Source Repetition Stimuli Examples
These pages contain example stimuli from the paper "Recovering Sound Sources From Embedded Repetition" by McDermott, Wrobleski, and Oxenham (2011, PNAS). Headphones are recommended. Quicktime must be installed for the sounds to play.
**Please note - sound files make take a few seconds to load. If not all sounds load, please try refreshing the page.**
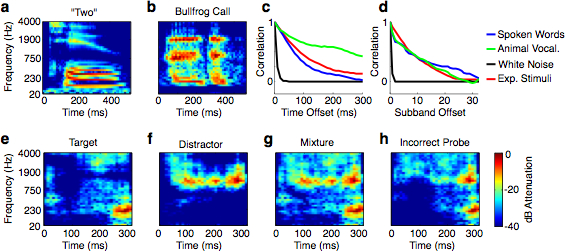
Fig. 1a-h. Stimulus generation. (a,b) Time-frequency decomposition of a spoken word and a bullfrog vocalization. (c,d) Correlation between nearby time-frequency cells as a function of their temporal (c) and spectral (d) separation, for spoken words, animal vocalizations, white noise, and experimental stimuli produced by our generative model. (e,f) Two example spectrograms generated by our model. Note that the energy occurs in clumps, as it does in the natural sound examples of a and b. (g) Spectrogram of the mixture of the sounds from d and e. (h) Spectrogram of an example incorrect probe sound, generated to be physically consistent with the mixture in (g).
Stimuli from Figure 1a-h:
| Fig. 1a | Fig. 1b | ||||||
| Fig. 1e | Fig. 1f | Fig. 1g | Fig. 1h |
Stimuli from Figure 1i Stimuli from Figure 2a Stimuli from Figure 2b Stimuli from Figure 3a
Stimuli from Figure 3b Stimuli from Figure 4 Stimuli from Figure S3a Stimuli from Figure S3b
Back