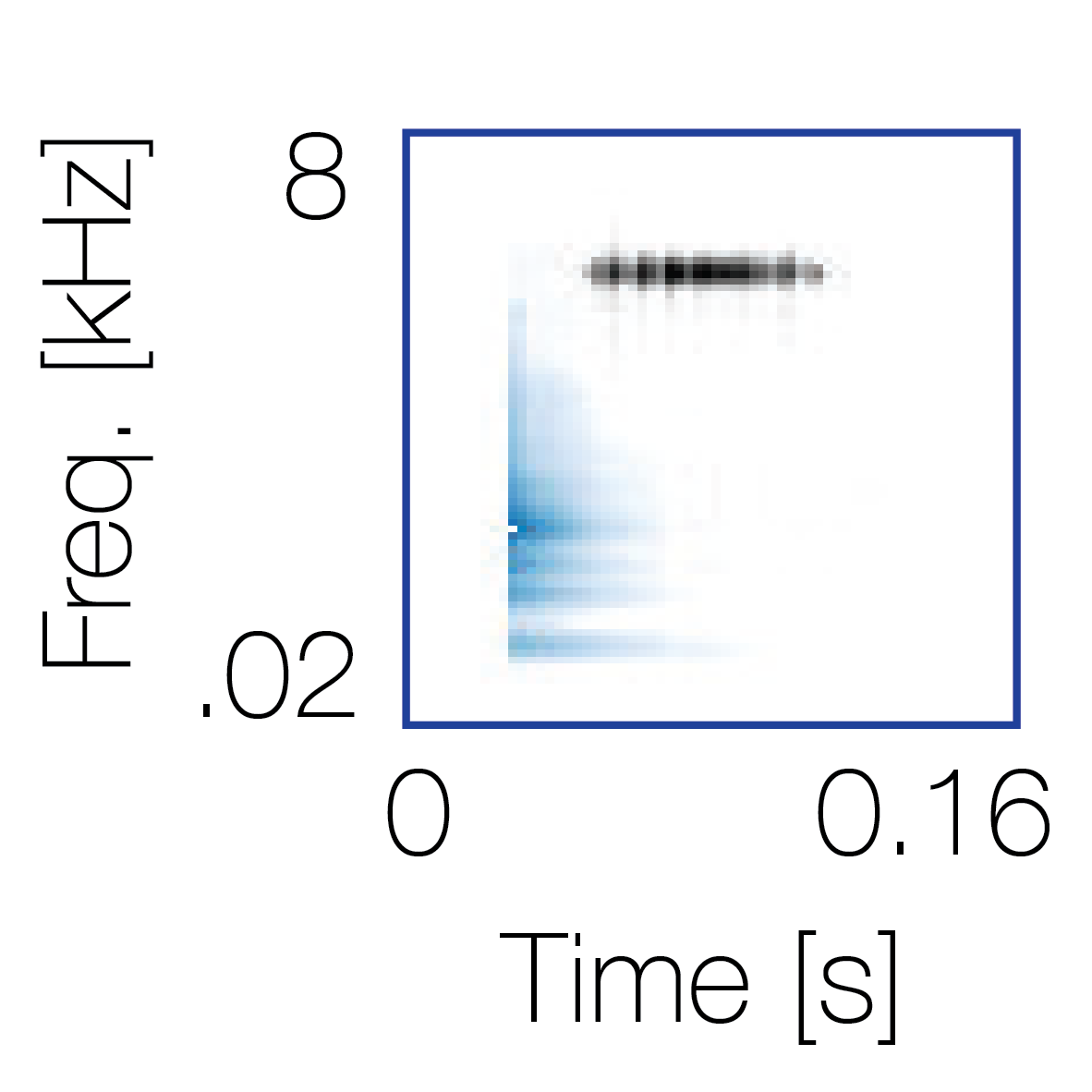
|
Sound pairs classified as a single source |
Sound pairs classified as different sources |
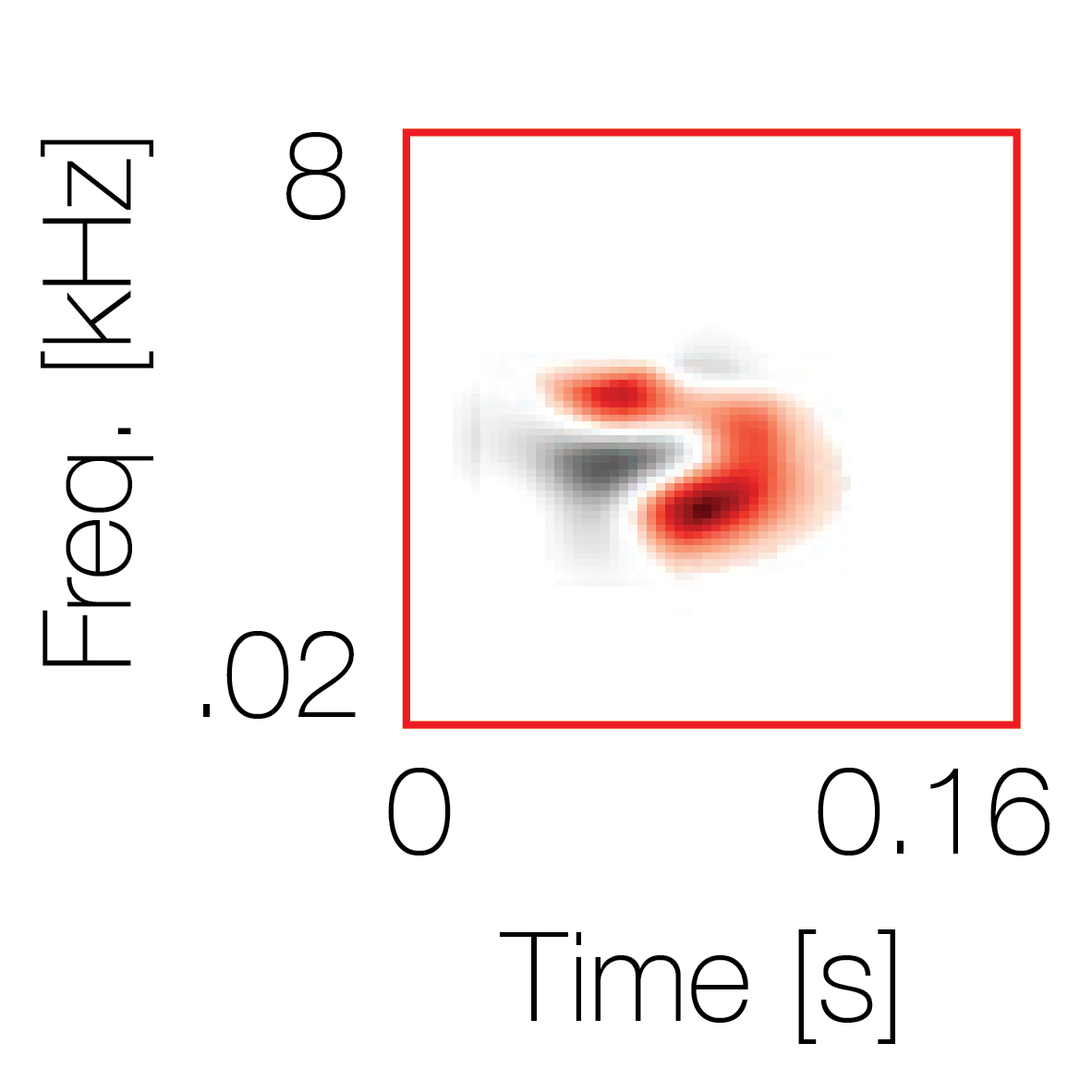
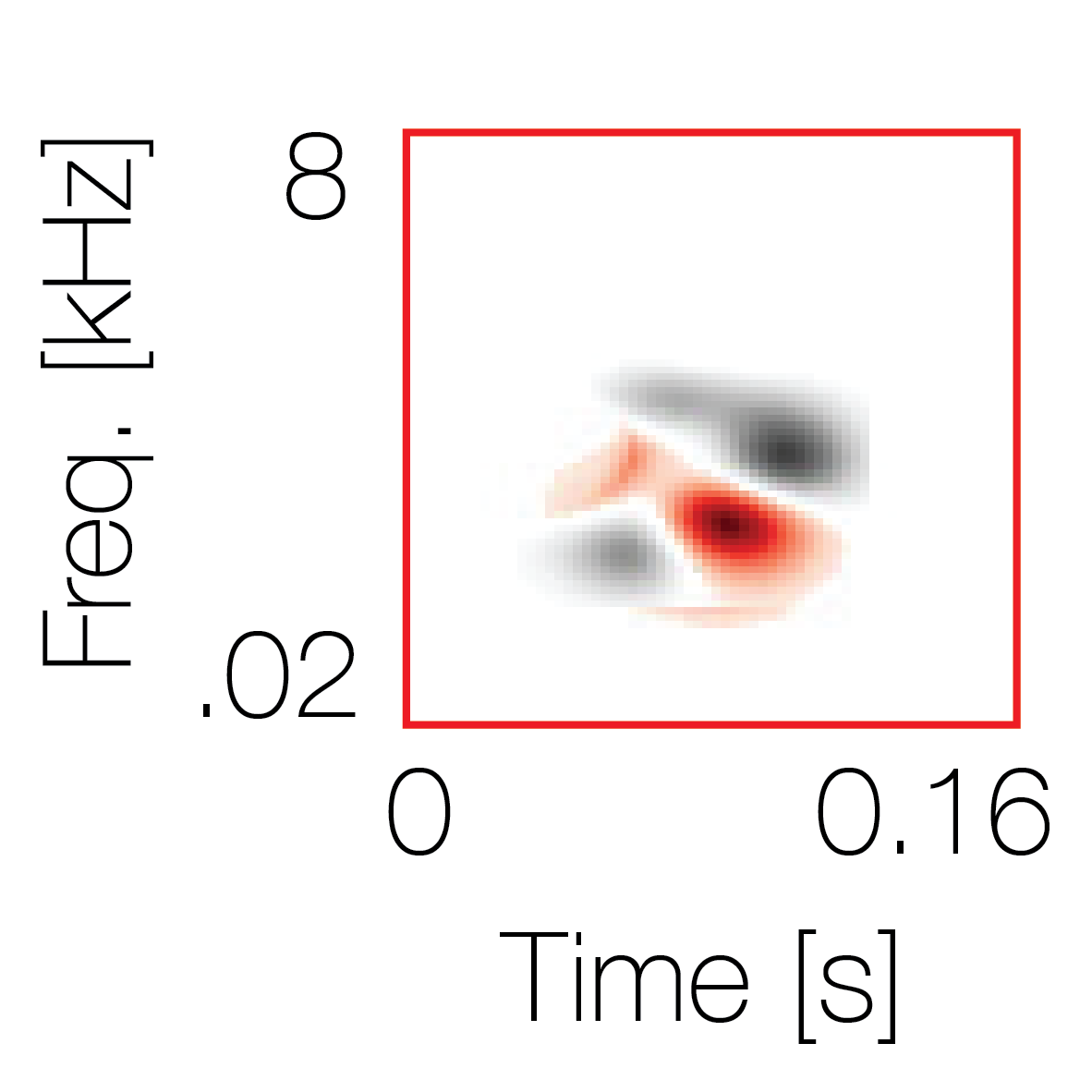
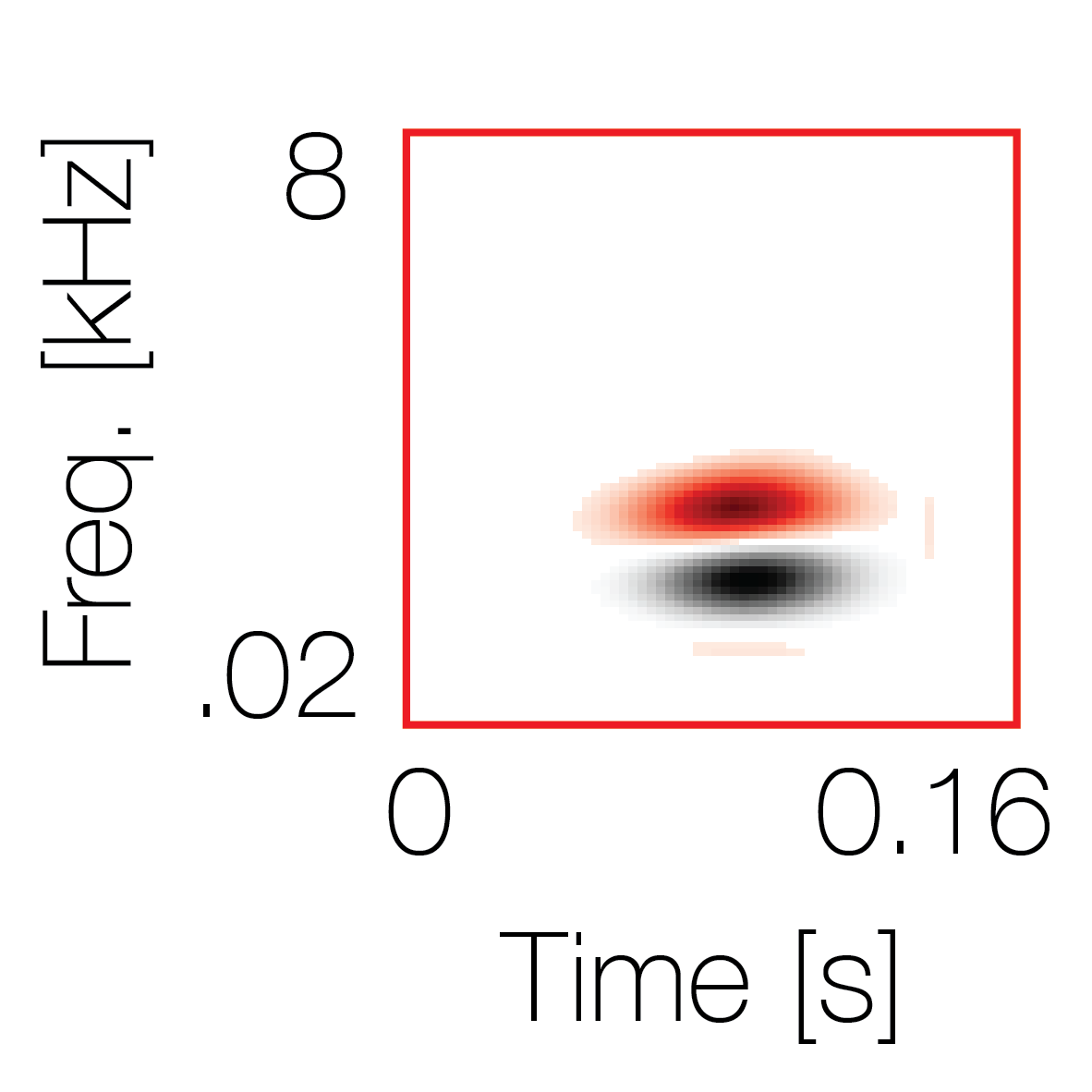
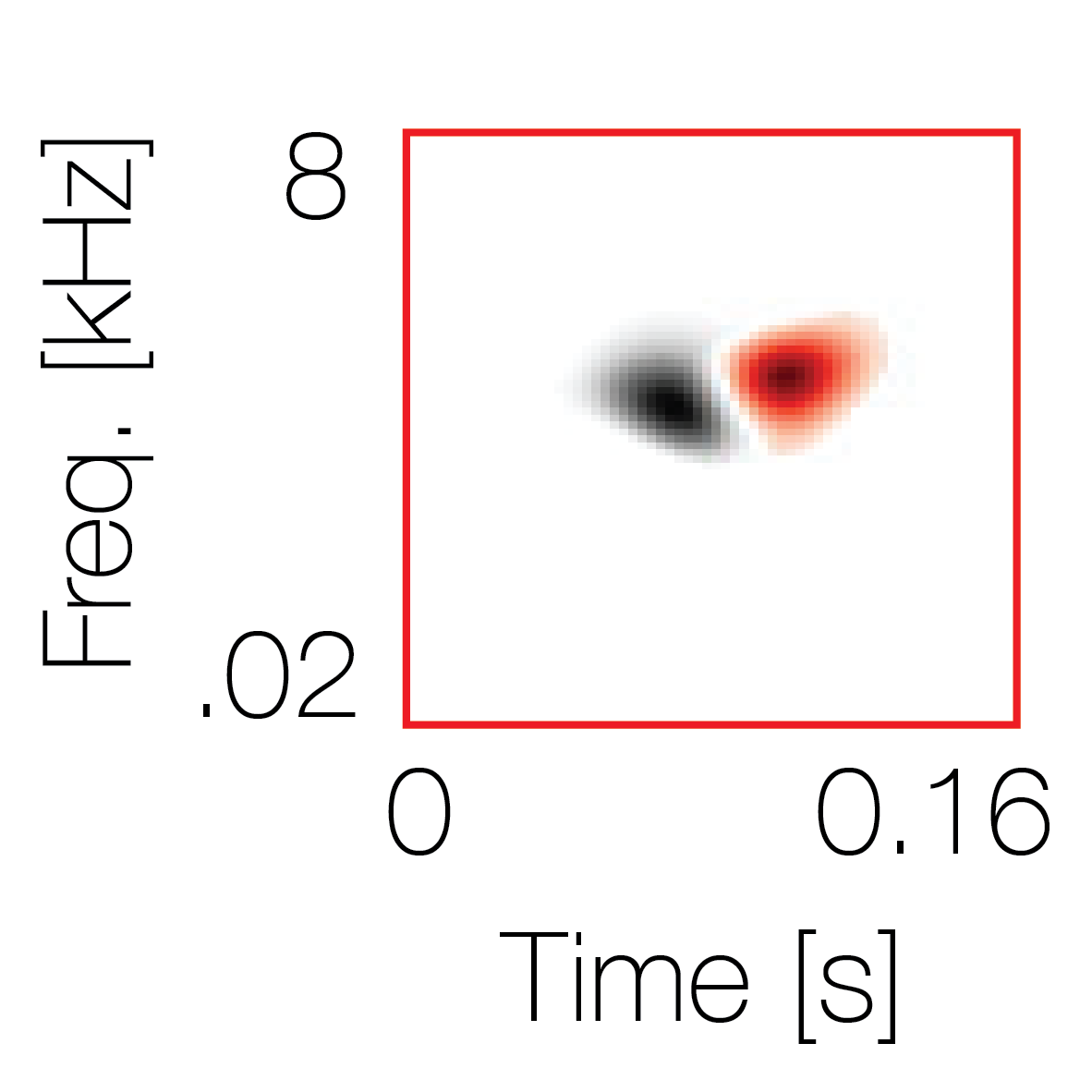
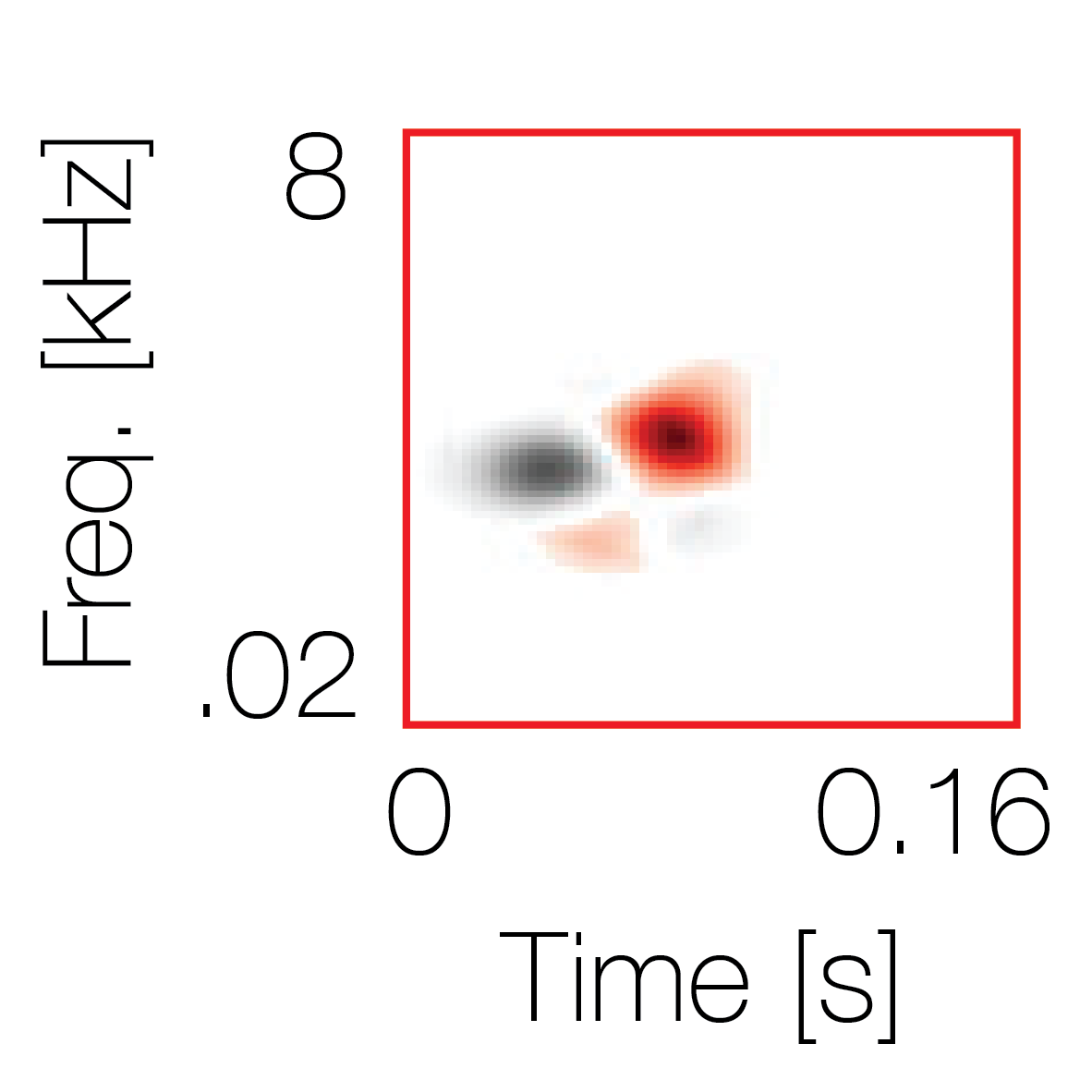
|
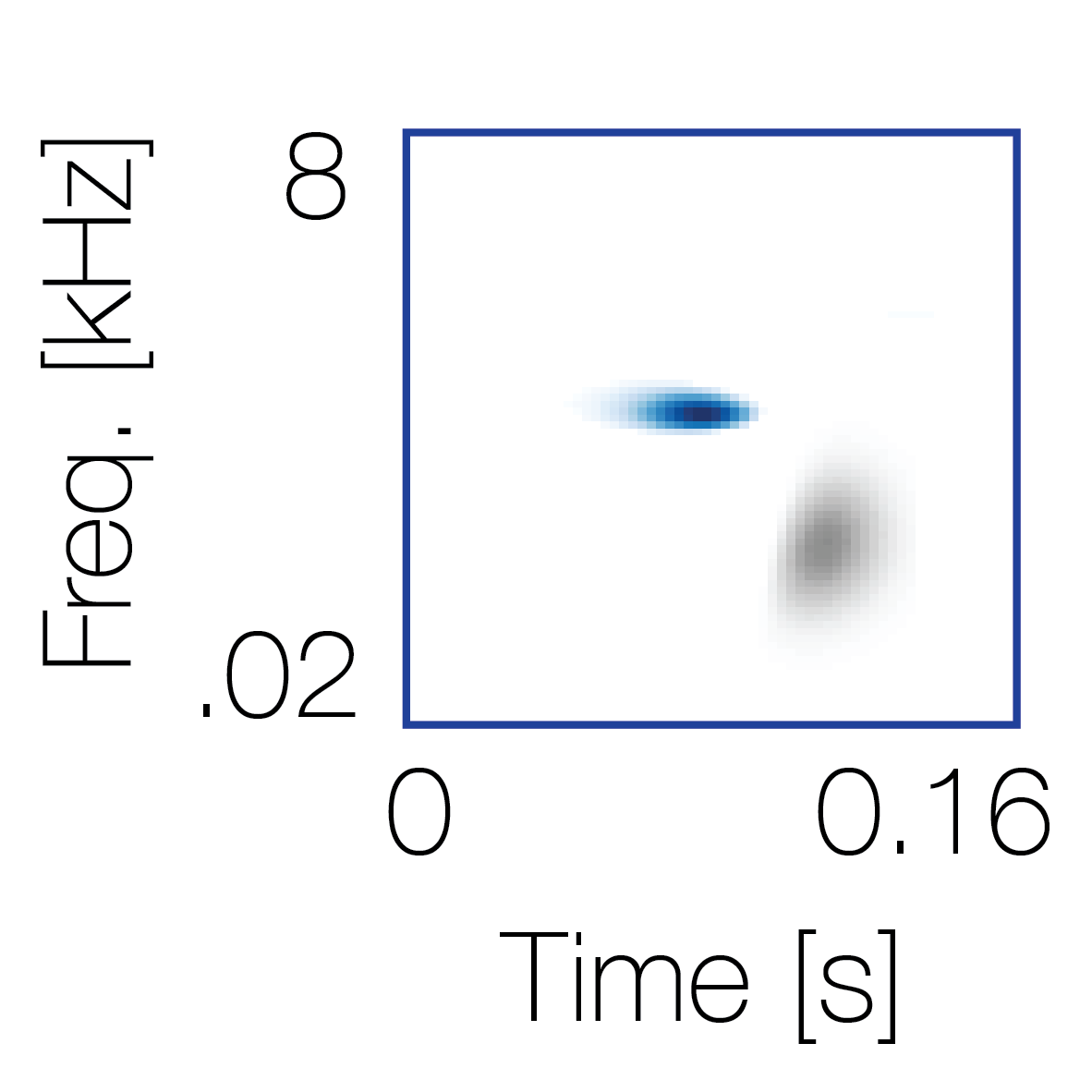
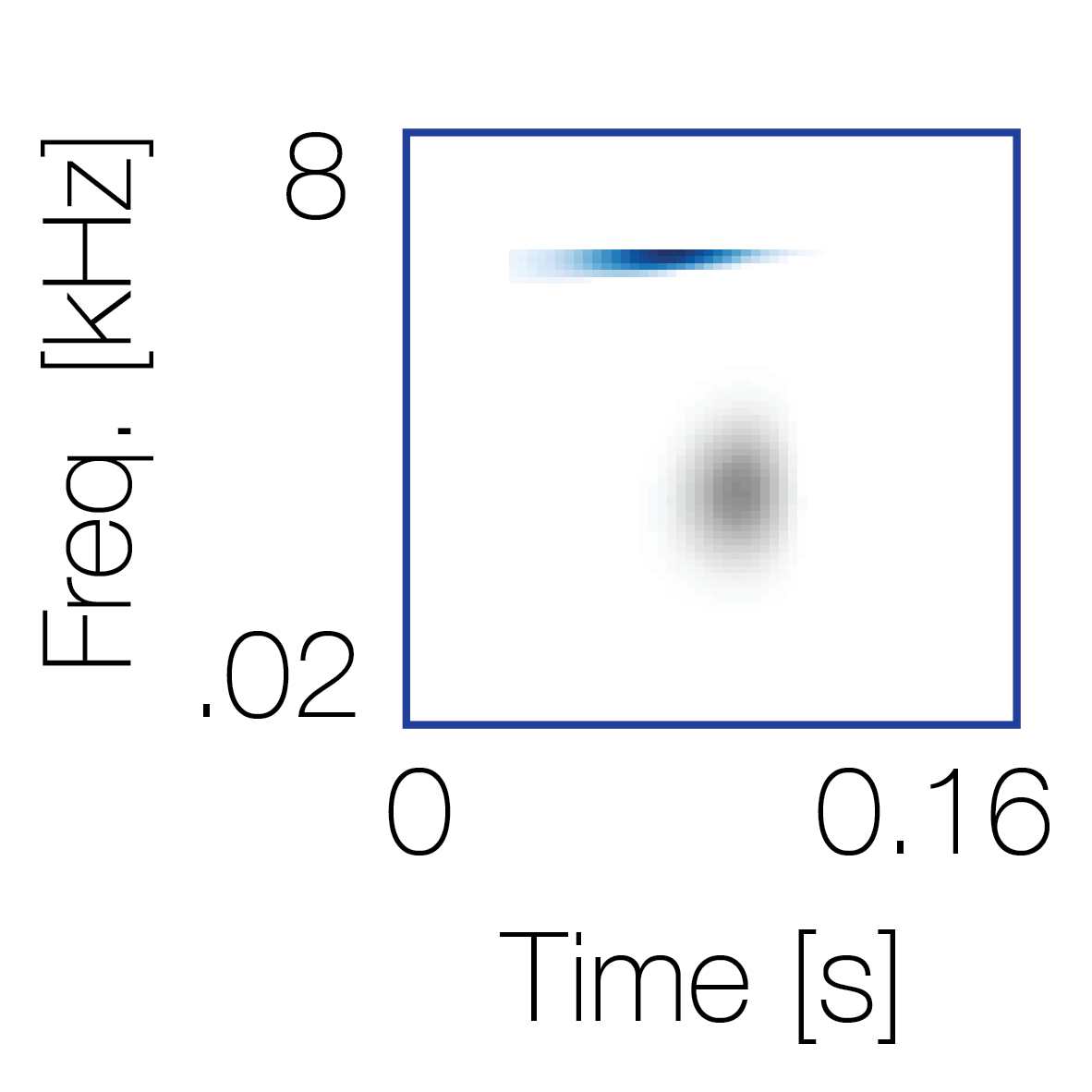
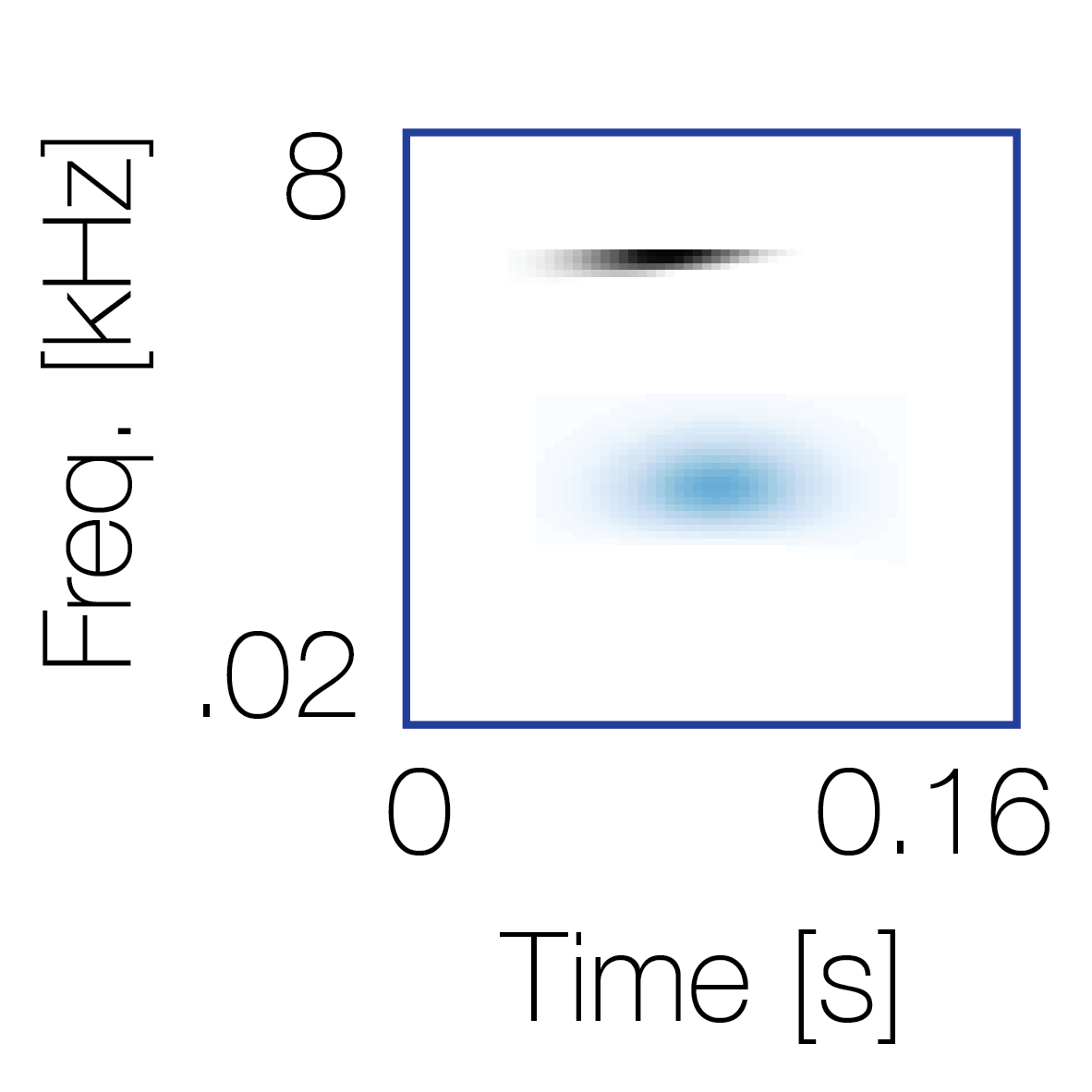
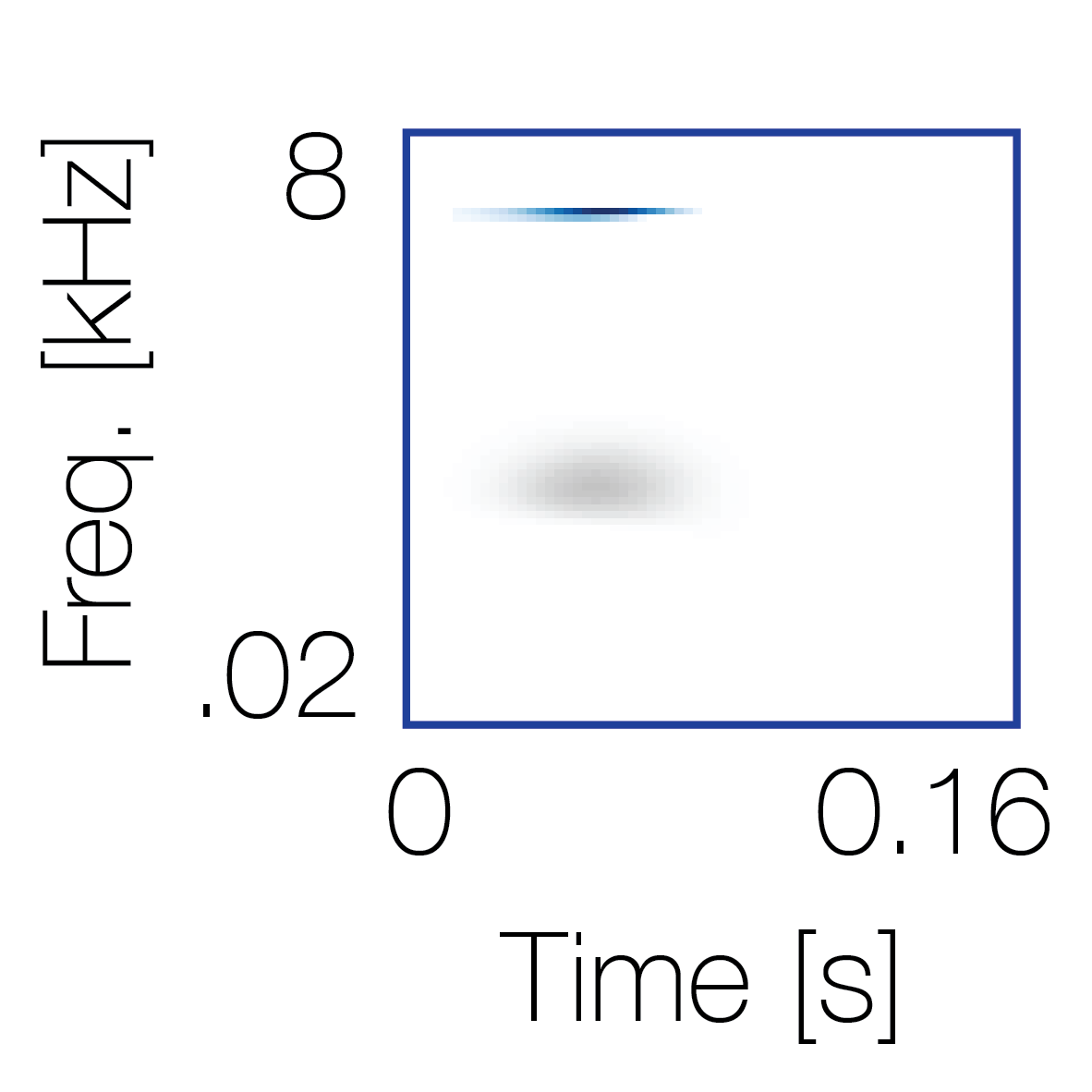
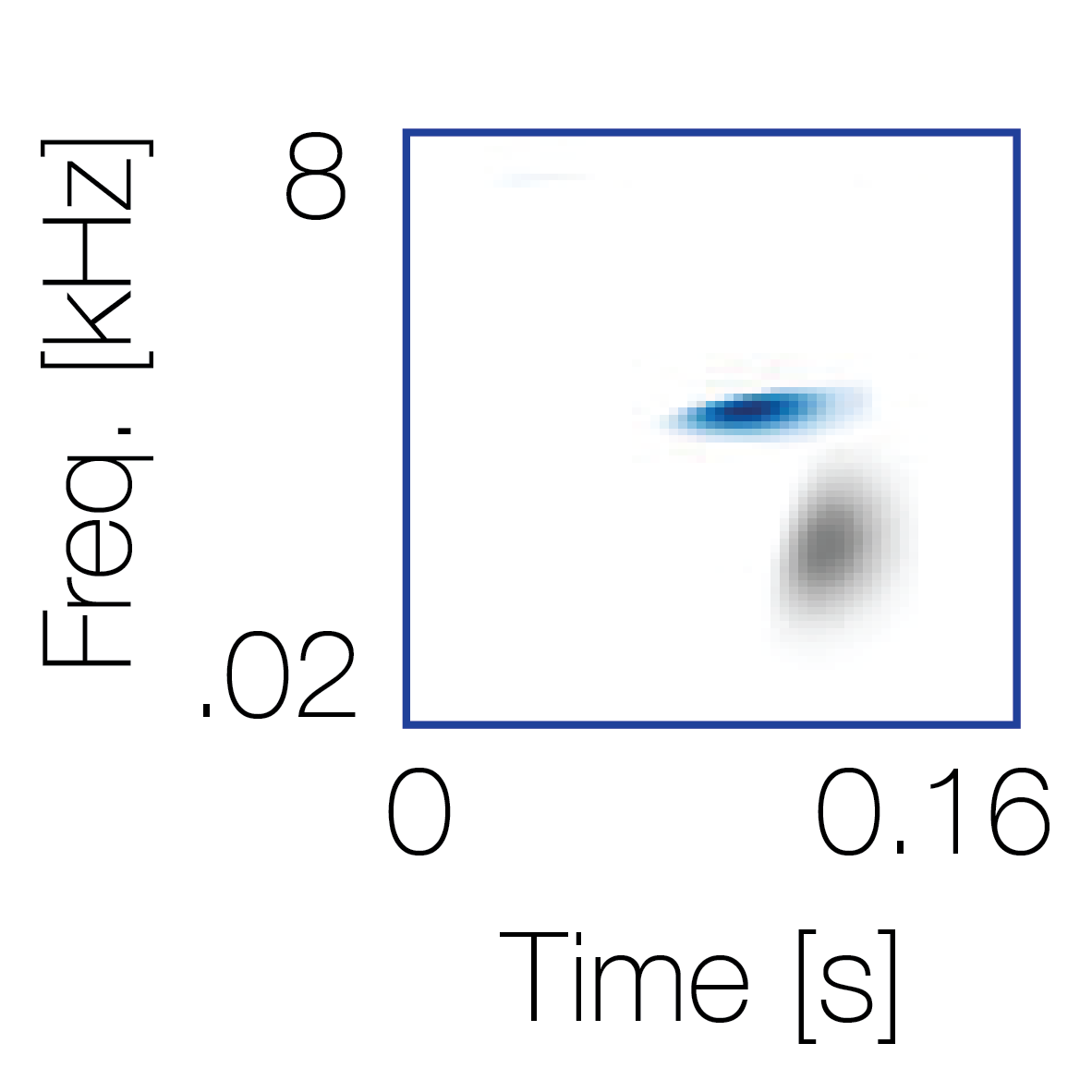
|
Sound pairs classified as a single source |
Sound pairs classified as different sources |
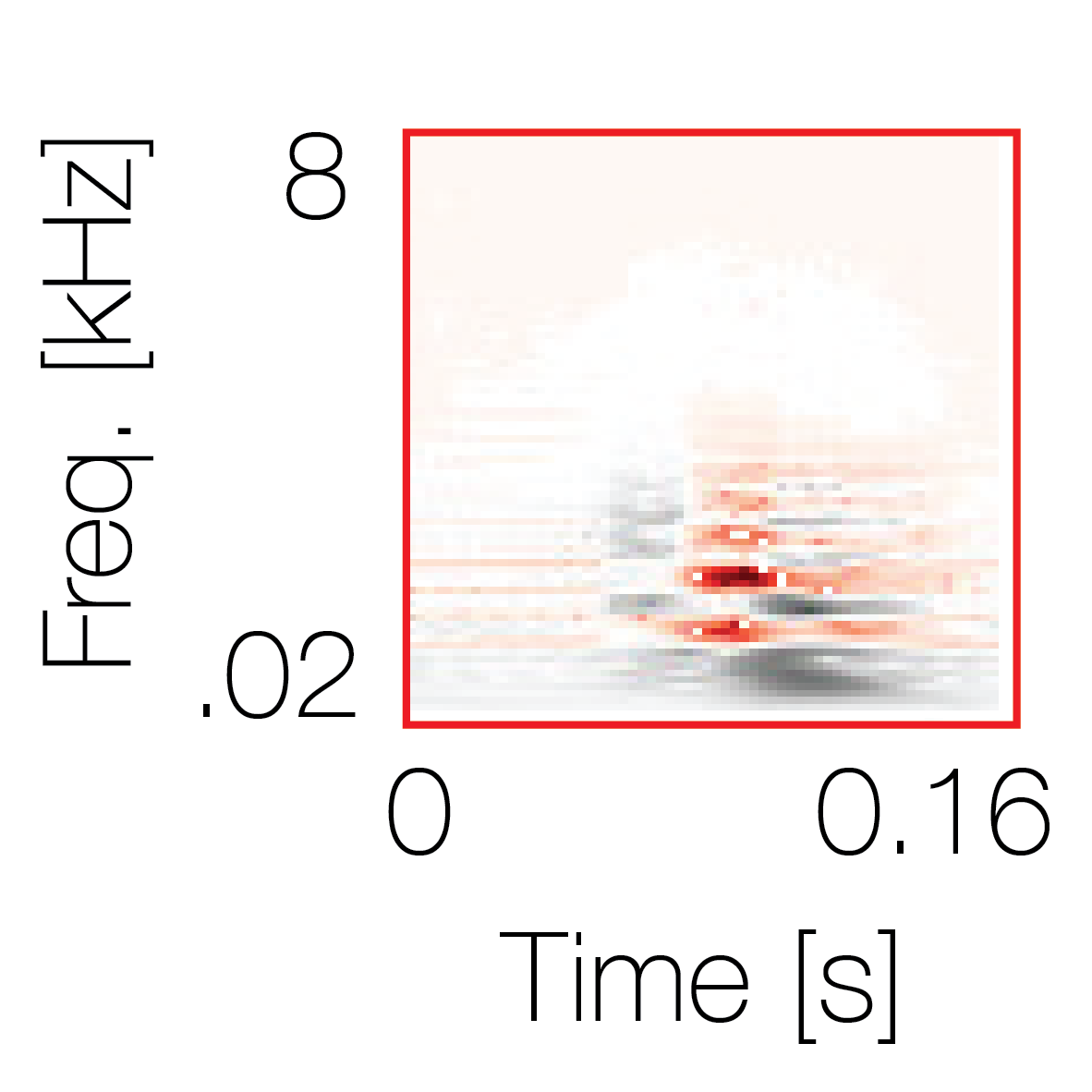
|
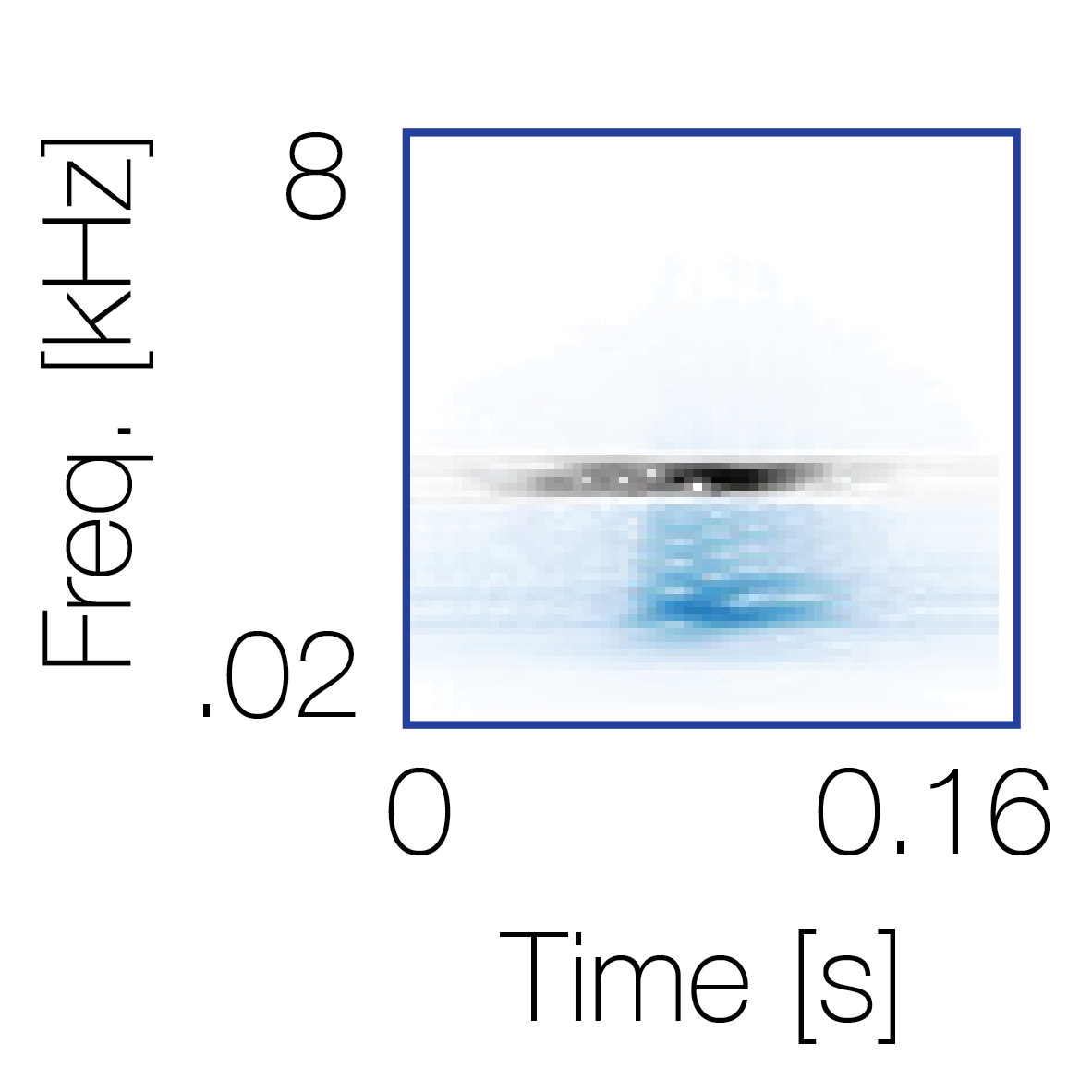
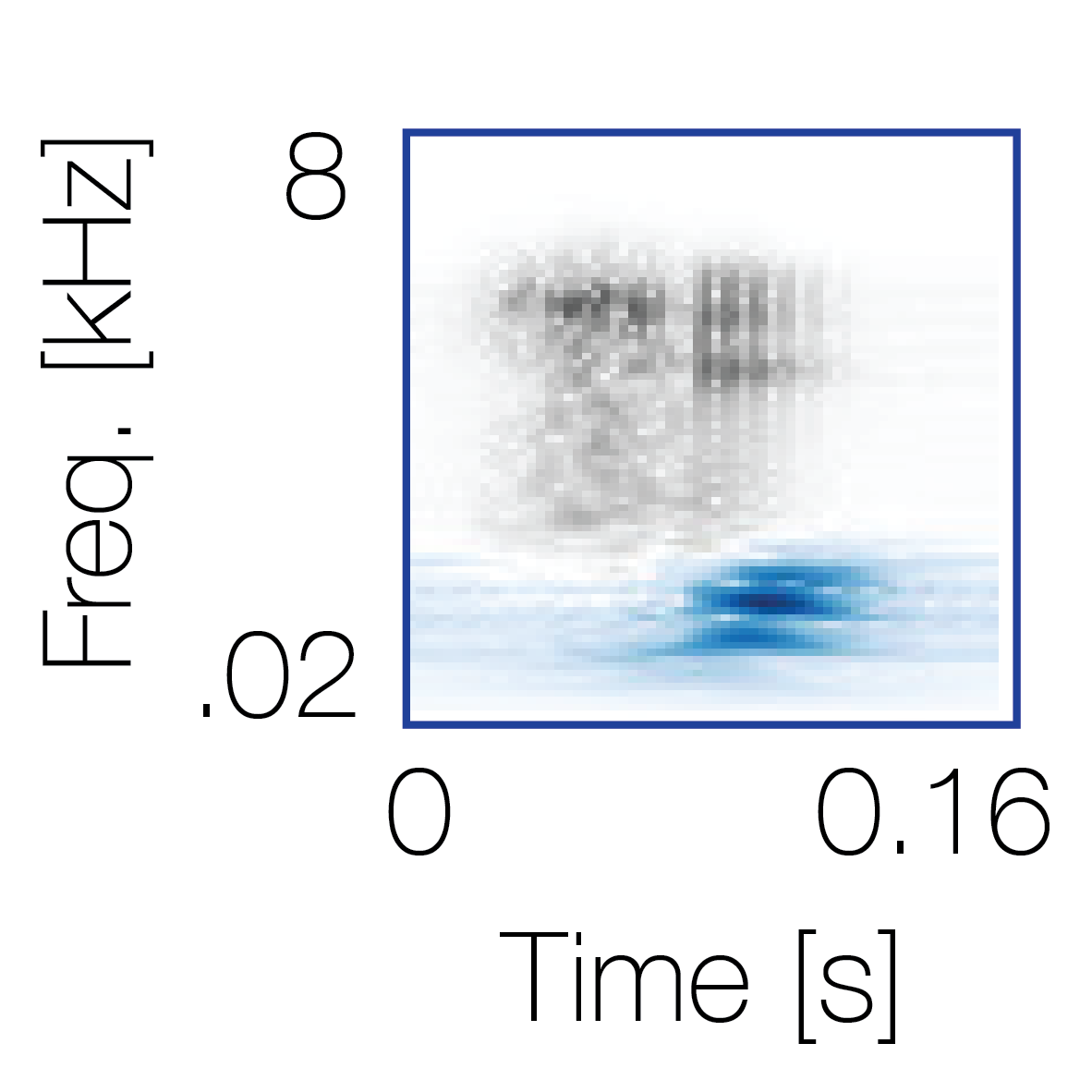
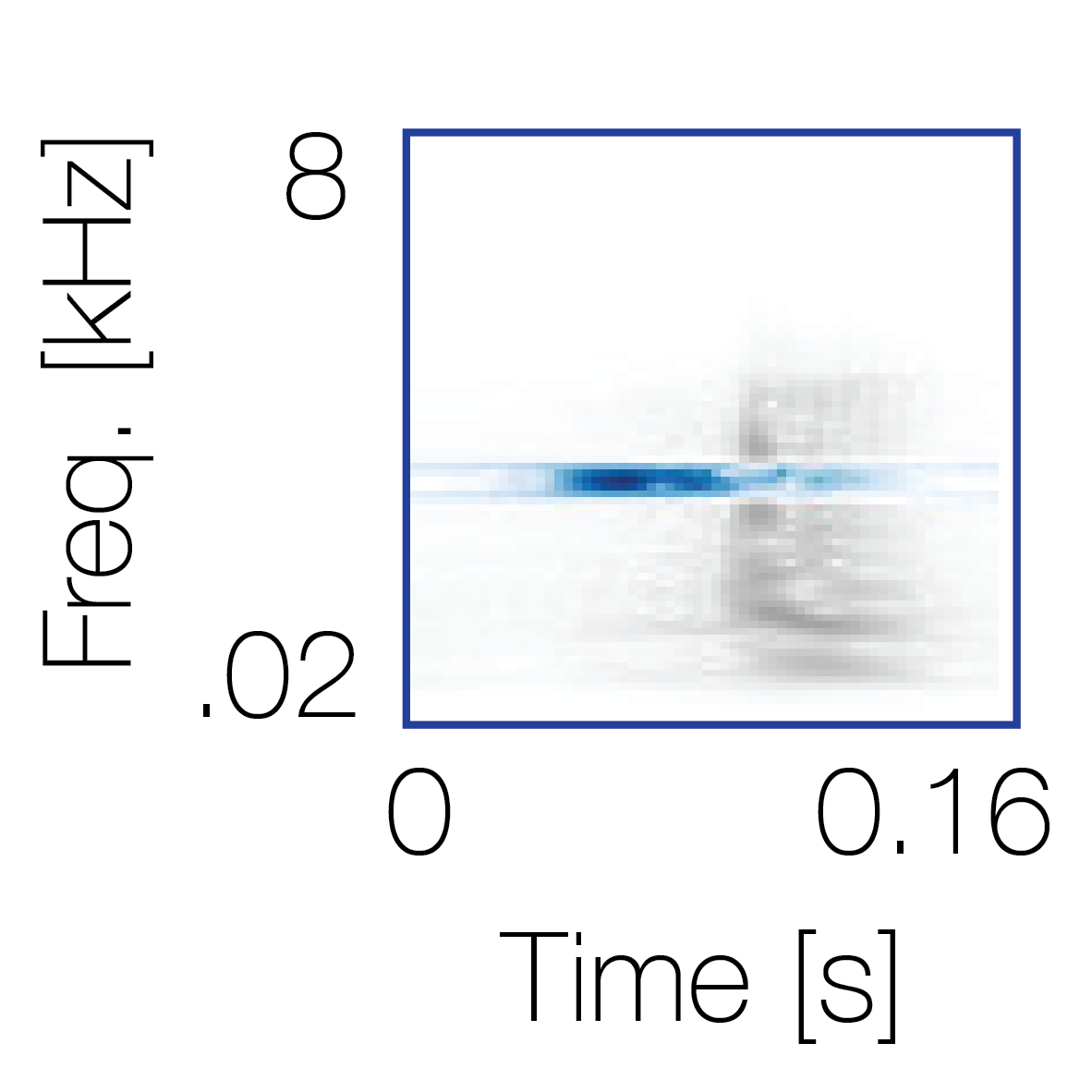
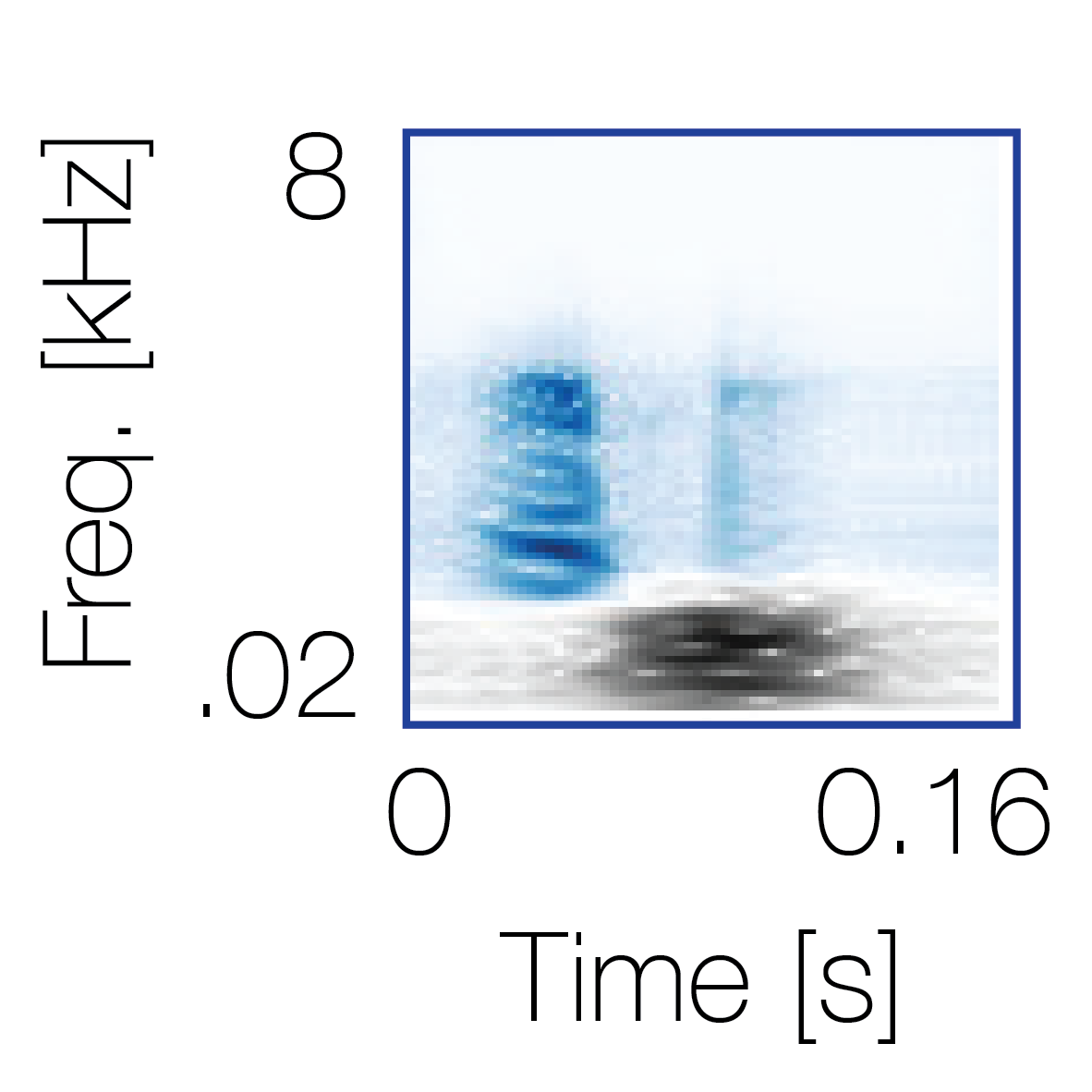
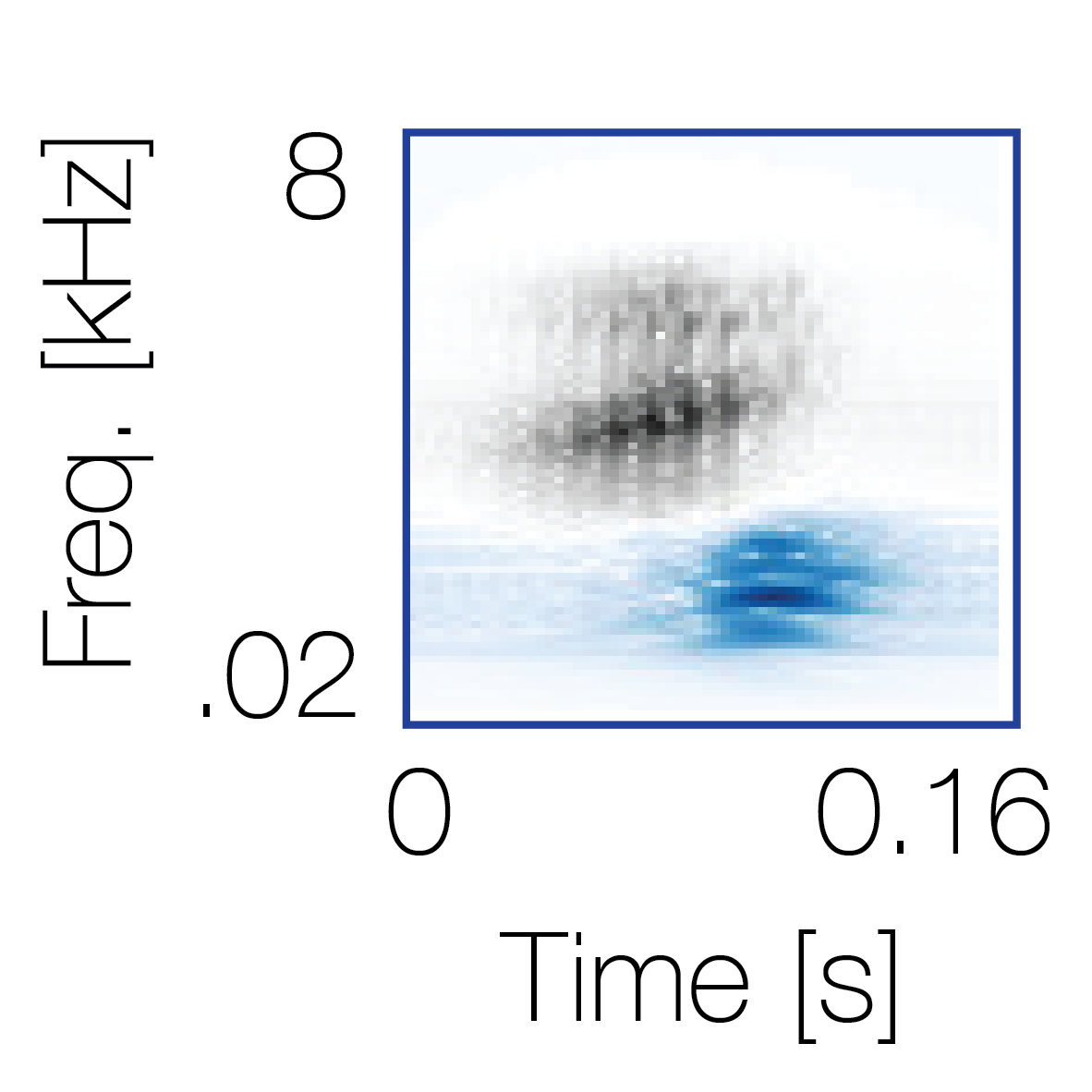
|
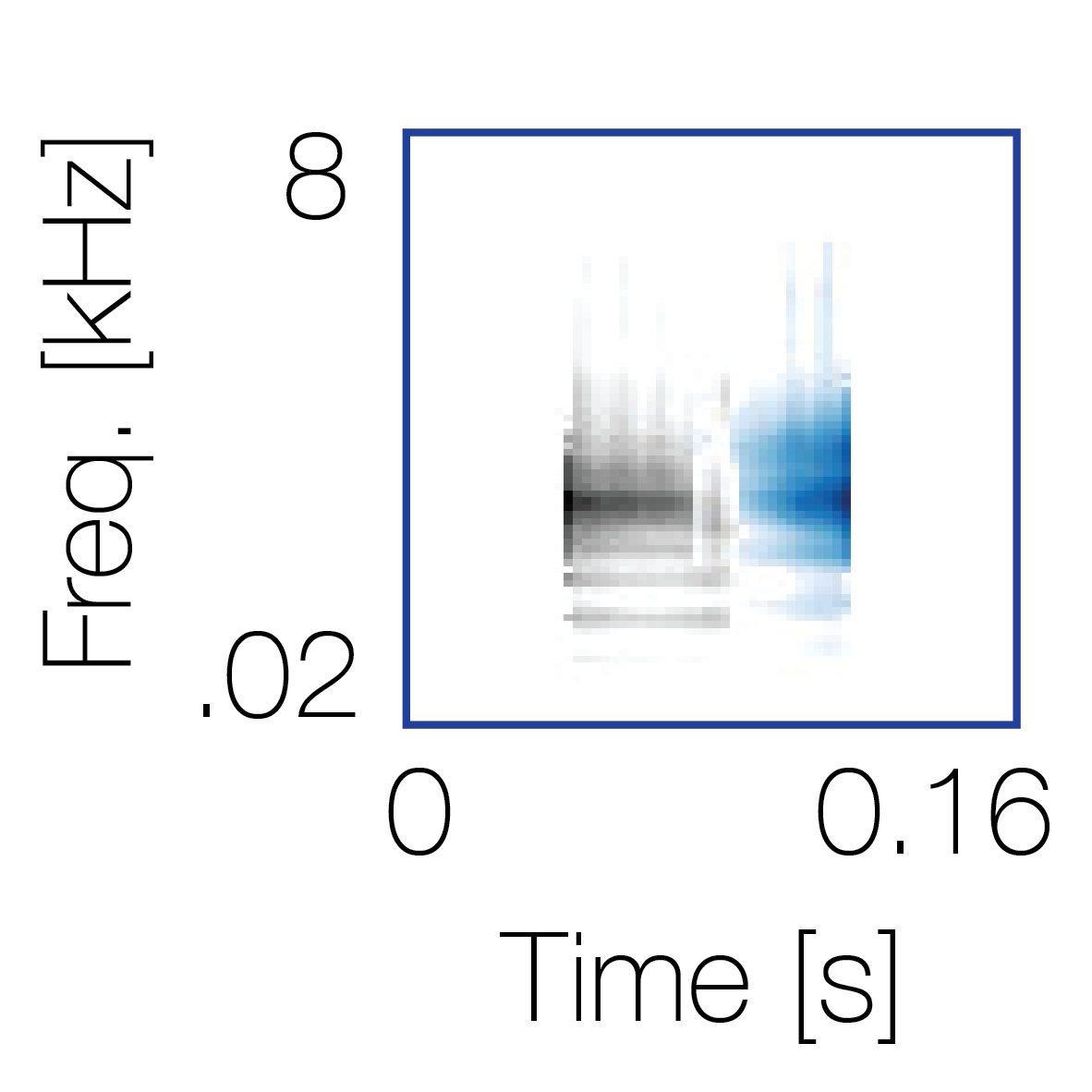
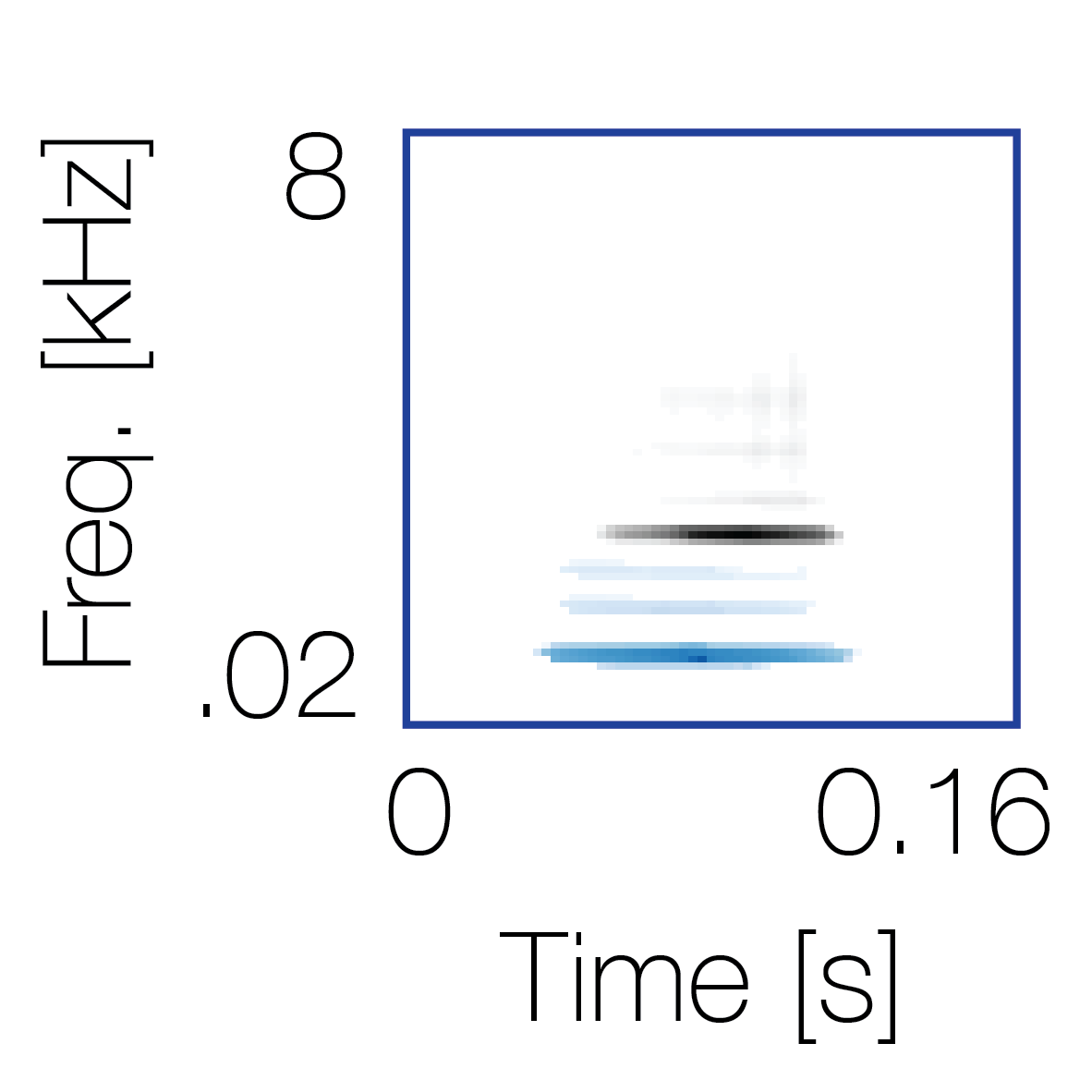
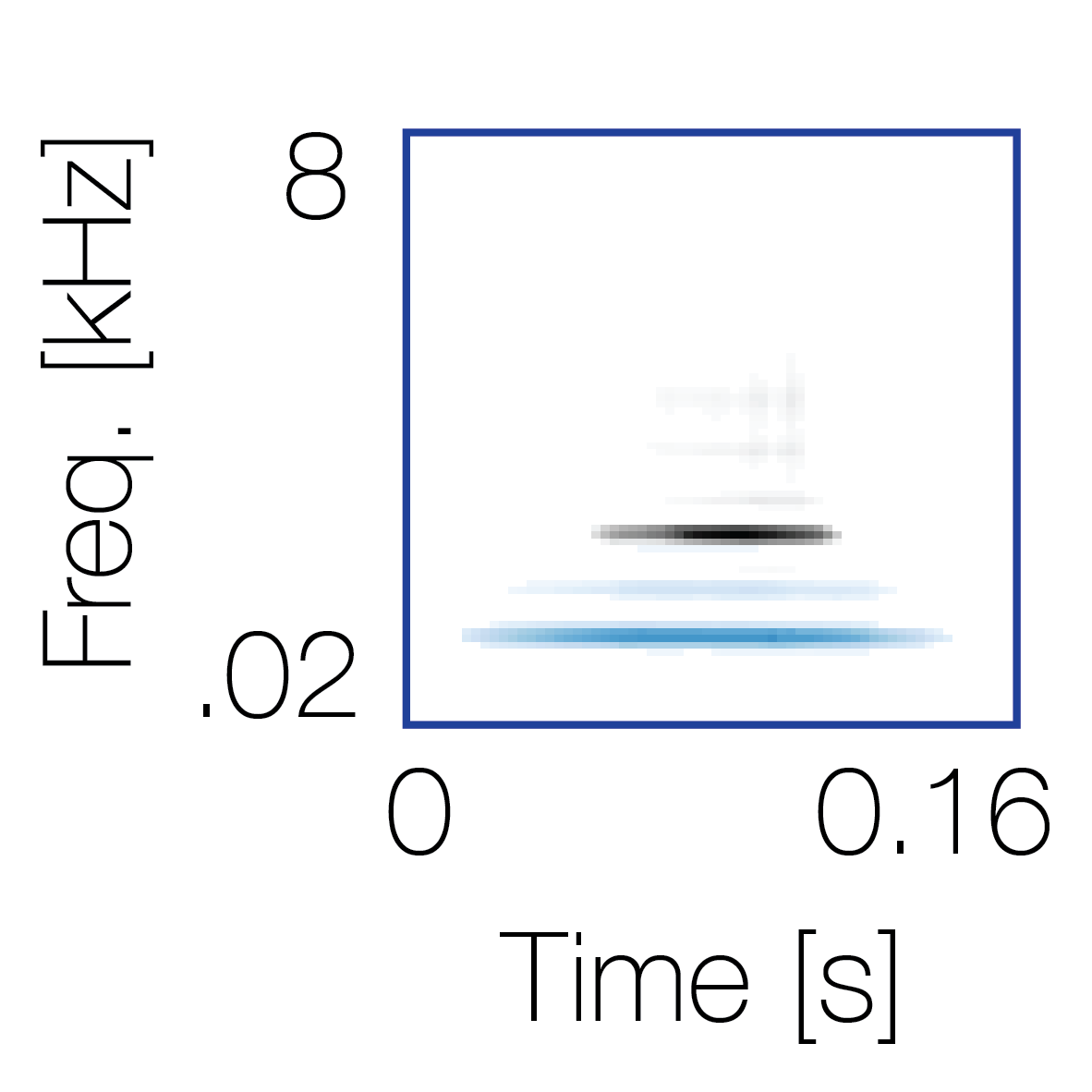
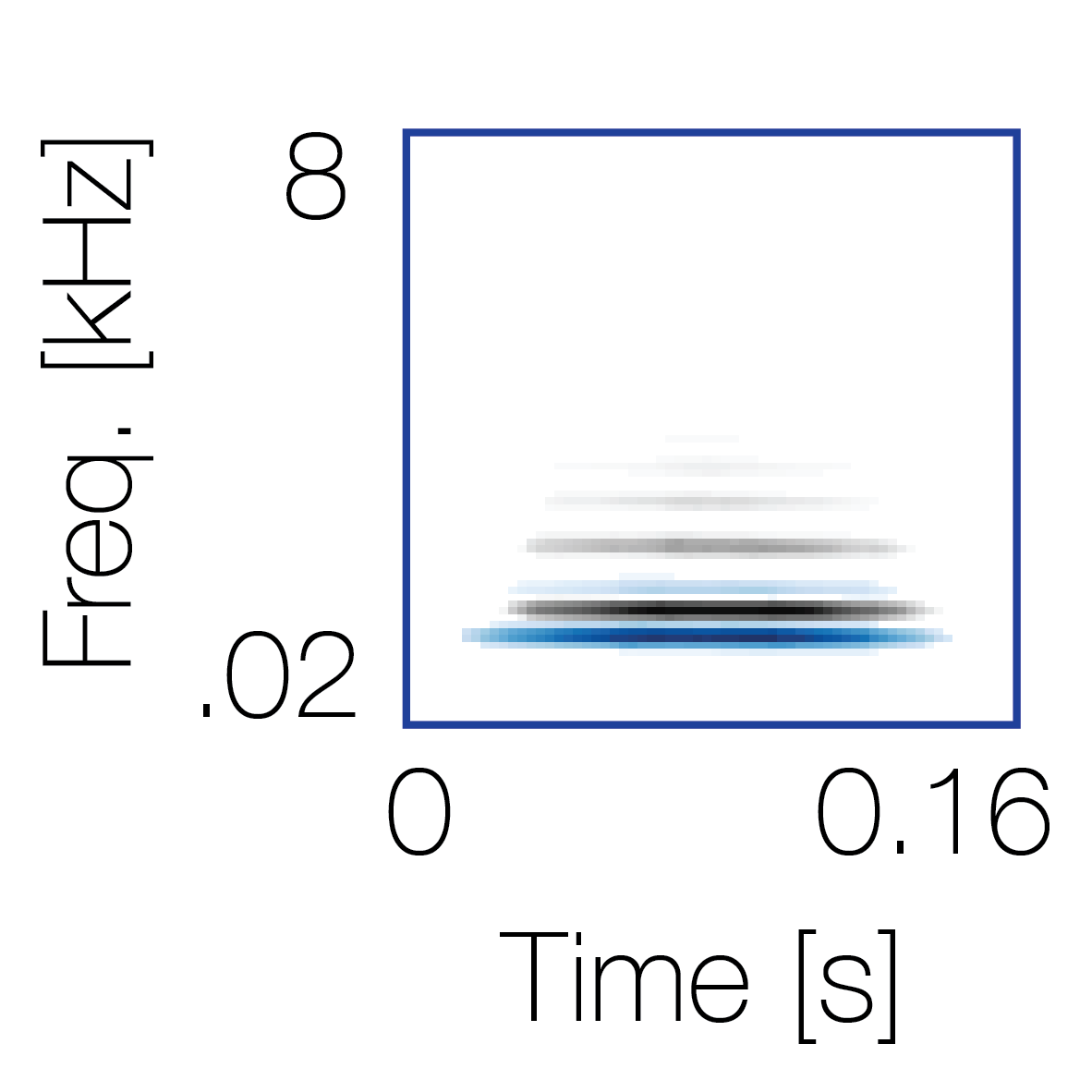
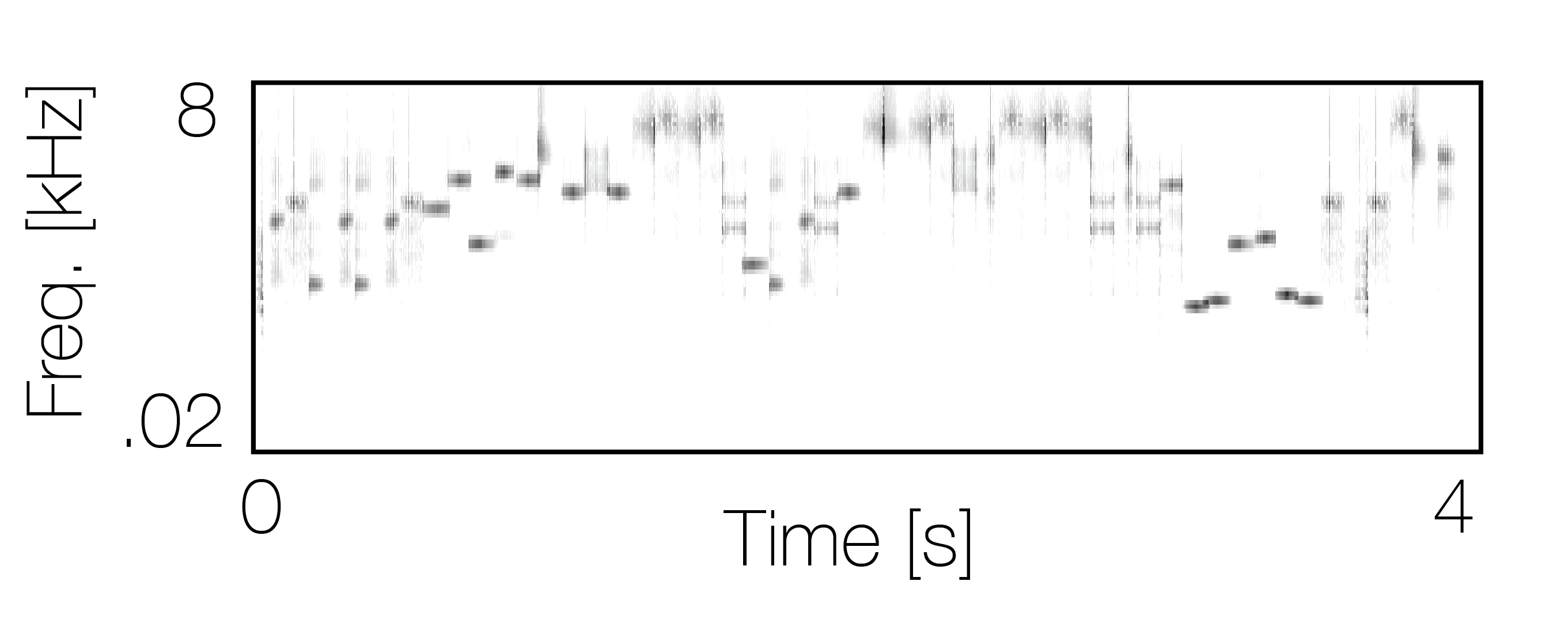
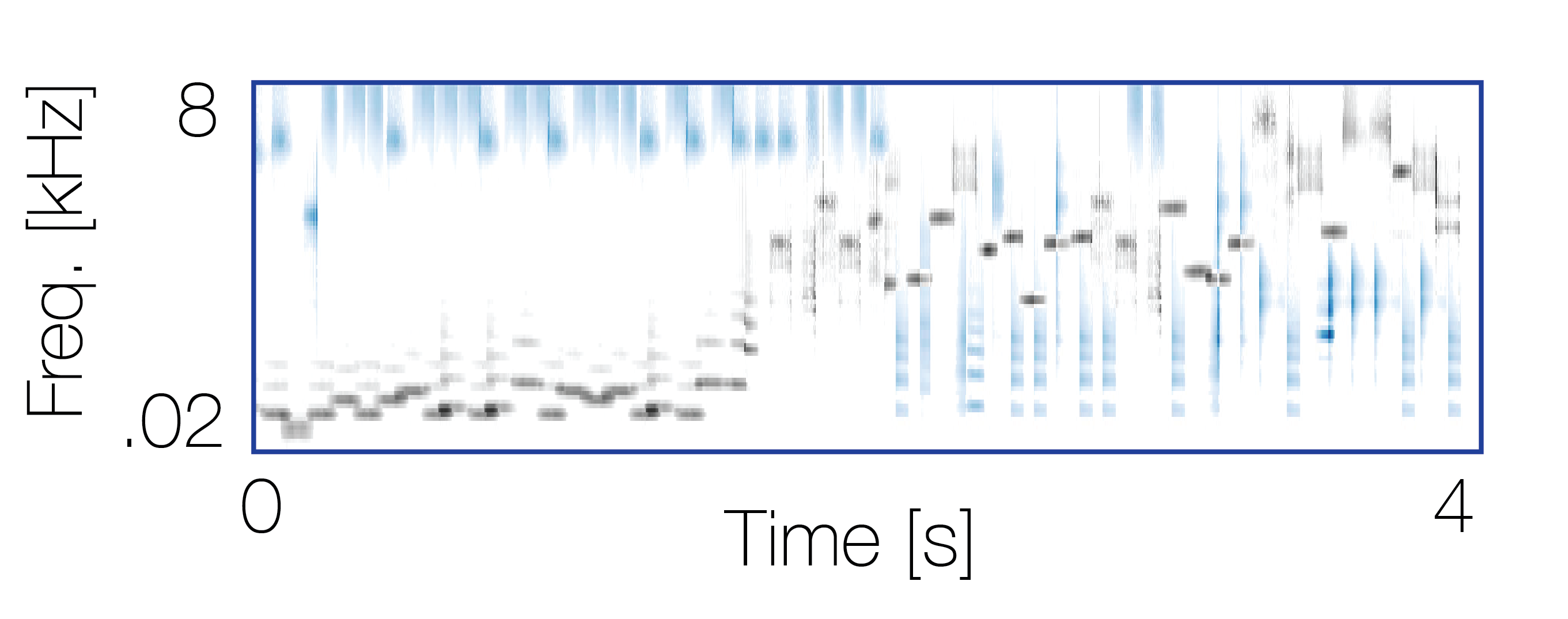
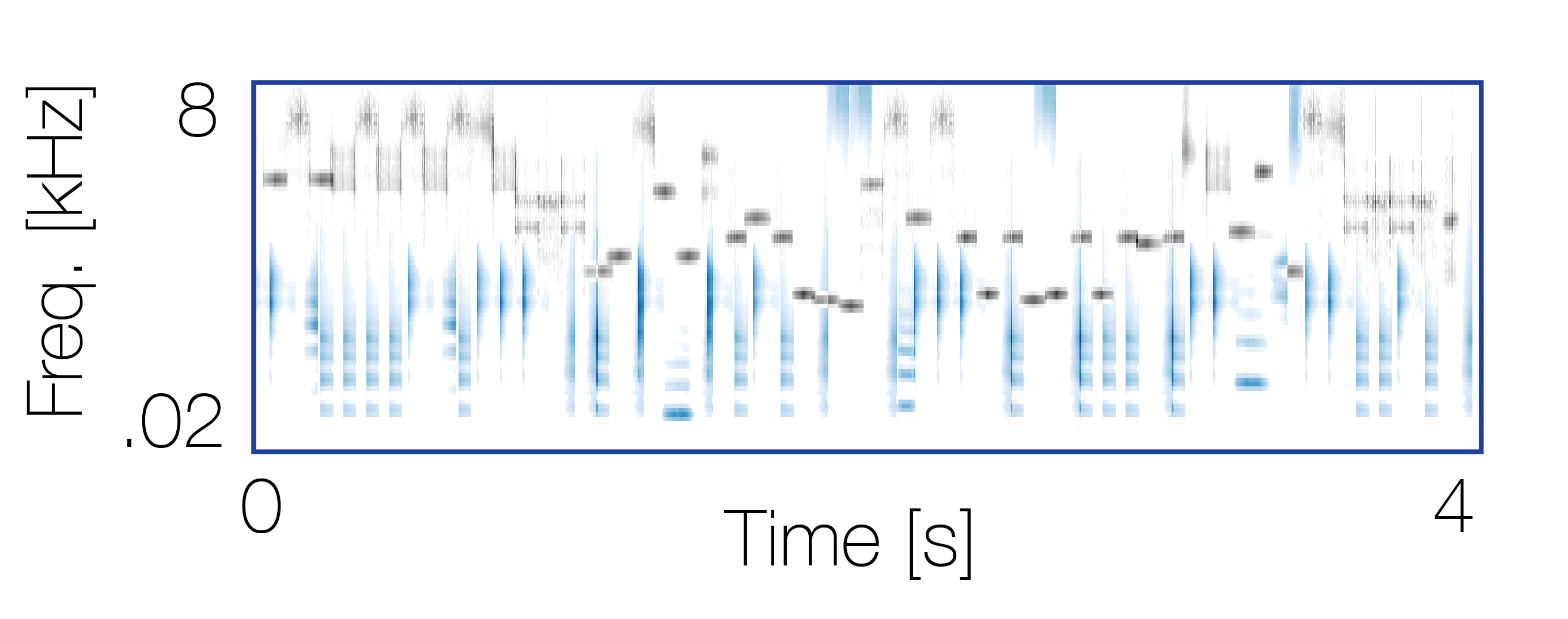
Reference sequence |
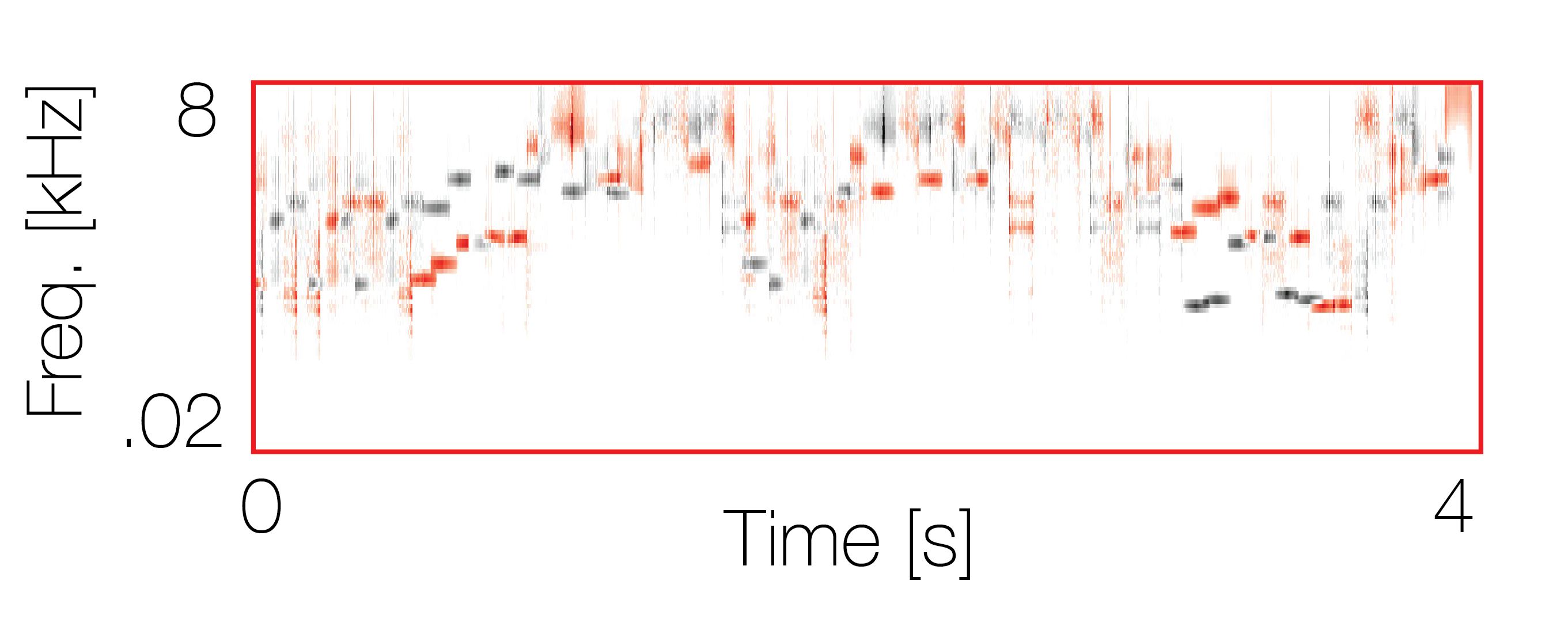
Mixture with a co-occurring sequence |
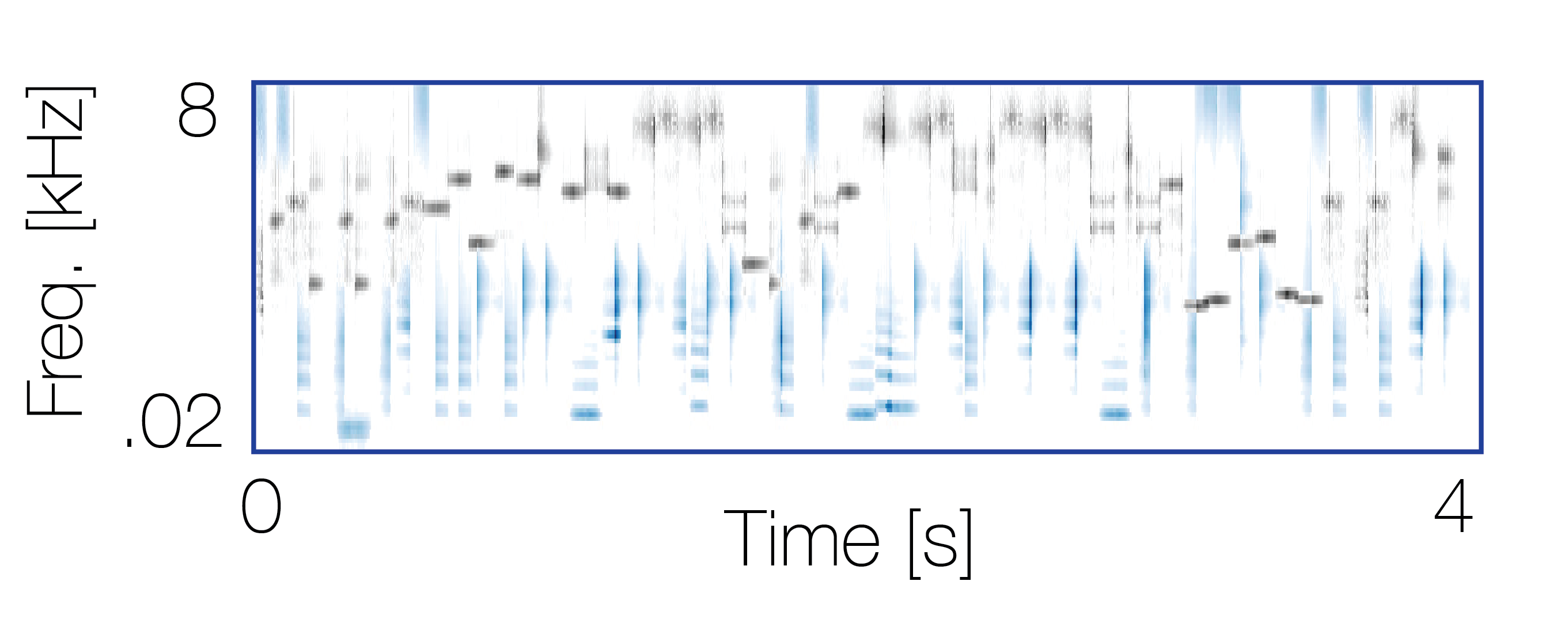
Mixture with a non-co-occurring sequence |
|
|
|
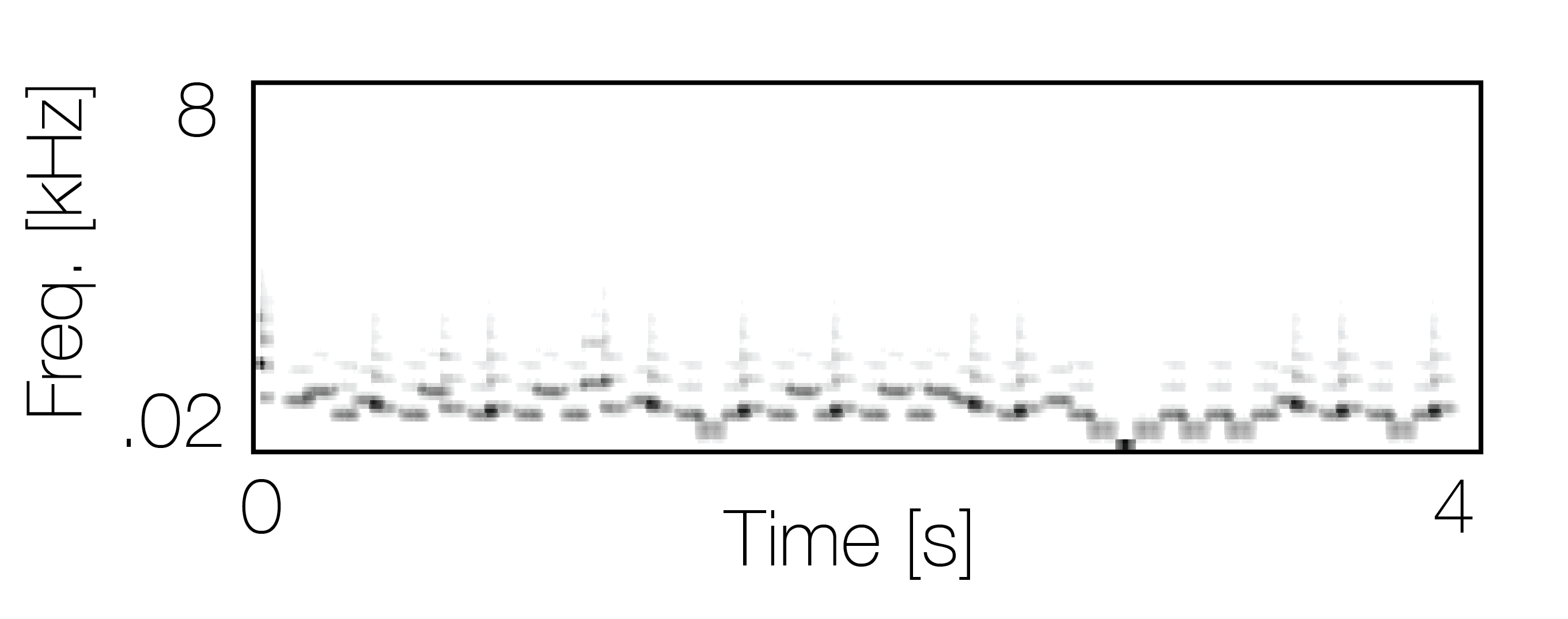
|
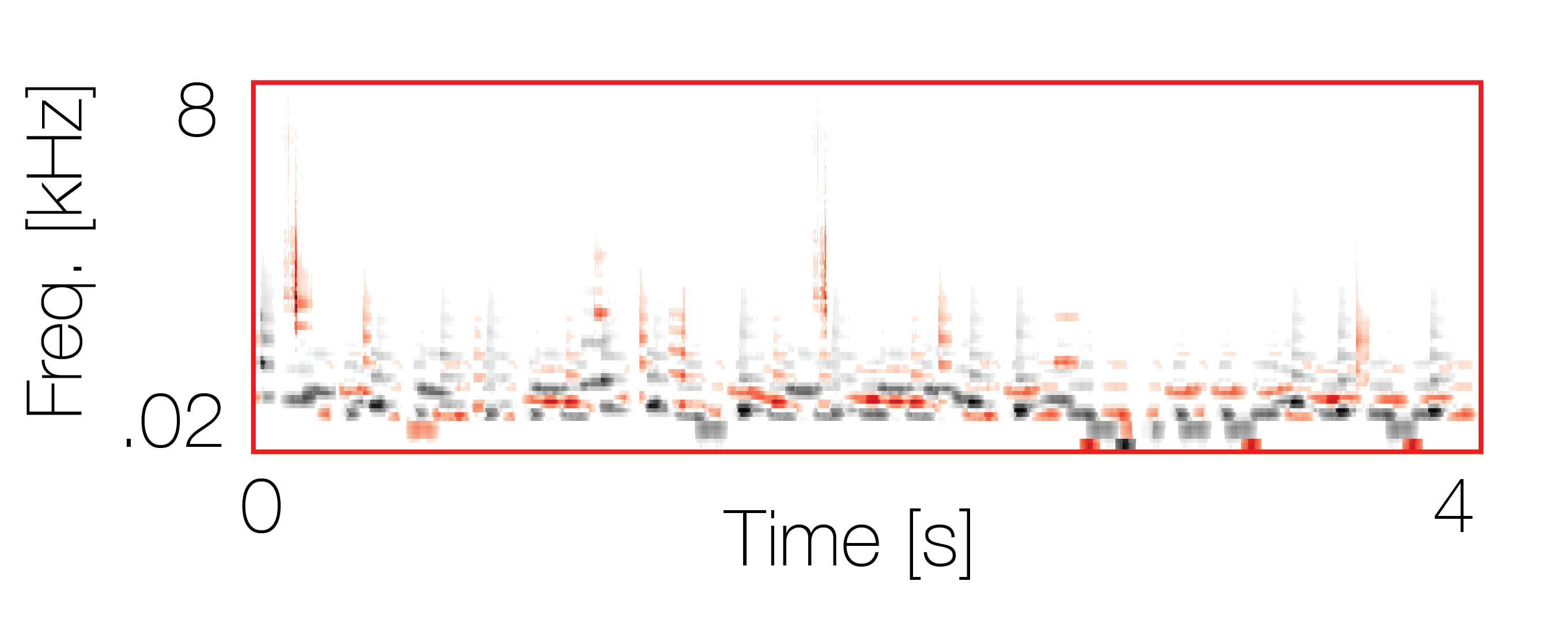
|
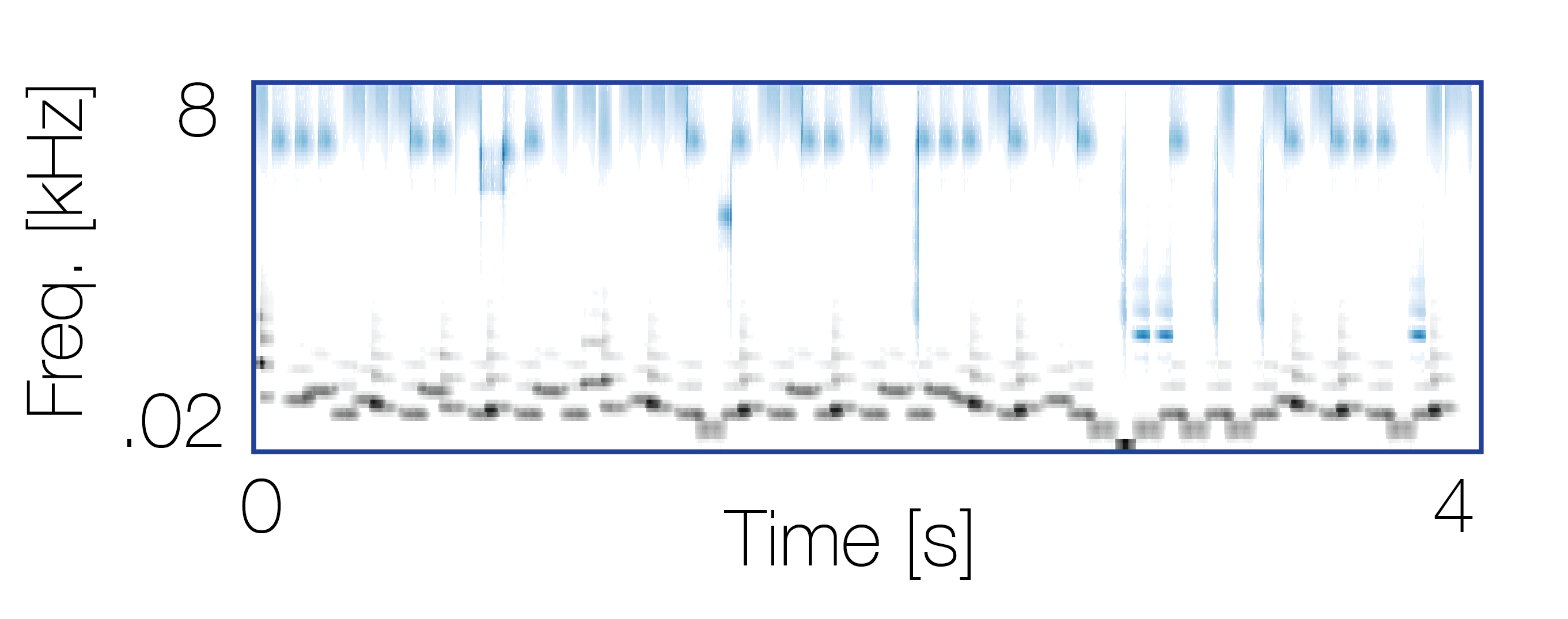
|
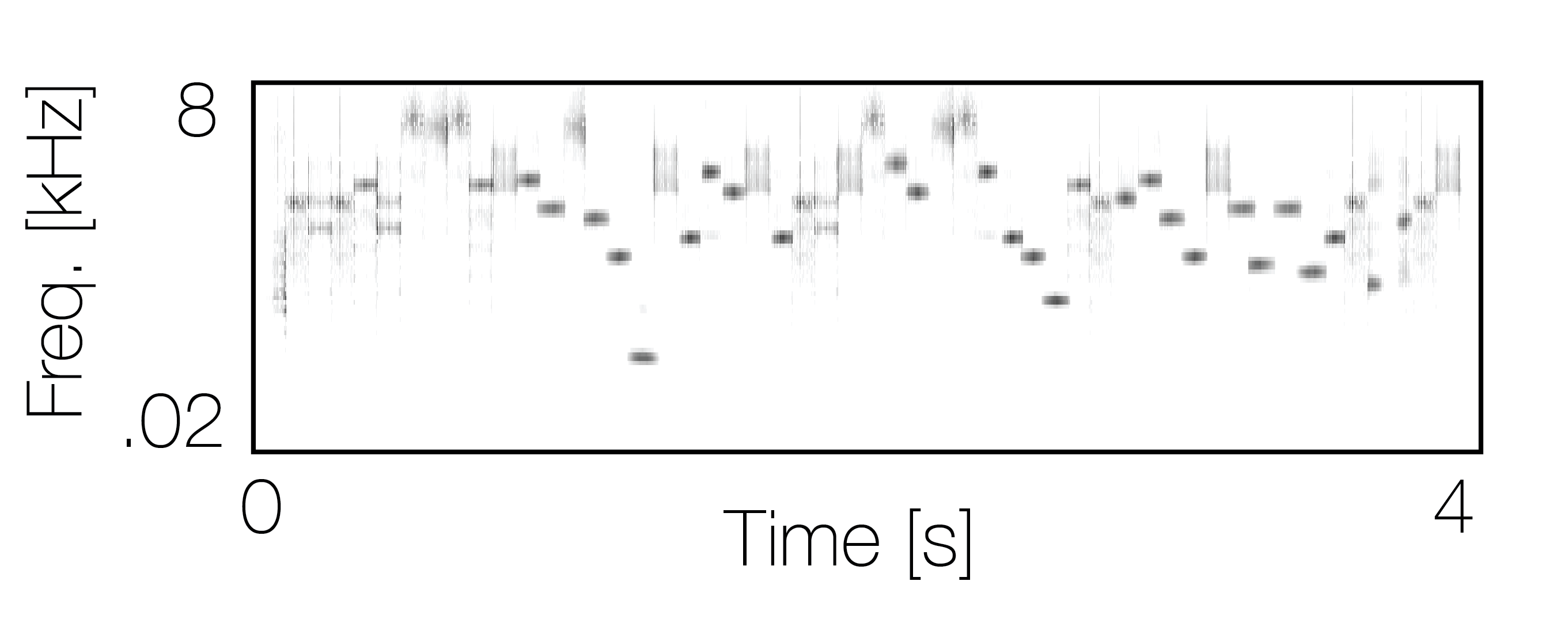
|
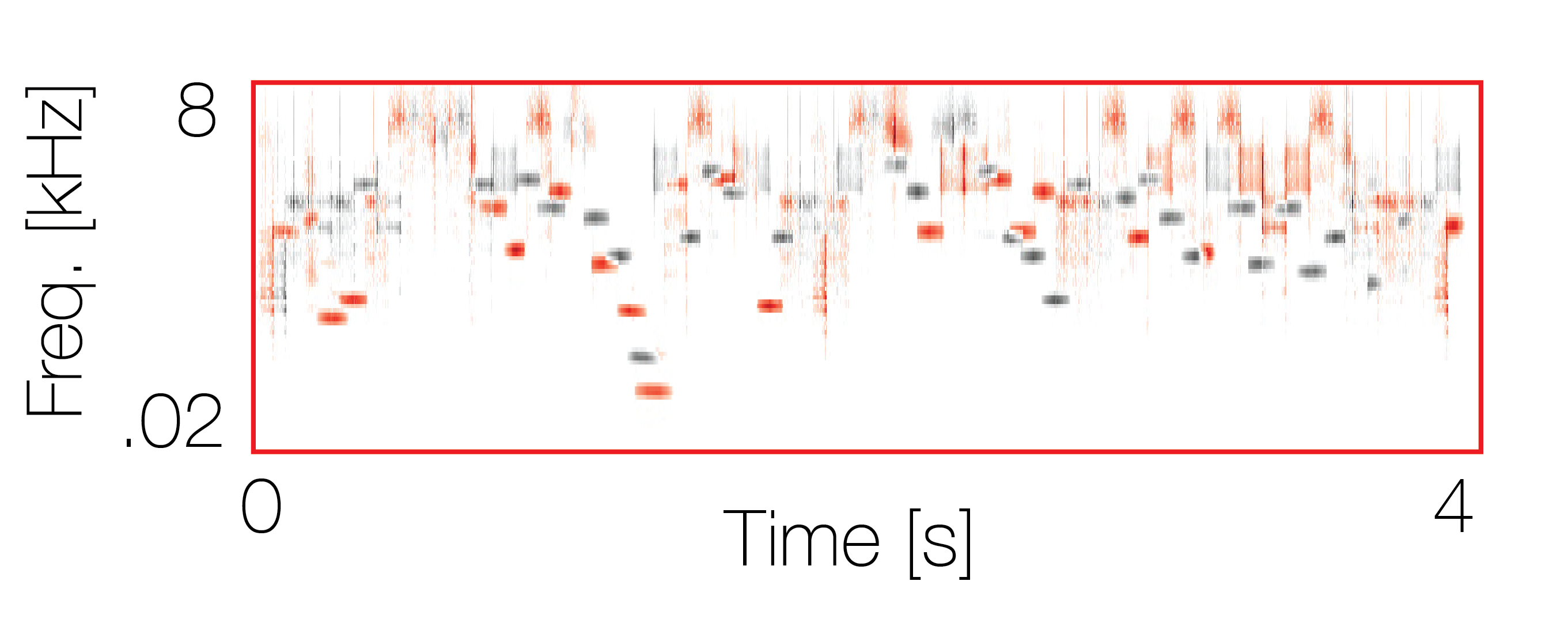
|
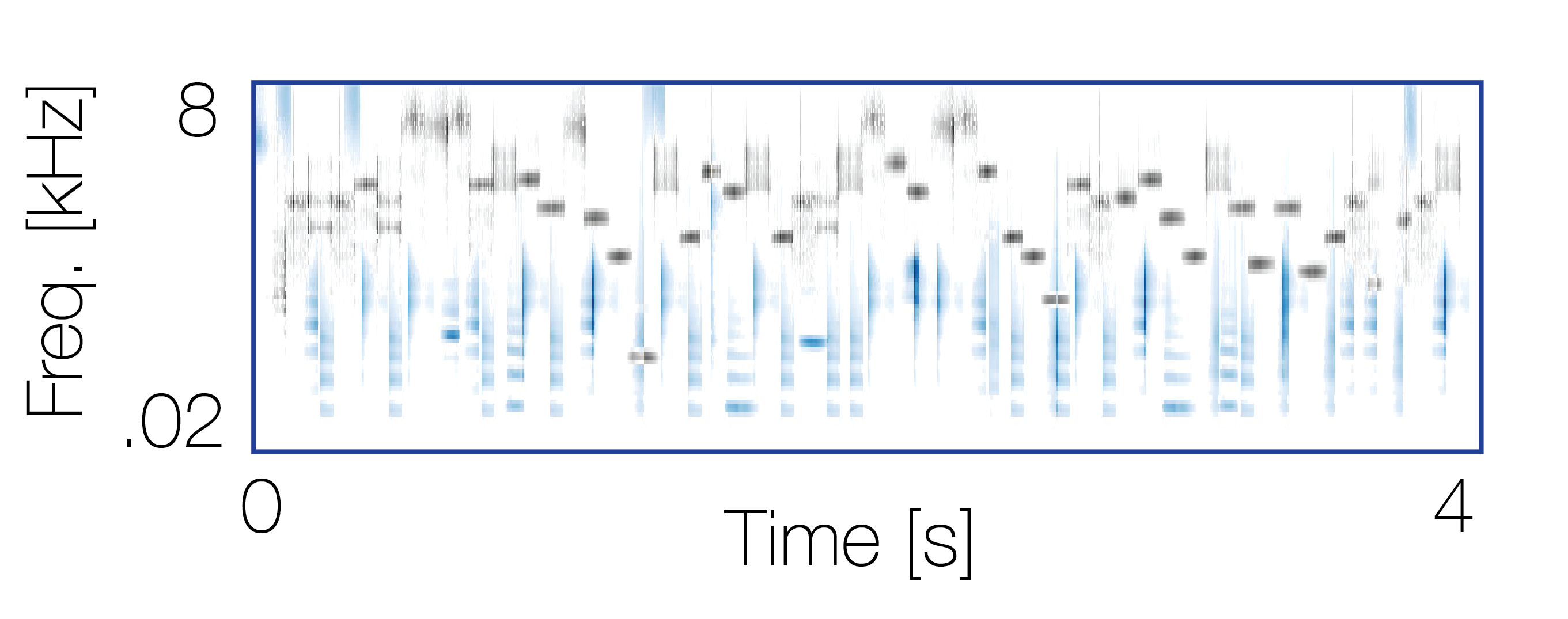
|
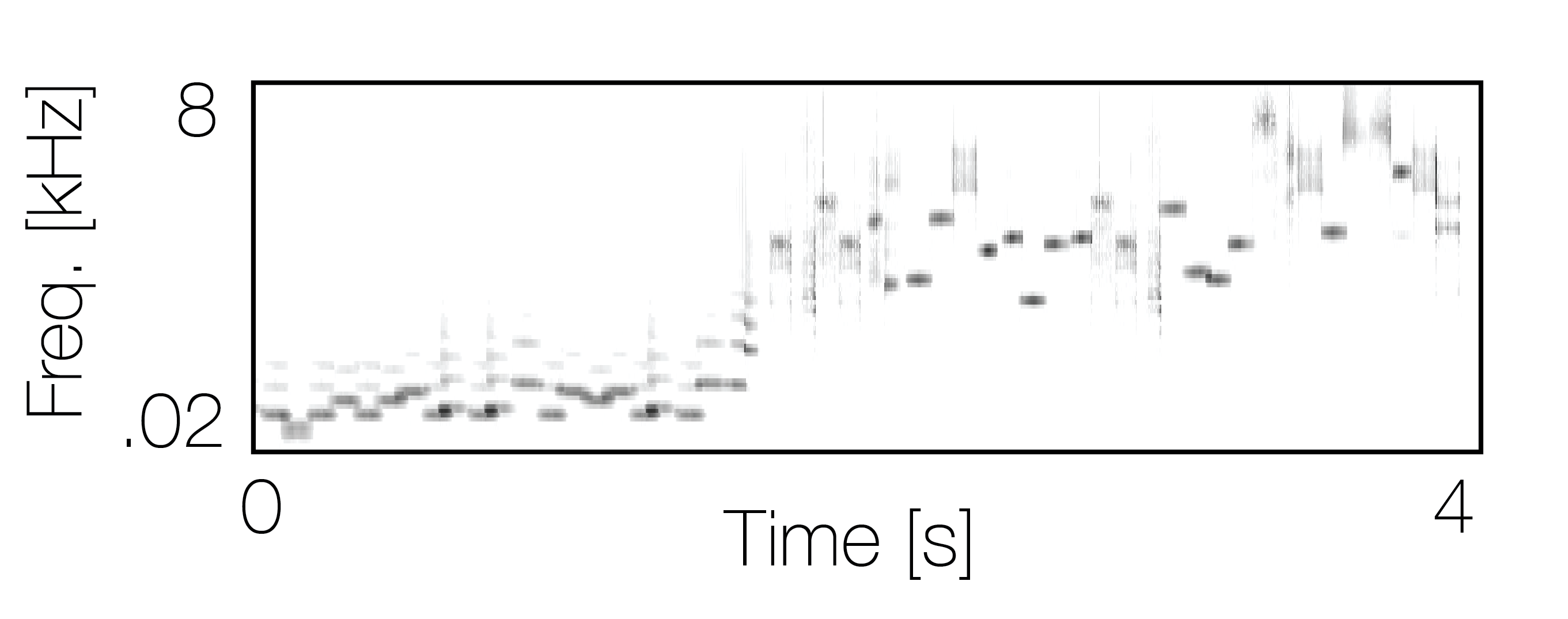
|
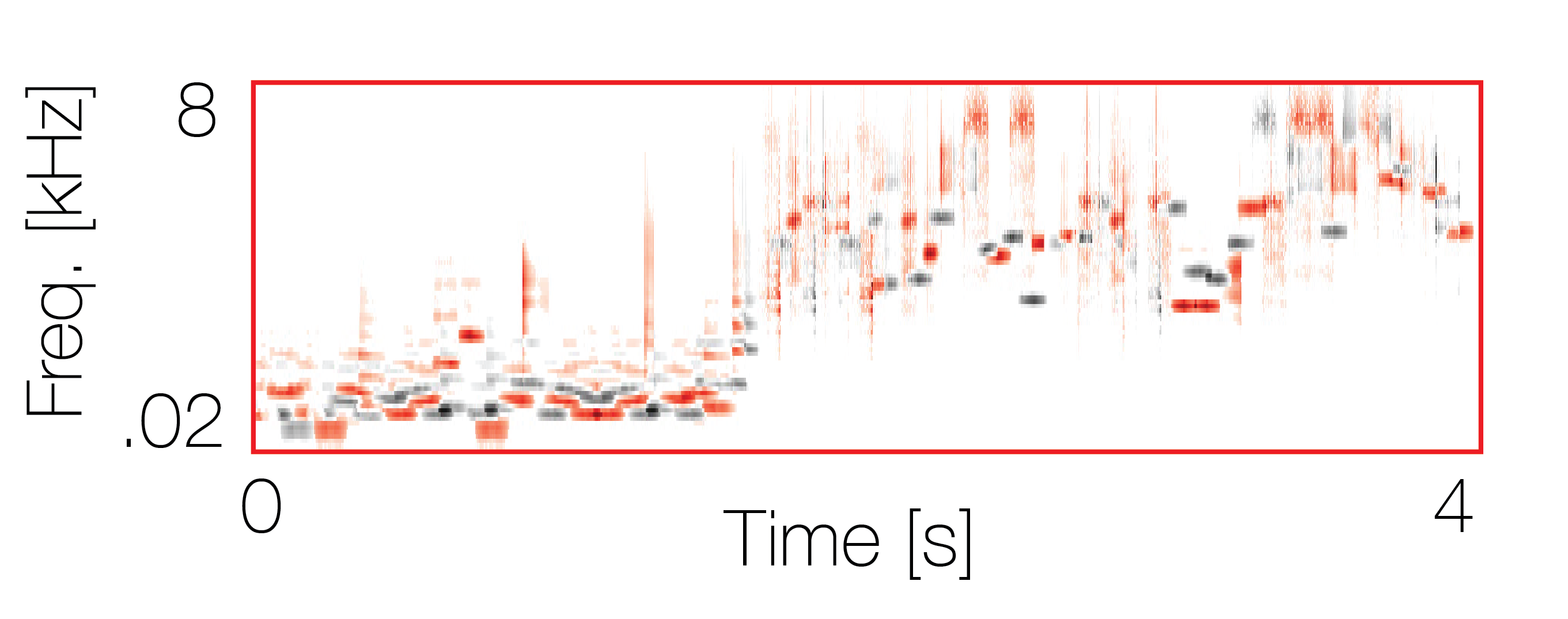
|
|

|
|
|