Model overview (Figure 2)
Click the cochleagrams in the figures to hear the corresponding sound.
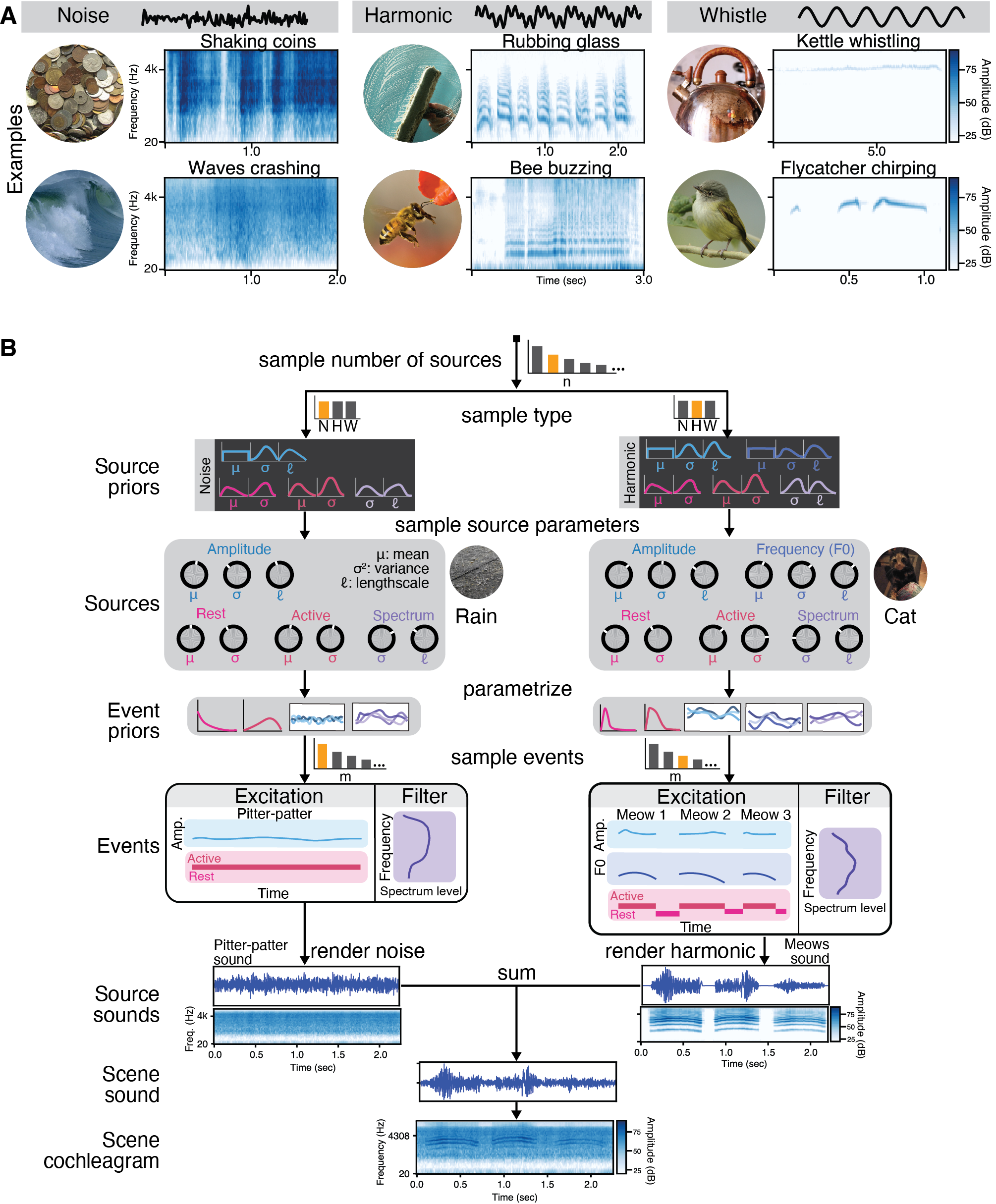
Generative model, illustrated with everyday recorded sound examples. A) The three sound types with natural sound examples. The examples demonstrate a variety of amplitude and frequency modulation, spectral shapes, and temporal patterns. B) A scene consists of any number of sources. Each source belongs to one sound type, which defines how the source is parametrized and rendered, and determines which source priors the source is sampled from. The sampled source parameters define distributions over events. A source can emit any number of events. Events consist of active and rest intervals, time-varying amplitude, and depending on the sound type, possibly a spectrum and/or time-varying fundamental frequency. Events are rendered into sound waveforms by combining an excitation and filter (cochleagrams of source sounds are shown only for visualization; they are not part of the generative model). The sounds generated by independent sources sum together to create a scene sound, which is transformed into a cochleagram for model inference. This scene cochleagram is the basis for the likelihood function. The number of sources, the type of sources, and the number of events can all change the dimensionality of the model, requiring it to be expressed as a probabilistic program.
Attributions
Sounds
- ftpalad (glass squeaking, source: Freesound, license: CC0)
- fst180081 (bee against window, source: Freesound, license: CC BY 4.0)
- shelbyshark (tea kettle boil then whistle, source: Freesound; license: CC0)
Images
- Michael Sander (coins, source: Wikimedia, license: CC BY-SA 4.0)
- Jon Sullivan (waves, source: Wikimedia, public domain)
- Gary L. Clark (yellow-olive flycatcher, source: Wikimedia; license: CC BY-SA 4.0)
- Louise Docker (bee, source: Wikimedia, license: CC BY 2.0)
- Aqua Mechanical (rubbing glass, source: Flickr, license: CC BY 2.0)
- maliciousfairy (tea kettle, source: Flickr, license: CC BY 2.0)
{kind=link}
{kind=link}
{kind=link}
{kind=link}