Analysis-by-synthesis (Figure 4)
There are no sounds in this figure.
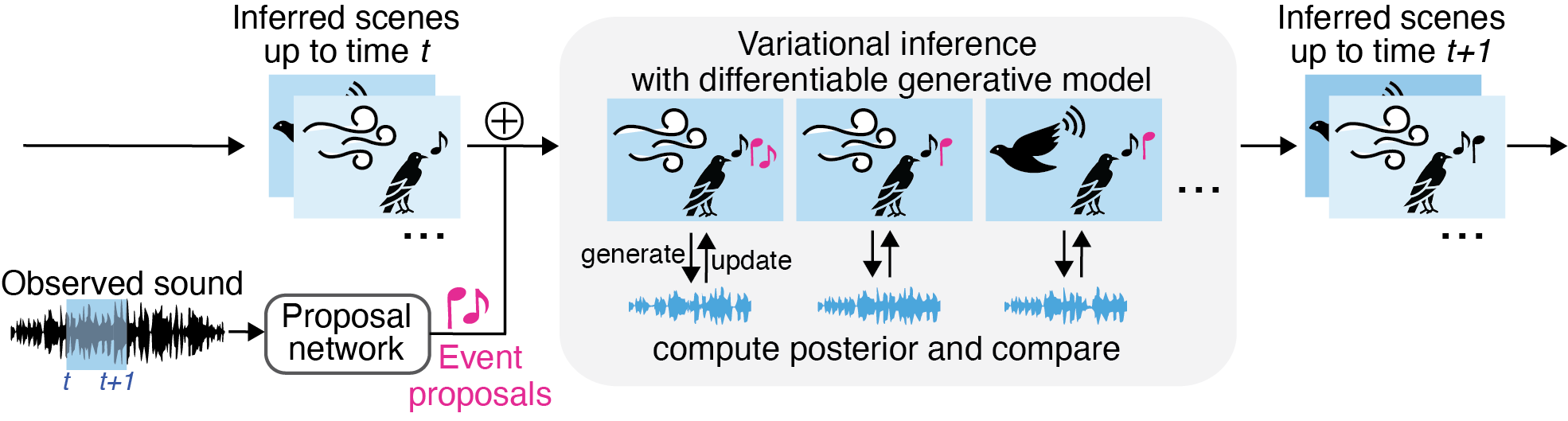
Analysis-by-synthesis inference overview. Given an observed sound, we infer a distribution over possible scenes that are likely to have generated the sound ("Inferred scenes up to time t"). This inference process proceeds sequentially, considering increasingly longer durations of audio, at each step combining a bottom-up "analysis" step with a top-down "synthesis" step. First, a deep neural network proposes events from the sound, and these events are combined into sources to create scene hypotheses (bottom-up). For each hypothesis, variational inference through the fully differentiable generative model is used to update the scene to maximize the prior and likelihood (top-down). Last, the probabilities are compared to find the best scenes given the observed sound.
Attributions
Images
- Mcnnr3 (Windy Hill, source: Wikipedia, license: CC BY 2.5)
- NPS/Patrick Myers (Mountain Bluebird, source: Flickr, public domain)
- iconixar (Bird icon, source: free with attribution by FlatIcon license)
- TheOtherKev (Crow flying, source: Pixabay, license: free without attribution by Pixabay Content license)
- Freepik (Dove of peace, source: FlatIcon, license: free with attribution by FlatIcon license)
{kind=link}