33rd Conference on Neural Information Processing Systems (NeurIPS 2019)
Links: Paper GitHub Poster Video
Audio Demos
Click on the cochleagram to hear the corresponding sound. Cochleagrams and audio are the 2 second sounds used for the perceptual experiment.
Figure 3: Audio Examples
Example audio for the Word Trained CNN, DeepSpeech, and the AudioSet VGGish embedding. For each model the audio becomes unrecognizable by the final layers. For DeepSpeech the metamers at the initial layers have audible artifacts due to the input representation (MFCCs).












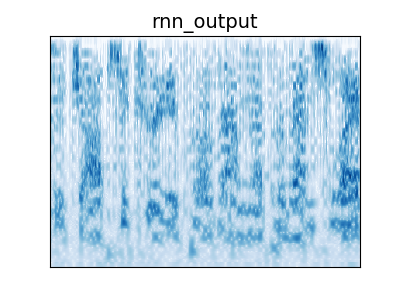
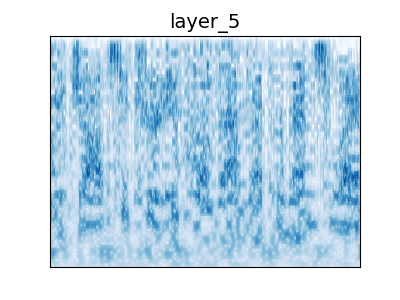
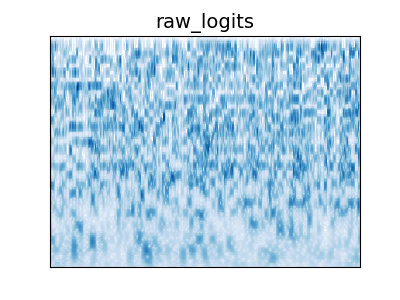





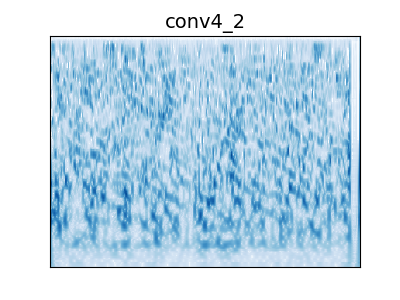

Figure 4: Audio Examples
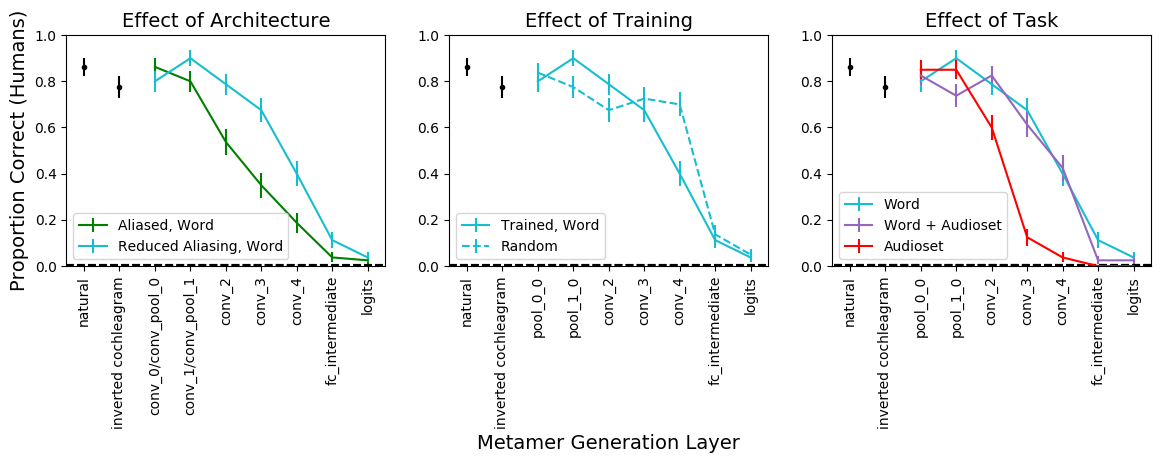
Example audio from audio behavioral experiment. Humans were better able to recognize metamers from the unaliased network than the aliased network. Metamers from the random aliased network were more recognizable than the trained network. The task that the network was trained on matters: metamers for the word trained network are more recognizable than the audioset trained network, while the word+audioset trained network is as recognizable as the word trained network.





































Links: Paper GitHub Poster Video
Audio Demos
Click on the cochleagram to hear the corresponding sound. Cochleagrams and audio are the 2 second sounds used for the perceptual experiment.
Figure 3: Audio Examples
Example audio for the Word Trained CNN, DeepSpeech, and the AudioSet VGGish embedding. For each model the audio becomes unrecognizable by the final layers. For DeepSpeech the metamers at the initial layers have audible artifacts due to the input representation (MFCCs).
Figure 4: Audio Examples
Example audio from audio behavioral experiment. Humans were better able to recognize metamers from the unaliased network than the aliased network. Metamers from the random aliased network were more recognizable than the trained network. The task that the network was trained on matters: metamers for the word trained network are more recognizable than the audioset trained network, while the word+audioset trained network is as recognizable as the word trained network.
Audio Demos
Click on the cochleagram to hear the corresponding sound. Cochleagrams and audio are the 2 second sounds used for the perceptual experiment.
Figure 3: Audio Examples
Example audio for the Word Trained CNN, DeepSpeech, and the AudioSet VGGish embedding. For each model the audio becomes unrecognizable by the final layers. For DeepSpeech the metamers at the initial layers have audible artifacts due to the input representation (MFCCs).
Figure 4: Audio Examples
Example audio from audio behavioral experiment. Humans were better able to recognize metamers from the unaliased network than the aliased network. Metamers from the random aliased network were more recognizable than the trained network. The task that the network was trained on matters: metamers for the word trained network are more recognizable than the audioset trained network, while the word+audioset trained network is as recognizable as the word trained network.
Figure 3: Audio Examples
Example audio for the Word Trained CNN, DeepSpeech, and the AudioSet VGGish embedding. For each model the audio becomes unrecognizable by the final layers. For DeepSpeech the metamers at the initial layers have audible artifacts due to the input representation (MFCCs).
Figure 4: Audio Examples
Example audio from audio behavioral experiment. Humans were better able to recognize metamers from the unaliased network than the aliased network. Metamers from the random aliased network were more recognizable than the trained network. The task that the network was trained on matters: metamers for the word trained network are more recognizable than the audioset trained network, while the word+audioset trained network is as recognizable as the word trained network.