Impact sounds (Supplementary Figure 8)
Click the cochleagrams in the figures to hear the corresponding sound.
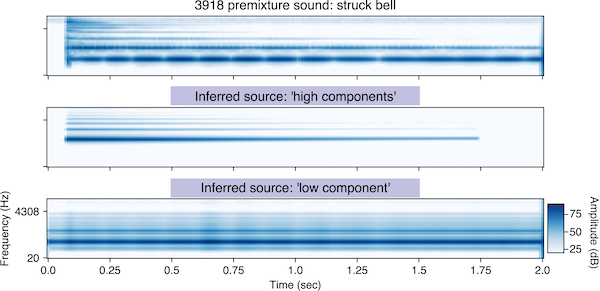
The following sound is obtained by summing the model inferences. Compare it to the pre-mixture clip above.
3918: struck bell